|
| Appunti informatica |
|
|
| Appunti informatica |
|
| Visite: 1771 | Gradito: |
Leggi anche appunti:Il dispositivo 1TO4BusInterfaceIl dispositivo 1TO4BusInterface I campi relativi alla configurazione di un bus Protezione e SicurezzaProtezione e Sicurezza Si parla di protezione in presenza di meccanismi, messi DeadlockDeadlock Un insieme di processi si trova in una situazione di stallo o |
 |
 |
UNIX
Verso la fine degli anni '60 è in corso presso il MIT l'implementazione del sistema MULTICS, precursore degli attuali SO time-sharing. Il progetto appare da subito molto complesso e la AT&T, che lo segue presso il MIT, all'inizio degli anni '70 decide di realizzare un sistema più semplice: dapprima acquista il PDP-7 della Digital e da questo dopo non molto nasce la prima rudimentale versione di Unix. Tra il 1975 e il 1980 viene sviluppato anche il sistema Unix per il diffusissimo PDP-11 della Digital, nasce il linguaggio C, viene sviluppata una prima implementazione UNICS (Uniplexed Information and Computing Service) e parallelamente nel mondo universitario si inizia lo sviluppo della versione BSD (dal nome dell'università di Berkley). Negli anni '80 si consolida la divisione tra i sistemi Unix della AT&T (System V) e la versione BSD, prende piede il progetto ARPANET e tutti i sistemi Unix cominciano ad includere il supporto ai protocolli TCP/IP. Nel 1988 l'IEEE definisce lo standard POSIX di interfaccia tra SO e i programmi e vi aderiscono sia System V che BSD, si diffonde XENIX il primo UNIX per processori inferiori al 386, inoltre il MIT implementa X-Window, una interfaccia grafica a finestre per il sistema UNIX. Nel 1991 nasce la prima versione di Linux, SO creato da Linus Torvalds e derivato da UNIX.
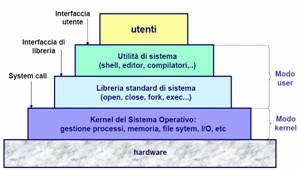
Unix è un SO multitasking (e non multithreading) e multiutente (time-sharing), progettato da programmatori per programmatori (SO "developer oriented"). I suoi punti di forza sono la robustezza (supporto alla cooperazione e condivisione ma in modo controllato), la flessibilità (un numero elevato di piccoli programmi di utilità combinabili in infiniti modi possono fornire un servizio oltremodo complesso), la portabilità (è il primo SO scritto quasi interamente in C, per cui la portabilità si ottiene con applicazioni scritte in C e come script di Shell) e chiaramente la multiutenza, gli svantaggi sono invece legati alla complessità della configurazione e all'interfaccia "shell-oriented". Naturalmente Unix ha un'architettura a livelli
 Al
boot del sistema parte un processo
unico detto Init il cui compito è
inizializzare il SO. Esso legge un file in cui sono elencati i terminali collegati al
sistema e crea per ciascuno di quelli attivi un processo nel cui contesto parte
il programma di login, che mostra a
video la parola login e poi si blocca
in attesa dell'autenticazione da parte dell'utente: una password viene
acquisita, crittata e confrontata con le password crittate conservate in un
apposito file delle password. Ad
autenticazione avvenuta il programma di
login termina caricando nel proprio contesto (viene eseguita una execv,
vedi più avanti) la Shell, che ciascun utente può personalizzare con il proprio JCL
definito tramite gli script di Unix:
la Shell mostra il prompt (carattere %) e si mette in attesa di un
comando, una volta ricevuto lo interpreta, crea un processo nel cui contesto
eseguire l'azione corrispondente; normalmente la Shell si sospende in attesa della terminazione del processo
lanciato (elaborazione foreground)
in corrispondenza della quale restituisce un exit code intero, ma se il comando digitato è seguito dal simbolo & allora (elaborazione background) la Shell
non si sospende e riprende subito la sua esecuzione non restituendo nulla (si possono lanciare più comandi % comando1 & comando 2 & comandoN dei quali solo
l'ultimo è foreground). La disconnessione
dell'utente può avvenire digitando Logout
oppure Ctrl-D.
Al
boot del sistema parte un processo
unico detto Init il cui compito è
inizializzare il SO. Esso legge un file in cui sono elencati i terminali collegati al
sistema e crea per ciascuno di quelli attivi un processo nel cui contesto parte
il programma di login, che mostra a
video la parola login e poi si blocca
in attesa dell'autenticazione da parte dell'utente: una password viene
acquisita, crittata e confrontata con le password crittate conservate in un
apposito file delle password. Ad
autenticazione avvenuta il programma di
login termina caricando nel proprio contesto (viene eseguita una execv,
vedi più avanti) la Shell, che ciascun utente può personalizzare con il proprio JCL
definito tramite gli script di Unix:
la Shell mostra il prompt (carattere %) e si mette in attesa di un
comando, una volta ricevuto lo interpreta, crea un processo nel cui contesto
eseguire l'azione corrispondente; normalmente la Shell si sospende in attesa della terminazione del processo
lanciato (elaborazione foreground)
in corrispondenza della quale restituisce un exit code intero, ma se il comando digitato è seguito dal simbolo & allora (elaborazione background) la Shell
non si sospende e riprende subito la sua esecuzione non restituendo nulla (si possono lanciare più comandi % comando1 & comando 2 & comandoN dei quali solo
l'ultimo è foreground). La disconnessione
dell'utente può avvenire digitando Logout
oppure Ctrl-D.
Ad ogni processo viene associato un intero positivo detto PID, assegnato automaticamente all'atto della creazione che avviene sempre ad opera di un altro processo padre identificato a sua volta dal PPID (parent PID). Più processi (che per esempio condividono l'accesso ad uno stesso file) possono essere dichiarati appartenenti ad uno stesso gruppo, indicato dal PGID (process group ID): fanno normalmente parte dello stesso gruppo i processi creati sotto la stessa Shell.
Ogni processo è costituito da 3 segmenti logici in ciascuno dei quali gli indirizzi sono contigui: il segmento testo (codice), il segmento dati e il segmento stack. Il segmento testo è a sola lettura (per evitare che ci siano programmi che si automodifichino) e può essere condiviso da più processi ottimizzando l'occupazione della memoria: la Shared Text Segment Table o STST è una tabella contenente i riferimenti ai segmenti testo condivisi, ovvero per ciascuno di essi conserva informazioni utili alla localizzazione su disco, il numero di processi che lo condividono e puntatori ai descrittori di questi processi; tutti i processi che condividono lo stesso segmento testo contengono nei rispettivi descrittori un puntatore alla stessa entry della STST. Il segmento dati è inoltre diviso in due parti, dati inizializzati e dati non inizializzati (BSS).
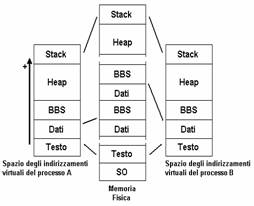
Nello spazio di indirizzamento di ciascun processo, dal basso verso l'alto, trovano posto nell'ordine il testo, i dati, i BSS e poi spazio vuoto fino al limite dello stack, posto in testa allo spazio di indirizzamento: dati due processi che condividono il testo, nella memoria fisica, dal basso verso l'altro, troviamo nell'ordine il SO, il testo condiviso, dati e BSS del primo processo, dati e BSS del secondo processo e poi lo stack.
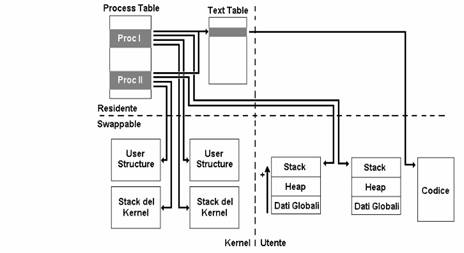
Alla creazione di un processo corrisponde la creazione del suo descrittore di processo (PCB). Una particolarità di Unix rispetto ad altri SO è che il PCB non ha una struttura monolitica ma è suddiviso in due parti, la prima è la entry nella Process Table o Tabella dei Descrittori di Processo, accoppiata al PID del processo, la seconda è contenuta in una struttura dati ausiliaria chiamata User Block o User Structure o US (accessibile solo al kernel) puntata dalla prima: a fronte di un gran numero di informazioni necessarie a Unix per gestire un processo mentre è Running, solo una piccola parte di esse è indispensabile quando non lo è, per cui le restanti (contenute appunto nel US) vengono swappate insieme al processo, precisamente in testa al segmento testo. La entry della tabella dei descrittori contiene, oltre al PID, puntatori a processi parenti (padre, figli e parenti remoti usati di frequente in particolare PPID, PGID) e identificatori dell'utente e gruppo che ha lanciato il processo (UID e GID), parametri di schedulazione (priorità, tempo di CPU speso di recente, tempo di attesa recente), informazioni di localizzazione dell'immagine in memoria (dipendenti dalla tecnica di gestione della memoria fisica utilizzata, quindi puntatori ai 3 segmenti o puntatore alla PTE), informazioni di localizzazione della sua immagine su disco (solo quando è swappato), la maschera dei segnali, puntatori in avanti e indietro (per il linking alle code di cui questo PCB farà parte), informazioni varie (stato del processo, evento che attende, terminale corrente, directory corrente). La US viceversa contiene copia dei Registri della CPU (salvati al momento del context switch), la tabella dei descittori dei file aperti, informazioni di accounting o addebito (tempo complessivo di CPU speso, tempo massimo di CPU spendibile, dimensione massima dello stack, numero massimo di pagine, ) e lo Stack del Kernel. L'immagine di un processo è costituita dai 3 segmenti, dalla entry della Process Table, dalla entry della Text Table, dall'US e dal Kernel Stack.
 Il
processo entra nel sistema nello stato Created/New
quando il padre lo crea tramite la chiamata a fork. Se c'è sufficiente spazio in memoria esso diventa Ready to Run in Memory. Quando lo
scheduler lo seleziona passa nello stato Kernel
Running (dove termina la sua parte di fork) e da lì può passare in stato User Running (in cui agisce normalmente). La transizione User
Running Kernel Running avviene a seguito di una SVC o interrupt (per esempio di clock) e dopo
aver eseguito la ISR corrispondente il Kernel potrebbe schedulare un altro
processo mandando quello corrente nello stato Preempted: lo stato Preempted
enfatizza il fatto che i processi Unix possono essere prelazionati solo quando
tornano da modo Kernel a modo Utente. Se durante l'esecuzione in
modo Kernel (ad esempio durante una SVC) il processo deve eseguire operazioni di I/O esso passa nello
stato Asleep in Memory da cui verrà
al momento opportuno risvegliato per passare nello stato Ready to Run. Gli stati con etichetta Swapped corrispondono a condizioni in cui il processo non è più
fisicamente in memoria centrale.
Il
processo entra nel sistema nello stato Created/New
quando il padre lo crea tramite la chiamata a fork. Se c'è sufficiente spazio in memoria esso diventa Ready to Run in Memory. Quando lo
scheduler lo seleziona passa nello stato Kernel
Running (dove termina la sua parte di fork) e da lì può passare in stato User Running (in cui agisce normalmente). La transizione User
Running Kernel Running avviene a seguito di una SVC o interrupt (per esempio di clock) e dopo
aver eseguito la ISR corrispondente il Kernel potrebbe schedulare un altro
processo mandando quello corrente nello stato Preempted: lo stato Preempted
enfatizza il fatto che i processi Unix possono essere prelazionati solo quando
tornano da modo Kernel a modo Utente. Se durante l'esecuzione in
modo Kernel (ad esempio durante una SVC) il processo deve eseguire operazioni di I/O esso passa nello
stato Asleep in Memory da cui verrà
al momento opportuno risvegliato per passare nello stato Ready to Run. Gli stati con etichetta Swapped corrispondono a condizioni in cui il processo non è più
fisicamente in memoria centrale.
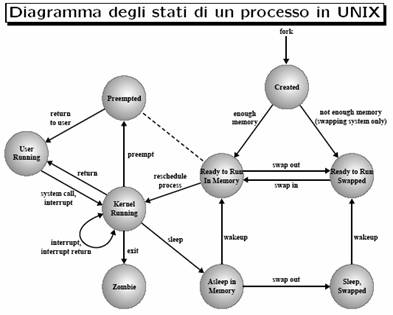
Più sinteticamente gli stati di un processo Unix sono: Ready (pronto per essere eseguito), Running (in esecuzione su una CPU del sistema), Sleeping (in attesa di un evento), Swapped (parte del processo é stato trasferito su disco, per liberare la memoria per altri processi), Terminated (terminato, il segnale SIGCHLD è stato inviato al processo padre), Zombie (terminato, ma il padre non ha raccolto il segnale SIGCHLD, per cui il processo mantiene ancora allocate delle risorse).
I processi Unix possono operare in User Mode e Kernel Mode. La doppia modalità permette al kernel di lavorare nel contesto di un processo utente senza dover creare nuovi processi kernel: con questo meccanismo un processo in Kernel Mode può svolgere funzioni collegate ad altri processi e non necessariamente al processo che momentaneamente "ospita" il kernel. Alla partenza del sistema il codice del Kernel viene caricato in memoria centrale, insieme alle strutture dati (tabelle) necessarie a mappare gli indirizzi virtuali kernel in indirizzi fisici. Un processo in esecuzione in User Mode non può accedere allo spazio di indirizzi del Kernel, tuttavia quando passa in esecuzione in Kernel Mode (SVC, ISR, ) questo vincolo decade e si può quindi eseguire il codice kernel nel contesto del processo utente.
Il contesto di un processo è costituito dal contesto utente (codice, dati, stack) e dal contesto kernel (entry nella Process Table, US e Kernel Stack). Il Kernel Stack è organizzato con un numero di livelli dipendente dal numero di livelli di interrupt ammessi nel sistema, ad esempio se il sistema gestisce interrupt software, interrupt di terminali, di dischi, di altre periferiche e di clock avremo al più 7 livelli di contesto: Livello 0 User, Livello 1 Chiamate di sistema, Livelli 2-6 Interrupt (l'ordine dipende dalla priorità associata alle interrupt). Naturalmente, l'algoritmo del kernel per la gestione di un interrupt prevede il salvataggio del contesto del processo corrente, la determinazione della fonte dell'interrupt, il recupero dal vettore degli interrupt dell'indirizzo della ISR corrispondente, l'invocazione della ISR e dopo la sua esecuzione il recupero del livello di contesto precedente. Schematicamente, a titolo esemplificativo: un processo attivo in User Mode esegue una SVC, il Kernel salva il suo contesto (registri della CPU ed entry nella Process Table con puntatori annessi) nel livello 0 e crea il contesto di livello 1, in Kernel Mode; la CPU riceve e processa (per esempio) un interrupt di disco, sicché il Kernel salva il contesto di livello 1 (registri della CPU e Kernel Stack) e crea il contesto di livello 2 in cui esegue la ISR di gestione del disco; la CPU riceve e processa (per esempio) un interrupt di clock, sicché salva il contesto di livello 2 (registri della CPU e Kernel Stack per la ISR del disco) e crea il contesto di livello 3 in cui esegue la ISR di gestione del clock; la routine di gestione del clock termina e il Kernel recupera il livello di contesto 2, e così via Si noti che tutti questi passi vengono fatti sempre all'interno dello stesso processo, ciò che cambia è solo la sua parte dinamica di contesto: in pratica la gestione delle trap/interrupt si basa su una sorta di context switch all'interno del processo, ovvero il controllo non passa ad un altro processo ma viene semplicemente salvata la parte corrente del contesto dinamico del processo sempre restando all'interno del processo stesso. In generale il Kernel vieta context switch arbitrari per mantenere la consistenza delle sue strutture dati, per cui il controllo può passare da un processo ad un altro solo in quattro possibili scenari, ovvero quando un processo si sospende, quando termina, quando torna in User Mode da una SVC ma non è più il processo a più alta priorità, quando torna in User Mode dopo che il Kernel ha terminato la gestione di un'interrupt e non è più il processo a più alta priorità: in tutti questi casi il Kernel lascia la decisione di quale sia il processo da eseguire allo Scheduler.
Si noti che esistono delle SVC che possono essere invocate solo da un utente privilegiato, il superuser (un amministratore del sistema), per esempio per accedere ai blocchi iniziali del disco. Tuttavia, a titolo d'esempio, accedere al file delle login per vedere il proprietario di un certo file, pur essendo consentita solo al superuser, potrebbe essere un'operazione utile anche ad un utente normale: in Unix questo problema si risolve settando il bit set-uid presente nel descrittore del file da condividere in modo che l'utente normale possa accedervi come se fosse il superuser (e naturalmente la tecnica vale anche per due utenti normali
L'algoritmo di scheduling adottato da Unix non è un RR semplice, bensì un multilevel feedback con RR su più code, con le code dei processi utente a priorità 3, 2, 1, 0 e poi code a priorità negative via via decrescenti corrispondenti all'esecuzione del processo in Kernel Mode. In User Mode la priorità di un processo cambia dinamicamente: nel descrittore di ogni processo sono presenti due contatori, uno del tempo globale d'uso della CPU e l'altro del tempo d'uso parziale, ambedue incrementati da un daemon ogni 20ms per tenere nota del tempo di Running in termini di time slice di cui il processo ha usufruito; un altro daemon scatta ogni secondo e dimezza il contatore parziale, indipendentemente dal fatto che il processo sia Running o meno; quando il processo torna Ready, la sua priorità è implicitamente rappresentata da questo secondo contatore, nel senso che se il valore memorizzato è alto significa che gli ultimi CPU burst sono stati lunghi e al processo si assegna una priorità più bassa, viceversa se è basso significa che ha avuto pochi incrementi e/o molti dimezzamenti, mediamente i suoi CPU burst sono stati brevi e quindi gli si assegna una priorità più alta; in realtà la priorità così calcolata costituisce solo una aliquota di priorità da sommare alla priorità statica assegnata inizialmente al processo (che non può essere negativa, al massimo nulla). Questo meccanismo di ricalcolo della priorità, che cerca di approssimare l'algoritmo ottimale Short Next CPU Burst First, si definisce di aging (invecchiamento) e consente a processi che rimangono troppo in attesa e a rischio starvation di aumentare col tempo la loro priorità.
I meccanismi con cui i 3 segmenti logici (testo, dati e stack) di ciascun processo vengono caricati in memoria fisica dipendono dalla tecnica di gestione della memoria adottata. Quando Unix girava su macchine PDP-11, con limitata capacità di memoria (tipicamente 64K), adottava una tecnica di allocazione contigua nell'ambito di una strategia di gestione della memoria a partizioni variabili, laddove affinchè un processo potesse essere Running era necessario che risiedesse totalmente in memoria fisica (assenza di memoria virtuale). Il livello di multiprogrammazione del sistema veniva gestito automaticamente da un ottimo swapper, un daemon attivato tipicamente ogni 4 secondi che cercava di portare i processi Ready dal disco alla RAM, adottando una strategia Best Fit. Lo swapping out veniva applicato ad un processo se chiedeva memoria per un processo figlio (fork), se cercava di espandere il suo segmento dati o il suo stack andava in overflow, inoltre in assenza di spazio libero per altri processi venivano swappato prima di tutto i processi bloccati e poi eventualmente anche i processi Ready, e in ambedue le categorie la scelta del processo vittima veniva eseguita sulla base della priorità, del tempo di permanenza in memoria e di utilizzo della CPU. Per evitare che in assenza reiterata di spazio libero sufficiente lo swapper portasse via dalla RAM anche i processi Ready che erano stati appena caricati in essa dallo stesso swapper, entrando così in un loop (trashing), era previsto che un processo non potesse essere swappato dalla RAM se non dopo almeno 2 secondi e che, anche quando non fosse stato più in grado di trasferire su disco alcun processo pur senza aver liberato la memoria richiesta per i processi Ready, lo swapper dovesse terminare ugualmente (terminazione anomala). Questo modo di gestire la memoria è (da almeno 10 anni) superato, e Unix adotta attualmente una tecnica di gestione della memoria virtuale basata sulla paginazione e algoritmo di sostituzione globale con seconda chance, nell'ambito di una strategia a pagine vuote. La memoria è suddivisa in frame, lo stato di ogni frame è descritto da una entry (16B) di una tabella detta core map (1KB) residente in memoria, e tiene nota dello stato del frame (libero o occupato), l'indirizzo su disco dove viene swappato, la posizione logica all'interno di un segmento e il tipo del segmento, la sua identità (per resuscitarlo senza Swap In laddove non sia stato ancora sovrascritto) ed eventualmente il suo stato di interlock. Un pagedaemon, attivato ogni 250ms, controlla che le pagine libere siano almeno pari a Min e in caso contrario le riporta ad un valore Min; se ci sono troppi page fault, lo swapper libera tutti i frame occupati da processi non attivi da più di 20s, iniziando da quelli inattivi da più tempo; si noti che lo swapper non applica alcun algoritmo della seconda chance come il pagedaemon, si limita semplicemente a buttare fuori dalla RAM i processi inattivi da più tempo.
Il File System di Unix è stato analizzato a più riprese in precedenza.
Alcuni dei più comuni comandi in linea di UNIX
MAN [nome comando] mostra help in linea del comando
WHO verifica gli utenti che hanno fatto login e dà informazioni sull'utente corrente
LAST permette di conoscere l'ultimo login fatto e da quale macchina
PASSWD permette di cambiare la password
PWD visualizza la directory corrente col pathname
MKDIR crea nuova directory
RMDIR rimuove una directory
CHDIR, CD cambia la directory corrente (l'utente parte inizialmente dalla propria home directory sotto USR, la navigazione e l'indicazine dei path è identica al DOS, compresi i caratteri speciali * e ?, tranne che per l'uso dello "/" anzichè ""
LS corrisponde al DIR del DOS
FIND cerca un file
LN [nome1 nome2] crea un link a nome1 assegnandogli il nome logico nome2
MV [name target] sposta name sotto target (se è una directory) oppure sovrascrivendo target (se è un file
CP copia un file (stessa sintassi di MV
RM rimuove un file
DU verifica lo spazio occupato da un file
TOUCH modifica data/ora dell'ultimo accesso ad un file
CHMOD imposta i permessi di accesso (Read, Write, Execute) di un file per l'Utente, il Gruppo e tutti gli altri
#include <sys/types.h>
typedef pid_t int;
#include <errno.h>
int errno;
Quando si verifica un errore tale variabile viene settata al codice corrispondente a quell'errore.
#include <unistd.h>
pid_t fork(void);
Il processo corrente è detto processo padre o parent process, mentre il processo generato dalla chiamata della fork() è detto processo figlio o child process: ambedue i processi condividono lo stesso codice ma vengono eseguiti in concorrenza fra loro, assieme al resto dei processi elaborati sul sistema in oggetto e normalmente padre e figlio eseguono istruzioni differenti. Il child process eredita i file aperti dal parent process, e questi possono costituire un mezzo di interazione fra i due processi. Diversamente i dati, lo stack e l'ambiente del parent process vengono duplicati per il nuovo processo e posti in un'area di memoria a lui riservata e non visibile dagli altri processi, parent compreso. La fork() restituisce al parent un valore negativo in caso di errore (il child process non viene generato) o un valore positivo corrispondente al pid del child; viceversa la fork() restituisce al child sempre il valore 0.
Per i processi creati con una fork è possibile che si verifichi uno di due possibili casi. Se il processo padre termina prima del processo figlio, il figlio rimane "orfano" del padre e viene adottato dal processo Init (per definizione padre di tutti i processi). Se viceversa il figlio termina prima del padre, esso viene definito defunto o zombie finchè il padre non rileva la sua terminazione (attraverso la funzione wait() che intercetta il segnale di SIGCHLD) oppure finchè il padre non termina: in questo caso sarà il processo adottivo, cioè Init, a rilevarne la terminazione. In condizioni normali, dunque, il padre deve rilevare la terminazione del figlio così che quest'utlimo possa rilasciare ogni risorsa impegnata.
int execl(const char* path, const char* arg0, , const char* argN, (char*)0);
int execv(const char* path, char const* argv[]);
int execlp(const char* file, const char* arg0, , const char* argN, (char*)0);
int execvp(const char* file, const char* argv[]);
int execle(const char* path, const char* arg0, , (char*)0, const char* envp[]);
int execve(const char* path, char* const argv[], const char* envp[]);
Le funzioni del gruppo exec sono in grado di sostituire il processo corrente con un altro processo, mentre il pid e il ppid rimangono invariati. In pratica si ha una trasformazione del processo: il processo che esegue la exec carica il programma o lo script indicato fra gli argomenti della funzione chiamata e lo manda in esecuzione in sostituzione del processo attuale; non é previsto nessun tipo di ritorno al vecchio processo se non nel caso che non sia possibile avviare il nuovo processo. Path indica il path del programma eseguibile, arg0 è il nome di tale programma e da arg1 in poi ci sono gli argomenti/parametri passati al nuovo programma; in alternativa tutti gli argomenti, da arg0 ad argN, possono essere inclusi nel vettore argv passato al loro posto; envp è un vettore contenente tutte le variabili d'ambiente.
unsigned int alarm(unsigned int sec);
La funzione alarm() causa dopo un certo numero di secondi la generazione da parte del sistema di un segnale di SIGALRM diretto proprio al processo chiamante.
void _exit(int status);
La funzione _exit() termina il processo che ha invocato la funzione ogni descrittore di file aperto dal processo chiamante viene chiuso (i files condivisi con altri processi invece non vengono chiusi), ciascun figlio del processo corrente viene ereditato dal processo 1 (Init, il padre di tutti i processi) sopravvivendo alla scomparsa del processo padre, se il processo era il capostipite di un gruppo di processi (suo PID uguale al suo PGID) a tutti i processi del gruppo viene inviato un segnale di HANG UP (ovvero di terminazione forzata), al padre del processo corrente viene inviato il segnale SIGCHLD che indica il termine del processo in esecuzione e, infine, il valore di status viene restituito al padre del processo corrente che lo può rilevare tramite la funzione wait() (per convenzione un valore di status pari a 0 indica una terminazione senza errori, un valore diverso da 0 indica invece la presenza di una condizione di errore
unsigned int sleep(unsigned int seconds);
Sospende il processo corrente per seconds secondi.
int pause(void);
Sospende il processo finchè esso non riceve un segnale. Restituisce sempre -1 e setta errno.
#include <stdio.h>
void perror(const char *s);
La funzione perror() stampa a video il messaggio di errore puntato dalla stringa.
#include <stdlib.h>
void exit(int status);
La funzione exit() termina il processo che ha invocato la funzione tutte le funzioni registrate con le funzioni atexit() e on_exit() sono chiamate nell'ordine inverso alla loro registrazione, tutti gli stream aperti vengono scaricati tramite la funzione della libreria standard fflush() e poi chiusi impiegando le funzioni della libreria standard e, infine, viene chiamata la funzione _exit().
int atexit(void (*function)(void));
La funzione atexit() registra la funzione function (senza argomenti) affinché sia chiamata durante la terminazione normale del programma, ovvero quando viene raggiunto lo statement return nalla funzione main() oppure quando viene effettuata una chiamata alla funzione exit(). Si noti che le funzioni registrate con atexit() vengono chiamate in ordine inverso di registrazione. La atexit() ritorna 0 in caso di successo, -1 in caso di errore e la variabile errno viene settata al valore appropriato.
int on_exit(void (*function)(int, void *), void *arg);
Funziona esattamente come atexit(), con la differenza che la function riceve un intero dalla funzione exit() e un puntatore a void passato dall'argomento arg a sua volta passato durante la chiamata di questa funzione. La on_exit() ritorna 0 in caso di successo, -1 in caso di errore.
#include <sys/wait.h>
int wait(int* status);
Con l'esecuzione della wait() il processo padre attende la terminazione di un processo figlio, in modo da sincronizzarsi con essa (equivale ad una Join). Nella variabile status il padre riceve un valore numerico che dipende dal tipo di terminazione del processo figlio: se la terminazione del figlio è stata normale (tramite la _exit/exit o return) status conterrà nei suoi 8 bit bassi l'intero (<256) restituito in uscita dal figlio (tramite la _exit/exit o return) e tutti 0 negli 8 bit alti; se invece la terminazione è stata forzata (ad esempio per una kill eseguita da un altro processo) status conterrà nei suoi bit alti il numero corrispondente al segnale di terminazione e tutti 0 negli 8 bit bassi. La wait() restituisce poi il PID del figlio terminato in caso di successo, -1 in caso di interruzione.
#include <signal.h>
int kill(pid_t pid, int sig);
La funzione kill() invia un segnale ad un processo (pid positivo) o ad un gruppo di processi (pid negativo, se ne usa il modulo). Si noti che il processo che invia il segnale e quello che lo riceve devono avere lo stesso proprietario oppure, in mancanza, il proprietario del processo che invia il segnale deve essere il superuser.
void (*signal (int sig, void (*disp)(int)))(int);
La funzione signal() può essere usata per istruire un processo sul come dovrà trattare un segnale ricevuto (eccetto i segnali di SIGSTOP e SIGKILL), ovvero se ignorarlo, eseguire una opportuna funzione handler o eseguire l'azione di default per quel segnale. Le azioni di default pr ogni segnale sono prefissate e possono contemplare la terminazione del processo, ignorare il segnale, sospendere il processo o riattivare il processo. Esempio d'uso
Int (*Old_Handler); //Puntatore a funzione che restituisce un intero
Old_Handler=signal(SIGINT, SIG_IGN); //Il segnale SIGINT di interruzione generato da Ctrl-C verrà ignorato
signal(SIGINT, Old_Handler); //L'originaria gestione del SIGINT è stata ripristinata
Operazioni sui File
#include <fcntl.h>
int open(const char *path, int oflag [, mode_t mode]);
La funzione open() In caso di successo restituisce un intero fd, in pratica un indice della User File Table, corrispondente quindi ad un descrittore di file, in caso di errore restituisce invece -1. Gli oflag si ottengono per OR bit a bit di O_WRONLY, O_APPEND, O_CREAT e O_TRUNC. Mode non è altro che la modalità di accesso, nella forma 0XYZ (vedi più avanti
int creat(const char *path, mode_t mode); open(path, O_WRONLY|O_CREAT|O_TRUNC, mode);
#include <unistd.h>
int close(int fd);
Dealloca dalla User File Table il descrittore di file (cioè lo rende disponibile per un nuova operazione di open) corrispondente al fd indicato.
ssize_t read(int fildes, void *buf, size_t nbyte);
ssize_t write(int fildes, void *buf, size_t nbyte);
Legge/Scrive in/da buffer indicato da/in file indicato nbyte (il puntatore il R/W viene aggiornato) e restituisce il numero effettivo di byte letti/scritti, -1 invece se si verifica un errore.
off_t lseek(int fildes, off_t offset, int whence);
Sposta la posizione corrente nel file indicato di offset bytes rispetto alla posizione indicata in whence, ovvero SEEK_SET, SEEK_CUR o SEEK_END, e restituisce la posizione attuale nel file o -1 in caso di insuccesso.
int link(const char *existing, const char *new);
Crea un hard-link ad un file esistente: restituisce 0 in caso di successo, -1 altrimenti.
int unlink(const char *path);
Rimuove un hard-link ad un file (se è condiviso viene solo rimossa la directory entry
int rename(const char *old, const char *new);
Rinomina un file.
IPC
L'espressione Inter Process Communication si riferisce a tutte quelle tecnologie software il cui scopo è consentire a diversi processi di comunicare tra loro scambiandosi dati e informazioni. Per realizzare l'IPC Unix mette a disposizione 5 tipi di strumenti: la memoria condivisa (spazio di memoria accessibile da più processi), i semafori (contatori condivisi atomicamente modificabili), le code di messaggi (liste concatenate di messaggi gestite con tecnica FIFO), i pipe e i segnali.
Con riferimento specifico alle prime 3 elencate, queste risorse sono strutture residenti in un'area di memoria del Kernel e un processo che voglia utilizzarle deve richiederne al Kernel l'allocazione. La SVC per l'allocazione di una risorsa di IPC restituisce un ID numerico univoco che ne consente l'uso, ma richiede contestualmente che vengano specificate una chiave (di tipo predefinito) e un modalità (sostanzialmente un insieme di flags) utilizzate dal sistema per definire il modo con cui l'allocazione della risorsa dovrà aver luogo
Int ID = Risorsa_GET(chiave, , modalità);
Si noti che una risorsa IPC allocata da un processo padre viene automaticamente condivisa dai processi figli (che ereditano copia dei dati del padre e quindi anche il valore dell'ID della risorsa allocata), mentre invece se la risorsa IPC deve esser condivisa tra processi non parenti si pone - per il processo allocatore - il problema di come comunicare agli altri processi utilizzatori tale ID o, equivalentemente, una metodologia per allocare tutti la stessa risorsa: la soluzione è data dalla chiave. La chiave può essere un flag (IPC_PRIVATE) quando la risorsa dovrà essere condivisa con processi parenti
Int ID = Risorsa_GET(IPC_PRIVATE, , IPC_CREAT | [IPC_EXCL |] 0XYZ);
oppure un intero quando la risorsa dovrà essere condivisa da più processi indipendenti tra loro. In quest'ultimo caso si può fare in modo che l'allocazione della risorsa avvenga in tutti i processi e non soltanto in uno di essi: sia il processo allocatore che gli utilizzatori invocano la stessa SVC passando la stessa chiave ma indicando modalità diverse
Server Int ID = Risorsa_GET(CHIAVE, , IPC_CREAT | [IPC_EXCL |] 0XYZ);
Client Int ID = Risorsa_GET(CHIAVE, , IPC_ALLOC);
Per il processo server il flag IPC_CREAT segnala che la risorsa deve essere creata e viene messo in OR bit a bit con un numero che viene fuori dalla somma di uno o più tra i seguenti possibili flag
00400 READ by user
00200 WRITE by user
00040 READ by group
00020 WRITE by group
00004 READ by others
00002 WRITE by others
allo scopo di indicare le modalità di accesso consentite alla risorsa (può essere messo in OR bit a bit anche con il flag IPC_EXCL, che fa sì che se una risorsa creata tramite quella CHIAVE esiste già allora la procedura di allocazione fallisce). Per i processi client il flag IPC_ALLOC segnala semplicemente che il processo è un utilizzatore. A questo punto resta da capire come possano processi indipendenti generare la stessa CHIAVE. In realtà, essi possono utilizzare una funzione ftok(path, value) alla quale passare un path_name e un intero a piacere, purchè tutti passino la stessa coppia: chamando tale funzione con gli stessi argomenti ciascuno di questi processi otterrà la stessa CHIAVE.
La Shell mette a disposizione due comandi per trattare le risorse IPC: IPCS stampa a video le informazioni sulle risorse IPC attualmente attive, IPCRM invece consente di rimuovere una o più risorse IPC.
Qui di seguito sono elencate le funzioni C che consentono allocare, manipolare e gestire le risorse IPC di tipo memoria condivisa, semaforo e coda di messaggi
#include <sys/types.h>
#include <sys/ipc.h>
#include <sys/shm.h>
int shmget(key_t key, size_t size, int shmflg);
void* shmat(int shmid, const void *shmaddr, int shmflg);
int shmctl(int shmid, int cmd, struct shmid_ds *buf);
#include <sys/sem.h>
int semget(key_t key, int nsems, int semflg);
int semop(int semid, struct sembuf *sops, size_t nsops);
int semctl(int semid, int semnum, int cmd, );
#include <sys/msg.h>
int msgget(key_t key, int msgflg);
int msgsnd(int msqid, const void *msgp, size_t msgsz, int msgflg);
ssize_t msgrcv(int msqid, void *msgp, size_t msgsz, long int msgtyp, int msgflg);
int msgctl(int msqid, int cmd, struct msqid_ds *buf);
La prima funzione di ogni gruppo è la funzione di allocazione e normalmente restituisce l'ID della risorsa allocata in caso di successo, -1 invece in caso di fallimento (per esempio è già stato richiesto il numero massimo di risorse di quel tipo che il sistema può rilasciare
Le pipe (condotte) sono dei canali unidirezionali per la comunicazione fra processi. Ogni processo può trattare le pipe come se fossero dei file standard, con le dovute eccezioni: le pipe non sono fisicamente presenti sul file system, ma ad ogni pipe è di norma associato un buffer di memoria dell'ordine di 4 KB; la creazione di una pipe genera 2 file descriptor, uno per gli accessi in scrittura utilizzabile dal processo produttore ed uno per gli accessi in lettura utilizzabile dal processo consumatore; non è possibile eseguire riposizionamenti su ciascun file descriptor (tramite una funzione di seek) e una volta che i dati siano stati letti o scritti non è possibile rileggerli o riscriverli: gli accessi in lettura/scrittura sono strettamente sequenziali e la pipe può essere pensata come buffer circolare; un file descriptor può essere aperto o in lettura o in scrittura, ma non in entrambi in modi (unidirezionalita' della pipe).
Si osservi che le pipe sono un meccanismo ottimale di sincronizzazione fra processo produttore e processo consumatore: un processo che legge sulla pipe si blocca se la pipe è vuota, un processo che scrive sulla pipe si blocca se la pipe è piena.
Un processo padre può:
Creare una pipe utilizzando la system call pipe().
Effettuare la fork() di uno o più processi.
Gestire la pipe creata o in input o in output (il figlio la gestirà nell'altro verso)
Al termine della gestione della pipe, viene atteso il processo figlio tramite la system call wait().
Termine del processo padre.
#include <unistd.h>
int pipe(int fildes[2]);
Crea una pipe senza nome inserendo nell'array passato due distinti file descriptors, ambedue aperti in modalità Read/Write: una lettura su fildes[0] accede ai dati scritti su fildes[1] in modalità FIFO, viceversa per la lettura su fildes[1]. Restituisce 0 in caso di successo, -1 altrimenti.
API
Le Application Programming Interfaces sono ogni insieme di procedure disponibili al programmatore, di solito raggruppate a formare un set di strumenti specifici per un determinato compito. Il loro uso costituisce solitamente un metodo per ottenere un'astrazione tra l'hardware e il programmatore, o tra software di basso livello e software di alto livello: le API consentono - in pratica - di evitare ai programmatori di scrivere tutte le funzioni dal nulla.
DMA
Il Direct Memory Access permette ad alcuni sottosistemi hardware (controller di unità a disco, schede grafiche e audio) di un computer di accedere alla memoria di sistema in lettura/scrittura indipendentemente dalla CPU ed è un componente essenziale di tutti i computer moderni, in quanto permette a periferiche che lavorano a velocità diverse di comunicare senza assoggettare la CPU a un enorme carico di interrupt. In un trasferimento DMA un blocco di memoria viene copiato da una periferica a un'altra ad opera del controller DMA: in risposta ad una DRQ (DMA Request, richiesta di DMA) la CPU si limita solo ad autorizzare l'operazione tramite una DACK (DMA Acknowledge, accettazione di DMA) ma durante il trasferimento essa può continuare a svolgere altre operazioni.
POSIX
La sigla che indica la famiglia degli standard dell'IEEE denominati formalmente IEEE 1003, e derivano da un progetto, iniziato nel 1985, finalizzato alla standardizzazione delle API per i software sviluppati per le diverse varianti dei sistemi UNIX.
Script
Il termine script designa un tipo particolare di programma, scritto mediante opportuni linguaggi di programmazione detti linguaggi di scripting. La distinzione tra un programma normale ed uno script non è netta, ma generalmente uno script ha le seguenti caratteristiche: bassa complessità, sostanziale linearità d'esecuzione, mancanza di una propria interfaccia grafica, utilizzo di un linguaggio interpretato, integrazione in un processo di configurazione automatica del sistema (ad ogni avvio, ad ogni login, ) in una pagina Web o per svolgere mansioni accessorie e molto specifiche.
Segnali
I segnali sono il primo e più semplice meccanismo di comunicazione nei confronti dei processi. Nella loro definizione originale essi portano con sé solo il loro tipo e nessun'altra informazione: si tratta in sostanza di interruzioni software portate ad un processo, ad ogni segnale è associato un numero intero che fa riferimento ad un nome simbolico nella libreria Signal.h. Come il nome stesso indica i segnali sono usati per notificare ad un processo l'occorrenza di un qualche evento, in genere vengono usati dal Kernel per comunicare ai processi situazioni eccezionali ma possono anche essere usati come forma elementare di comunicazione tra i processi (ad esempio per il controllo di sessione). I principali eventi che possono generare un segnale sono un errore del programma (divisione per zero, violazione della memoria, ), la terminazione di un processo figlio, la scadenza di un timer, la tentata esecuzione di una operazione di I/O che non può essere eseguita, una richiesta di abort del programma in corso (mandata dalla Shell in corrispondenza della pressione di tasti del terminale, come Ctrl-C o Ctrl-Z) o l'esecuzione di una Kill. Ciascuno di questi eventi (compresi gli ultimi due che pure sono controllati dall'utente o da un altro processo) comporta l'intervento diretto del Kernel che causa la generazione di un particolare tipo di segnale: quando un processo riceve un segnale, invece del normale corso del programma, viene eseguita una azione di default, una apposita routine di gestione (signal handler) che può essere stata specificata dall'utente (nel qual caso si dice che si intercetta il segnale) oppure il segnale può essere ignorato (segnali di abort e kill non possono essere nè ignorati nè intercettati) e la corrispondenza tra il numero del segnale e l'azione da intraprendere è memorizzata in una apposita maschera dei segnali.
Socket
Un (internet) socket è un'interfaccia tra un processo o thread e un protocollo di comunicazione della pila TCP/IP, definita dal sistema come una univoca combinazione delle seguenti entità: protocollo (TCP, UDP o IP), indirizzo IP locale, numero di port locale, indirizzo IP remoto, numero di port remoto. Il sistema è in grado di smistare i pacchetti IP entranti al corrispondente processo applicativo estraendo i parametri necessari ad identificare lo specifico socket direttamente dagli headers applicati dai protocolli IP, TCP e UDP. Uno Unix Domain Socket o IPC socket è un socket virtuale, simile ad un internet socket, usato nei SO che seguono lo standard POSIX per la comunicazione inter-processi. Esso appare come un flusso di byte, simile ad una connessione, ma con la differenza che tutti i dati rimandono all'interno della macchina locale: nella pratica si usano dei file.
Variabile d'ambiente
Una variabile d'ambiente o environment variable definisce una variabile posta al di fuori di ogni programma, normalmente contiene solo stringhe di caratteri e non dati binari, ha in genere un nome composto da lettere maiuscole e contiene usualmente informazioni condivise da più programmi. Semplicisticamente si può considerare le variabili d'ambiente come delle variabili globali, quindi come uno spazio di memoria condiviso da più processi in esecuzione, ma è fortemente sconsigliato il loro uso in questo senso, se non in applicazioni elementari con requisiti di sicurezza nulli e necessità di uno spazio di memoria condiviso molto ridotto, usualmente limitato a poche variabili. Nei SO Windows esse sono condivise da tutti i processi in esecuzione. Nei sistemi UNIX e derivati ogni processo possiede una propria copia delle variabili ed i nuovi processi ne ereditano una copia dal processo che li ha generati, in modo che programmi diversi possano avere variabili d'ambiente diverse. Un esempio di variabile d'ambiente è PATH, contenente in forma di stringa le directory i cui file eseguibili è possibile lanciare in esecuzione senza specificare il nome completo di percorso del file, ma soltanto il nome dell'applicazione.
|
| Appunti su: |
|