|
| Appunti informatica |
|
|
| Appunti informatica |
|
| Visite: 973 | Gradito: |
Leggi anche appunti:Un databaseUn DATABASE è un archivio elettronico di dati, organizzati in modo integrato attraverso tecniche Protezione e SicurezzaProtezione e Sicurezza Si parla di protezione in presenza di meccanismi, messi La codifica delle informazioniLa codifica delle informazioni Nell'elaboratore tutte le informazioni |
 |
 |
Tesina di fine corso
PIC 8259A/simple
L'obiettivo di questo progetto è implementare in linguaggio VHDL un controller interrupt programmabile (PIC) secondo le specifiche del modello Intel 8259A, uno dei più diffusi chip per la realizzazione di funzionalità di interruzione.
Lo scopo di un controller interrupt programmabile è la gestione, per conto della CPU, delle richieste di interruzione provenienti dai dispositivi periferici connessi al calcolatore. L'Intel 8259A è stato a lungo adottato nelle architetture basate su x86 (Intel e AMD), ma, con l'evolvere dei calcolatori, il dispositivo PIC è stato sostituito da un più avanzato APIC (Advanced PIC), che non sarà oggetto di trattazione.
 La
caratteristica di rilievo di un controller PIC è proprio la programmabilità:
come si può vedere sul datasheet, l'Intel 8259A possiede diverse modalità di
funzionamento, ed è possibile programmare da CPU il modo in cui le interruzioni
dovranno essere gestite. Il PIC, infatti, è in grado di mascherare le
interruzioni che non dovranno essere servite in un dato momento, in quanto il
processore sta eseguendo compiti più importanti. La programmazione del PIC è
un'operazione che viene eseguita all'accensione del calcolatore, mediante BIOS,
ma le impostazioni possono essere sovrascritte dal sistema operativo in fase di
caricamento, in quanto il kernel gira in modalità Supervisore con libero
accesso all'hardware.
La
caratteristica di rilievo di un controller PIC è proprio la programmabilità:
come si può vedere sul datasheet, l'Intel 8259A possiede diverse modalità di
funzionamento, ed è possibile programmare da CPU il modo in cui le interruzioni
dovranno essere gestite. Il PIC, infatti, è in grado di mascherare le
interruzioni che non dovranno essere servite in un dato momento, in quanto il
processore sta eseguendo compiti più importanti. La programmazione del PIC è
un'operazione che viene eseguita all'accensione del calcolatore, mediante BIOS,
ma le impostazioni possono essere sovrascritte dal sistema operativo in fase di
caricamento, in quanto il kernel gira in modalità Supervisore con libero
accesso all'hardware.
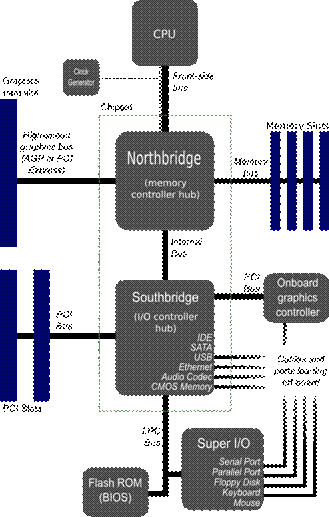
Nei calcolatori moderni, il controller PIC è integrato sulla scheda madre, all'interno del Southbridge, che include tutti i dispositivi di interfacciamento con i bus di I/O, come PCI, PCI-Express, IDE, porte seriali e parallele.
Il Southbridge gestisce le operazioni più lente del calcolatore, come presto vedremo.
Assieme alla piedinatura, il datasheet fornisce dettagliate indicazioni sui registri che possono essere programmati nel PIC, e una completa descrizione del protocollo di interruzione. Tuttavia, per motivi di praticità e di tempo, non siamo stati in grado di implementare tutte le funzionalità, e pertanto ci limiteremo ad implementare un PIC a priorità che implementa unicamente il protocollo di segnalazione a livelli di priorità.
Iniziamo con una panoramica sul problema delle interruzioni. Le operazioni di I/O sono l'elemento chiave di un calcolatore, in quanto esso non è un sistema autistico ma deve comunicare con l'esterno: tanto con un operatore umano quanto con un altro calcolatore.
Esempi tipici di I/O sono i seguenti:
Visualizzazione a schermo di testo su una console di comando
Visualizzazione a schermo di una interfaccia grafica bidimensionale (GUI)
Rendering tridimensionale (applicazioni CAD e videogiochi)
Lettura e scrittura di dati su memoria di massa
Trasmissione di dati ad un altro calcolatore attraverso una rete di calcolatori, come Internet
Scansione di un documento di testo
Stampa di fotografie
Riproduzione e registrazione di segnali audiovisivi
Interazione utente con tastiera e mouse/trackball o touchscreen (lettura dei comandi impartiti dall'utente sull'interfaccia attraverso i suddetti dispositivi)
Tali operazioni, così come tutte le altre che non riteniamo di elencare, vengono eseguiti da dispositivi che, anche se interni al calcolatore, sono esterni alla CPU che esegue il software applicativo. In un tipico scenario, supponendo che l'utente voglia spedire un messaggio di posta elettronica, i dispositivi di I/O coinvolti sono tanti e ognuno ha una specifica funzione. Descriviamo quindi lo scenario come segue:
L'utente utilizza il mouse per posizionare il puntatore sul comando "Crea messaggio" (input)
Mentre l'utente esegue l'azione al punto 1, il puntatore sullo schermo segue i movimenti dell'utente (output)
L'utente fa click sul comando (input)
A schermo viene visualizzata una finestra di composizione messaggio (output)
L'utente richiede che venga aperta la rubrica per selezionare il destinatario (input)
Il sistema legge la rubrica da disco (input)
Il sistema visualizza i contatti a schermo sotto forma di una lista (output)
L'utente seleziona il destinatario (input)
L'utente scrive il testo del messaggio sulla tastiera (input)
A schermo vengono visualizzati i caratteri digitati dall'utente, che così può correggere eventuali errori (output)
L'utente fa click sul comando "Invia messaggio" (input)
Il sistema trasmette un pacchetto di sincronizzazione TCP verso il server di posta in uscita (output)
Il sistema attente un acknowledgement TCP dal server (input)
Il messaggio viene trasmesso secondo il protocollo SMTP (output, ma vi sono anche input in realtà)
A schermo viene visualizzata una conferma dell'avvenuto invio
In questo semplice scenario, i dispositivi coinvolti nell'interazione sono tastiera, mouse, schermo, disco rigido e scheda di rete. Ognuno ha il proprio compito, e il processore, guidato dal sistema operativo e dal software applicativo, deve far sì che il loro utilizzo corretto porti allo scopo preposto, nel caso l'invio di un messaggio email.
Il problema è che le operazioni di I/O sono estremamente lente rispetto alla velocità di esecuzione delle istruzioni di una CPU. Un dattilografo difficilmente supera la velocità di 5 tasti premuti al secondo, mentre una CPU in grado di completare un'istruzione al secondo (ciò si può ottenere col pipelining, ad esempio), alla frequenza di soli 100MHz è in grado di completare 100 milioni di istruzioni al secondo.
È ovvio che, nel caso di un calcolatore che stia eseguendo molti compiti, come la navigazione sul web, la compilazione di un programma e la masterizzazione di un DVD, è improponibile che il processore si metta in attesa attiva dell'input utente da tastiera, ossia non esegua alcun compito fin quando l'utente non avrà premuto un tasto.
La prima soluzione, apparentemente, a questo problema, sarebbe quella per la CPU di interrogare (polling) uno a uno i dispositivi di input per stabilire quale desideri essere servito: nel nostro caso, non sappiamo se in un dato momento è la tastiera a richiedere che venga letto un carattere o il mouse che venga rilevato il suo movimento. La soluzione sincrona, però, non si presta all'applicazione reale, in quanto la CPU spreca inutilmente cicli nella fase di polling.
La soluzione al problema è asincrona: si fa in modo che siano le periferiche stesse a interrompere la CPU quando è richiesta attenzione. Per la verità, una periferica non può letteralmente interrompere la CPU, ma ciò è solo l'effetto macroscopico che si vede eseguendo i programmi a velocità CPU. Per implementare le interruzioni, è innanzi tutto necessario un passo teorico: una piccola modifica al ciclo di Von Neumann, che diviene il seguente:
Fetch
Operand Assembly
Execute
IF NOT Interrupt THEN
Serve Interrupt
GoTo 1
La CPU, dunque, al termine di ogni istruzione, verifica se vi è una richiesta di interruzione da parte di una periferica, e in tal caso si prepara a servire tale interruzione.
Fatto ciò, si è subito visto che vi sono servizi da considerarsi time critical, ossia che è importante che vengano serviti prima di altri tipi di servizi di minore importanza. Ad esempio, in un impianto industriale, l'interruzione proveniente da un controller termostatico che segnala l'eccessiva temperatura di un altoforno dovrebbe far immediatamente scattare una routine di emergenza che spenga l'impianto. Ciò dovrebbe avere massima priorità, senz'altro più alta di quella di un dispositivo che segnala l'avvenuta produzione di un pezzo.
Dunque, nei processori moderni, gli interrupt sono organizzati a priorità. La priorità di un dispositivo è detta IRQ. Per convenzione, sui dispositivi 8259, ha priorità maggiore il dispositivo con IRQ0.
La convenzione va oltre la specifica delle priorità: la maggior parte dei dispositivi assume un IRQ specifico. Wikipedia ci riporta una tabella nella quale possiamo osservare quali siano, nell'architettura x86, gli IRQ tipicamente assegnati a determinate periferiche:
IRQ
0 - System timer. Reserved for the system. Cannot be changed by a user.
IRQ 1 - Keyboard. Reserved for the system. Cannot be altered even if no
keyboard is present or needed.
IRQ 2 - Cascaded signals from IRQs 8-15. A device configured to use IRQ 2 will
actually be using IRQ 9
IRQ 3 - COM2 (Default) and COM4 (User) serial ports
IRQ 4 - COM1 (Default) and COM3 (User) serial ports
IRQ 5 - LPT2 Parallel Port 2 or sound card
IRQ 6 - Floppy disk controller
IRQ 7 - LPT1 Parallel Port 1 or sound card (8-bit Sound Blaster and
compatibles)
IRQ 8 - Real time clock
IRQ 9 - Free / Open interrupt / Available / SCSI. Any devices configured to use
IRQ 2 will actually be using IRQ 9.
IRQ 10 - Free / Open interrupt / Available / SCSI
IRQ 11 - Free / Open interrupt / Available / SCSI
IRQ 12 - PS/2 connector Mouse. If no PS/2 connector mouse is used, this can be
used for other peripherals
IRQ 13 - ISA / Math Co-Processor
IRQ 14 - Primary IDE. If no Primary IDE this can be changed
IRQ 15 - Secondary IDE
Come possiamo notare, il timer di sistema ha priorità massima, il controller IDE primario ha priorità sul secondario ma non sul coprocessore matematico né sulle porte seriali COM.
Possiamo verificare ciò empiricamente: nel nostro caso abbiamo constatato, attraverso i tool forniti dal sistema operativo, l'assegnazione degli IRQ su un processore AMD64 per quanto riguarda il timer di sistema.
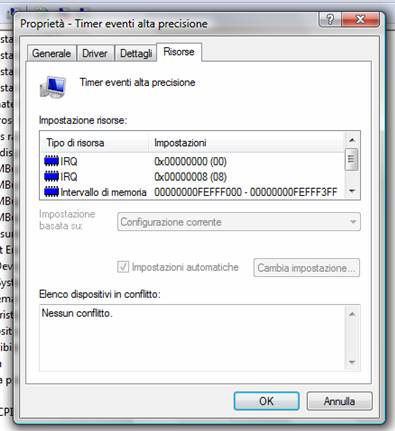 Ciò significa che, nel caso in cui sia la porta
parallela LPT1 che la tastiera sollevino un interrupt, verrà servita prima la tastiera
e poi la porta parallela.
Ciò significa che, nel caso in cui sia la porta
parallela LPT1 che la tastiera sollevino un interrupt, verrà servita prima la tastiera
e poi la porta parallela.
In un tipico protocollo di I/O asincrono, CPU e periferica comunicano tra di loro per concordare l'operazione e in seguito scambiare i dati. Ricordiamo che l'accesso all'I/O è riservato al sistema operativo, quindi un software (come il client di posta che vuole caricare la rubrica) dovrà chiedere al kernel di eseguire l'azione per suo tramite.
Sebbene la gestione del file system sia incredibilmente complicata, per ragioni di robustezza e sicurezza, possiamo semplificare tutto ciò riducendo il caricamento della rubrica da disco ad una serie di passi più semplici:
Il client prepara i registri del processore in una configurazione conforme alle specifiche del sistema operativo. Ad esempio, il registro A0[1] viene caricato col puntatore alla stringa che contiene nome e percorso del file da caricare, D0 viene caricato con i flag di sola lettura e A1 con il puntatore al buffer dove dovrà essere caricato il contenuto del file.
Il client effettua dunque una system call, facendo in modo che il processore entri in stato Supervisore ed esegua le routine di file system del kernel. Da adesso in poi, il controllo è del sistema operativo.
Il sistema verifica la validità dei dati e individua il disco dove essi sono presenti, nonché le esatte coordinate da caricare
Il sistema scrive su un apposito registro del controller del disco il settore da caricare e abilita il flag di lettura
A questo punto, il sistema operativo, sapendo di dover attendere diverse decine di millisecondi prima del caricamento, sospende il thread in esecuzione e passa il controllo ad uno in attesa di essere eseguito
Il disco, una volta letti i dati e caricati nel suo buffer interno, segnala alla CPU il completamento dell'operazione sollevando un interrupt
La CPU sospende l'esecuzione e individua che la richiesta proviene dal disco rigido quindi conferma l'avvenuto riconoscimento dell'interrupt (INT acknowledgement)
La CPU esegue una routine del kernel che completa il caricamento dei dati spostandoli dal buffer disco alla memoria, nella locazione desiderata dal thread richiedente. Il protocollo con il disco termina
Il sistema operativo, in base alle proprie regole di schedulingl, decide se restituire il controllo al client di posta
Finora non abbiamo trattato in adeguato dettaglio la parte hardware della gestione delle interruzioni, soffermandoci sul software.
Quando si produce un calcolatore, in particolare la sua scheda madre, tutti i dispositivi in essa integrati vengono fisicamente connessi, in maniera permanente, alle varie linee di controllo e dati che mettono in comunicazione i componenti del sistema. Un metodo semplice ed economico per gestire le interruzioni a priorità è la daisy chain, implementata nei sistemi basati su 68000.
La daisy chain è come una lista concatenata: i dispositivi sono connessi in parallelo al bus dati e la linea INT, ma lo sono in serie per quanto riguarda la linea INTA, così che ogni dispositivo è connesso al successivo (per INTA).
Per convenzione, diciamo che il dispositivo 0 è quello connesso direttamente alla CPU mentre il dispositivo N-1 è l'ultimo della catena. Quando un dispositivo I intende sollevare un interrupt, alza la linea INT sulla linea comune, tipicamente realizzata con tecnologia open drain/open collector. Anziché effettuare il polling, la CPU alza INTA su 0, e la regola è la seguente: quando un dispositivo J riceve INTA dal precedente, se non ha richiesto interruzioni allora propaga INTA su J+1, altrimenti prosegue con il protocollo. In questo modo, anche il segnale INTA si propagherà fino al destinatario.
Quando il dispositivo che ha richiesto INT riceve INTA, capisce di essere in fase di servizio e scrive sul bus dati il suo identificativo, in modo che la CPU capisca quale dispositivo ha richiesto l'interrupt. Quindi la CPU, letto l'ID, abbassa INTA e il dispositivo abbassa INT.
In questa daisy chain, come possiamo osservare dall'algoritmo di propagazione di INTA, il dispositivo fisicamente più vicino alla CPU ha la massima priorità, mentre quello a fine catena la minore. Infatti possiamo affermare che per servire la INT di un dispositivo K non ci deve essere nessun dispositivo K-1 a richiedere interruzioni contemporaneamente.
L'uso del PIC, a fronte di ciò, è legato alla possibilità di controllare dinamicamente il comportamento degli interrupt, senza dover implementare su ogni anello della daisy chain un apposito algoritmo. In questo caso, tutte le linee INT dei dispositivi sono connesse al PIC in parallelo, e il PIC esce con un'unica linea INT verso la CPU, dalla quale riceve INTA. La programmazione del PIC fa sì che il criterio di selezione del dispositivo da servire possa cambiare dinamicamente. Ad esempio, l'ultimo dispositivo servito potrebbe diventare quello dalla minor priorità, oppure si può usare un algoritmo round robin per le priorità. In questi casi, la convenzione fatta sulla numerazione degli IRQ è superflua, in quanto, in un dato momento, IRQ(i) potrebbe avere meno priorità di IRQ(i+1).
Esaminiamo i connettori dell'8259A come indicati sul datasheet Intel:
|
Nome pin |
Input/Output |
Descrizione |
|
Vcc |
I |
Alimentazione 5V |
|
GND |
I |
Alimentazione massa |
|
CS' |
I |
Chip select: quando basso, abilita le comunicazioni con la CPU. Viene collegato ad un comparatore connesso al bus indirizzi |
|
WR' |
I |
Write: quando basso, abilita il PIC a ricevere comandi |
|
RD' |
I |
Read: quando basso, abilita il PIC a inviare dati alla CPU sul bus dati |
|
D7-D0 |
I/O |
Bus dati: linee bidirezionali per la comunicazione con la CPU |
|
CAS0-CAS2 |
I/O |
Cascade: controllano i PIC in cascata. Sono di output per il master e di input per lo slave |
|
SP'/EN' |
I/O |
Slave program/Enable buffer: doppia funzionalità. Quando non è in modalità buffer, designa uno slave, altrimenti comanda i trasmettitori del buffer |
|
INT |
O |
Interrupt: interrompe la CPU |
|
IR0-IR7 |
I |
IRQ: le periferiche vengono connesse ad uno dei pin rispettando la regola del lower-priority |
|
INTA |
I |
Interrupt acknowledgement: la CPU conferma che è pronta a servire la richiesta |
|
A0 |
I |
A0: parte del meccanismo di indirizzamento dei registri PIC |
In totale ci sono 28 pin. Osserviamo che il PIC è una rete asincrona, in quanto non vi sono segnali di clock in ingresso.
Analizziamo subito la particolare modalità di indirizzamento del PIC: un controller PIC ha due indirizzi, uno pari ed uno dispari. I bit più significativi dell'indirizzo vengono confrontati con i bit più significativi del bus indirizzi per determinare se il PIC è stato selezionato, mentre il bit meno significativo (A0) viene inviato direttamente al PIC. Ciò ci permette di indirizzare due registri mediante il bus indirizzi. In realtà, il PIC contiene al suo interno un particolare meccanismo di indirizzamento che usa il bit A0 in concomitanza con alcuni bit della parola dati (D7-D0) per indirizzare più di due registri. Questo perché il PIC ha 4 registri ICW (Instruction Command Word) e 3 OCW (Operation Command Word) da 8 bit ognuno.
Ad esempio, ICW2 viene indirizzato in scrittura dopo aver scritto su ICW1. La sincronizzazione delle operazioni avviene attraverso pulsazioni del segnale INTA in logica 0. Programmare il PIC significa, come già illustrato, definirne la modalità di funzionamento: è possibile impostare la modalità di selezione delle priorità, il tipo di protocollo (perché si può usare uno stesso 8259A su diverse architetture)o la maschera.
Nella nostra implementazione, apporteremo delle semplificazioni al protocollo di interrupt, e non andremo a prevedere alcuna programmazione.
In particolare, dal punto di vista comportamentale, ci aspettiamo quanto segue:
Quando il PIC riceve un interrupt su una o più linee IRx, determina il dispositivo con maggiore priorità attraverso la regola semplice dell'ID minore, quindi alza il segnale INT
Il processore riceve INT e invia un impulso negativo di INTA al PIC
Sul primo impulso INTA, il PIC abbassa INT e scrive sul bus dati l'identificativo del dispositivo nei bit meno significativi (D2-D0)
Il processore legge l'identificativo e si prepara a servire l'interrupt
Sul secondo impulso INTA, il PIC disabilita il bus dati e si aspetta che la periferica abbassi la sua linea INT, quindi si riporta nello stato iniziale
Facciamo l'assunzione che la maschera sia gestita internamente dal PIC: in fase di simulazione, forzeremo la maschera a particolari valori per testarne le funzionalità. Nel nostro caso, la maschera non è selettiva come nel protocollo reale, ma maschera soltanto gli interrupt maggiori del valore indicato (o nessuno).
Il PIC è stato implementato in VHDL mediante componenti di più basso livello, applicando il principio di granularità di VHDL: mentre per alcuni dei componenti è stata utilizzata una descrizione comportamentale del funzionamento, essenzialmente dovuta alla laboriosità della progettazione in logica a due livelli, per altri sono invece state implementate le effettive architetture fino al livello gate.
Per quanto riguarda la logica, abbiamo ritenuto interessante utilizzare la logica NOR. La scelta delle gate normalmente è dettata dalla tecnologia su silicio attualmente in uso. Supponendo di lavorare in NMOS, sarebbe più economico realizzare gate NOR. Le specifiche sulle gate vengono imposte dal produttore dell'hardware e/o dal committente e non dal progettista, il quale si deve attenere ad esse. Grazie a VHDL, come vedremo, sarà possibile in maniera molto semplice lo switch da una tecnologia all'altra cambiando semplicemente la dichiarazione delle architetture nell'istanziazione dei componenti.
Siamo dunque partiti dalla progettazione degli elementi di più basso livello, utili in seguito a implementare i principali componenti del PIC: abbiamo cioè implementato le gate NOR a due ingressi, e da lì le porte AND, OR e NOT utilizzando le suddette NOR. Qui va fatta una precisazione doverosa: implementare le tre gate fondamentali per mezzo di un'altra gate è un passaggio decisamente ridondante, in quanto il progettista ha gli strumenti per effettuare direttamente la progettazione in una data logica di una rete. Tuttavia, poiché in alcuni punti, come ad esempio nella maschera di interrupt, la funzionalità di più alto livello da implementare è una AND bit a bit, anziché implementare tale funzionalità direttamente in NOR, abbiamo preferito aggiungere un layer di astrazione utilizzando le entità AND2, che a loro volta sono mappate su entità NOR2. Nel caso fosse necessario passare ad una logica NAND, basterebbe cambiare le istanze delle suddette AND2 verso una implementazione basata su NAND.
Tale comportamento non giustifica, tuttavia, l'utilizzo di tutto il set di gate nella progettazione delle reti più complesse: per quanto ciò crei la massima astrazione e riuso possibile, una progettazione generica non è in grado di ottimizzare il circuito logico per l'implementazione, aggiungendo livelli logici e ritardi che si potrebbero evitare effettuando progettazioni separate per NAND e NOR anziché un'unica progettazione riusabile. Il motivo per cui noi lo abbiamo fatto è stato però quello di mostrare, a titolo illustrativo, le potenzialità del linguaggio. Ma proprio in virtù del potenziale di VHDL, qualunque progettista che metta mano ai nostri sorgenti potrà aggiungere, molto semplicemente, una implementazione basata su NOR2 e/o su NAND2 dei medesimi componenti rispettandone l'interfaccia e ottenendo un circuito ottimizzato.
Ciò premesso, analizziamo il contenuto del file NOR2.VHD realizzato con PeakVHDL. Questa libreria, realizzata appositamente per questo progetto, contiene essenzialmente le porte logiche comuni e un registro D a 8 bit asincrono implementato mediante flip-flop RS a NOR incrociate.
Dato che questa gate è per noi atomica, la implementiamo come behavioural, lasciando al produttore del circuito la mappatura su transistor. Di seguito il codice sorgente:
entity NOR2 is
generic ( port_delay: time := 5ns );
port (
-- WIZ BEGINPORTS (Entity Wizard command)
x: in std_logic;
y: in std_logic;
o: out std_logic
-- WIZ ENDPORTS (Entity Wizard command)
);
end NOR2;
architecture BEHAVIOR of NOR2 is
-- Note: signals, components and other objects may be declared here if needed.
begin
o <= x nor y after port_delay;
end BEHAVIOR;
Questa è una semplice porta NOT, realizzata implementando una singola gate NOR2 che in ingresso prende la stessa variabile in entrambe le porte. Di seguito il sorgente:
entity inv is
port (
x: in std_logic;
y: out std_logic
);
end inv;
architecture withnor2 of inv is
component n port (x, y: in std_logic; o: out std_logic);
end component;
for all: n use entity work.nor2(behavior);
begin
g0: n port map (x,x,y);
end withnor2;
La porta OR2 è semplicemente il negato della NOR2. Avremmo potuto realizzarla in maniera più esplicita con una NOR e una NOT, ma abbiamo preferito ignorare il livello di astrazione offerto dalla NOT in favore di una più comprensibile implementazione. Di seguito il sorgente:
entity or2 is
port (
x, y: in std_logic;
o: out std_logic
);
end or2;
architecture withnor of or2 is
component n port (x, y: in std_logic; o: out std_logic); end component;
for all: n use entity work.nor2(behavior);
signal s1: std_logic;
begin
g0: n port map (x, y, s1);
g1: n port map (s1, s1, o);
end withnor;
Per realizzare una AND2 in NOR2, è sufficiente negare gli ingressi e mandarli a una NOR2. Di seguito il sorgente:
architecture WIRED of and2 is
component q1 port (x, y: in std_logic; o: out std_logic);
end component;
for all: q1 use entity work.nor2(BEHAVIOR);
signal i0, i1: std_logic;
begin
g0: q1 port map(x, x, i0);
g1: q1 port map(y, y, i1);
g2: q1 port map(i0,i1,o);
end WIRED;
Per realizzare un flip-flop RS, ovviamente asincrono, è sufficiente incrociare due NOR tenendo presente che in uscita alla NOR con ingresso S il bit in uscita è Q'. Di seguito il sorgente:
entity RSFLIPFLOP is
port (
r: in std_logic;
s: in std_logic;
q: buffer std_logic;
qn: buffer std_logic
);
end RSFLIPFLOP;
architecture WIRED of RSFLIPFLOP is
component N1 port (x, y: in std_logic; o: out std_logic);
end component;
for all: N1 use entity work.nor2(BEHAVIOR);
begin
q0: N1 port map (r, qn, q);
q1: N1 port map (s, q, qn);
end WIRED;
Questa entità è un po' più complessa delle precedenti. Il suo funzionamento è quello di adattatore di interfaccia. Non ha senso parlare di questa entità senza aver prima illustrato l'interfaccia di un flip-flop D, ma è necessario implementarla prima di implementare il flip-flop D. Semplicemente, questo componente trasforma i segnali in ingresso a un flip-flop D (D, Enable e Reset) in segnali di controllo per flip-flop RS. Di seguito il sorgente:
entity D_TO_RS is
port (
d: in std_logic;
enable: in std_logic;
reset: in std_logic;
r, s: out std_logic
);
end D_TO_RS;
architecture wired of D_TO_RS is
component iv port (x: in std_logic; y: out std_logic); end component;
component a2 port (x, y: in std_logic; o: out std_logic); end component;
component o2 port (x, y: in std_logic; o: out std_logic); end component;
for all: iv use entity work.inv(withnor2);
for all: a2 use entity work.and2(wired);
for all: o2 use entity work.or2(withnor);
signal i0,i1,i2,i3: std_logic;
begin
g0: iv port map(reset, i0);
g1: a2 port map(i0, d, i1);
g2: o2 port map(enable, reset, i3);
g3: iv port map(i1, i2);
g4: a2 port map(i3, i2, r);
g5: a2 port map(i3, i1, s);
end wired;
Questa entità rappresenta un registro a 8 bit, costruito per mezzo di 8 flip-flop RS e relativi adattatori. Avremmo potuto inglobare la coppia RS-adattatore in un flip-flop D, in modo da creare un nuovo componente riusabile ad un più elevato livello di astrazione. Semplicemente, non lo abbiamo fatto.
entity REGISTER8 is
port (
d: in std_logic_vector(7 downto 0);
en, rst: in std_logic;
q, qn: buffer std_logic_vector(7 downto 0)
);
end REGISTER8;
architecture wired of REGISTER8 is
component ff port (r, s: in std_logic; q, qn: buffer std_logic); end component;
component ad port (d, enable, reset: in std_logic; r, s: out std_logic); end component;
for all: ff use entity work.rsflipflop(wired);
for all: ad use entity work.d_to_rs(wired);
signal res, set: std_logic_vector(7 downto 0);
begin
flips: for i in 7 downto 0 generate
a : ad port map(d(i),en,rst,res(i),set(i));
f : ff port map(res(i),set(i),q(i),qn(i));
end generate;
end wired;
La porta tri-state è una speciale porta, non realizzabile come rete logica, la cui uscita ha 3 stati: alto, basso e alta impedenza. Questo particolare stato rappresenta lo scollegamento elettrico del circuito a valle da quello a monte: la porta, infatti, assume una impedenza tendente all'infinito tale che non vi possa essere influenza elettrica sul circuito alla quale è collegata. La porta tri-state è utilizzata nei circuiti di scrittura su bus: quando più dispositivi devono scrivere dati su di una stessa linea elettrica, in un dato istante deve essercene soltanto uno effettivamente connesso. Se due dispositivi fossero in parallelo sulla linea di bus, potrebbe addirittura verificarsi un corto circuito. Per evitare una simile situazione, è necessario l'uso di un interruttore che separi dal bus i dispositivi che non devono scrivervi. La porta tri-state è proprio un interruttore elettronico, che funziona nel modo seguente:
Se la linea di abilitazione è attiva, in uscita viene scritto il valore della linea dati
Se la linea di abilitazione è disattiva, il circuito viene scollegato.
Non entreremo nei dettagli elettronici di come si realizzi una porta tri-state. In VHDL, l'abbiamo implementata per mezzo di una descrizione data flow
entity threestate is
generic (port_delay: time:= 3ns);
port (
x: in std_logic;
en: in std_logic;
y: out std_logic
);
end threestate;
architecture dataflow of threestate is
begin
y <= 'Z' when en = '0' else x;
end dataflow;
Il riconoscitore di fronte di salita è un altro interessante dispositivo, che nel nostro caso è utilizzato per eseguire correttamente la cattura di dati su un registro con rete asincrona. Il riconoscitore di fronte di salita restituisce uscita alta solo sul fronte di salita di un segnale. L'uso che ne facciamo è particolare: nel PIC, è usato per limitare la durata del segnale che abilita il registro buffer a catturare l'ID della periferica da scrivere sul bus, simulando un comportamento impulsivo. Nel nostro caso, abbiamo appositamente modificato il circuito per far sì che il riconoscitore di fronte sia in realtà un limitatore logico, ossia un circuito che limita il tempo in cui il segnale ad esso in ingresso sia alto. Lo abbiamo progettato in logica NOR, e questo ci costa un ritardo di 10ns, tipicamente inaccettabile per applicazioni come il riconoscimento di fronte. Tuttavia il circuito assolve correttamente i suoi compiti, e solo il nome è un abuso di notazione.
Possiamo definire la relazione ingresso-uscita nel modo che segue:
Quando il segnale in ingresso è basso, l'uscita è comunque bassa. Quando il segnale in ingresso è alto, il segnale in uscita è alto, ma la sua durata non supera i 30ns circa.
Ciò significa che la durata dell'impulso alto è pari al minimo tra 30ns e la durata dell'impulso alto in ingresso. Nella realtà, i riconoscitori di fronte si realizzano con amplificatori operazionali retroazionati e non i circuiti logici. Il motivo per cui facciamo durare l'impulso ben 30ns è dovuta ai ritardi sulle linee di traduzione dei segnali dei registri.
Di seguito il codice
entity rising_edge_detector is
-- Vincolo: il segnale X deve rimanere alto per almeno 30ns
port (
x: in std_logic;
y: out std_logic
);
end rising_edge_detector;
architecture wired of rising_edge_detector is
component nt port (x: in std_logic; y: out std_logic);
end component;
component nr port (x,y: in std_logic; o: out std_logic);
end component;
for all: nt use entity work.inv(withnor2);
for all: nr use entity work.nor2(behavior);
signal xn: std_logic;
signal stage: std_logic_vector(0 to 7);
begin
n1: nt port map (x, xn);
n0: nt port map (x, stage(0));
sts: for i in 0 to 6 generate
ns: nt port map (stage(i), stage(i + 1));
end generate;
nf: nr port map (xn, stage(7),y);
end wired;
Come già accennato, avremmo implementato il PIC per mezzo dei componenti principali. Innanzi tutto, abbiamo definito l'architettura base del modello semplificato, dalla quale abbiamo rimosso il bus interno e registri come gli ICW/OCW e l'ISR. Questa architettura è tutta sotto la direzione della logica di controllo, implementata attraverso un'architettura VHDL comportamentale, che reagisce ai segnali provenienti dai componenti fisicamente mappati all'interno del controller
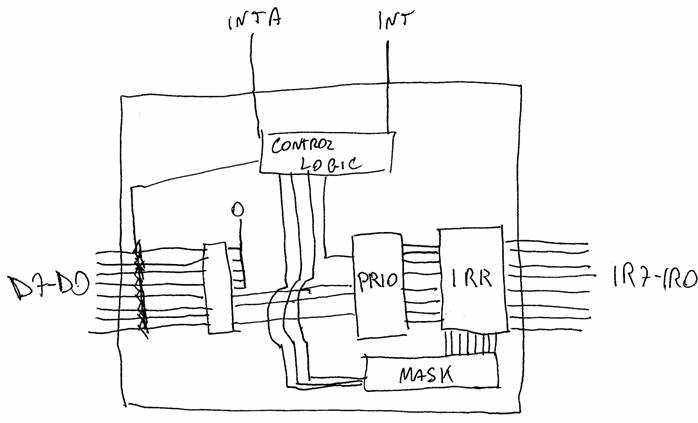
Gli ingressi delle linee IR7-IR0 vengono presi direttamente dall'IRR, che li filtra in base alla maschera (nel nostro caso impostata a 111, ma grazie al test bench IRR è facile desumere il comportamento del dispositivo con una maschera attiva), quindi gli interrupt filtrati entrano nel priority resolver, che ha due variabili in uscita: una è un bit che indica se è presente una richiesta di interrupt, l'altro un codice a 3 bit che indica l'ID del dispositivo a maggior priorità che ha vinto l'arbitraggio.
Il codice va in ingresso ai bit meno significativi di un registro D, il quale, attraverso porte tri-state abilitate dalla logica di controllo scrive sul bus una stringa i cui tre bit meno significativi rappresentano l'ID della periferica da servire. I bit più significativi, per quanto non specificati nella logica, sono comunque impostati a zero.
La logica di controllo è guidata da due unici segnali in ingresso: INTA' e il segnale is_int in uscita dal selettore di priorità. È dunque realizzata mediante un processo VHDL.
Essi utilizzano alcune variabili di stato. Uno controlla quante pulsazioni INTA' sono state ricevute, l'altro controlla lo stato di funzionamento del protocollo di interrupt.
Quando il circuito è inizializzato, si suppone che le linee IR siano tutte a zero, dunque non vi siano richieste di interruzione. Nel momento in cui almeno una delle linee IR si alza, il codice di interruzione cambia, e va in ingresso ai registri di buffer che sono però ancora disabilitati. Nel contempo, il segnale is_int si alza e avvia un apposito processo della logica di controllo che alza INT verso la CPU.
Supponendo che il processore riceva INT e reagisca, imporremo al test bench una pulsazione negativa sulla linea INTA'. In seguito a questa prima pulsazione, il processo relativo alla linea INTA' andrà ad abbassare INT e ad abilitare, in sequenza, gli ingressi di abilitazione dei registri e quindi le porte tri-state del bus. Il motivo per cui la memorizzazione del codice della periferica da servire è rimandato a questo punto del ciclo, è quello di permettere ad una periferica di priorità maggiore di inserirsi nella coda di attesa dopo che una periferica di priorità minore ha già inizializzato il ciclo e prendere il suo posto. Inoltre dobbiamo supporre che il tempo intercorso tra la ricezione delle due pulsazioni di INTA' sia sufficiente a scrivere i dati sul bus. Ricordiamo infatti che il PIC è un dispositivo asincrono, e nelle specifiche sono definiti i tempi minimi.
entity PIC_8259A is
generic (reg_delay: time := 30ns; port_delay: time := 10ns);
port (
-- WIZ BEGINPORTS (Entity Wizard command)
Vcc: in std_logic;
GND: in std_logic;
CSn: in std_logic;
WRn: in std_logic;
RDn: in std_logic;
D: in std_logic_vector(7 DOWNTO 0);
CAS: inout std_logic_vector(3 downto 0);
SPnENn: inout std_logic;
INT: out std_logic;
IR: in std_logic_vector(7 DOWNTO 0);
INTAn: in std_logic;
A0: in std_logic
-- WIZ ENDPORTS (Entity Wizard command)
);
end PIC_8259A;
architecture COMPONENTI of PIC_8259A is
-- Note: signals, components and other objects may be declared here if needed.
component irr_reg port (IRQ: in std_logic_vector(7 downto 0); mask: in std_logic_vector(7 downto 0); int: out std_logic_vector(7 downto 0));
end component;
component imask port (level: in std_logic_vector(2 downto 0); mask: out std_logic_vector(7 downto 0));
end component;
component prio port (
irq: in std_logic_vector(7 downto 0);
int: out std_logic;
code: out std_logic_vector(2 downto 0)
);
end component;
component reg8 port (
d: in std_logic_vector(7 downto 0);
en, rst: in std_logic;
q, qn: buffer std_logic_vector(7 downto 0)
);
end component;
component tstate port (
x: in std_logic;
en: in std_logic;
y: out std_logic
);
end component;
for all: irr_reg use entity work.IRR(wired);
for all: imask use entity work.intmask(behaviour);
for all: prio use entity work.prioriter(behavior);
for all: reg8 use entity work.register8(wired);
for all: tstate use entity work.threestate(dataflow);
signal mask: std_logic_vector(7 downto 0);
signal int_sig: std_logic_vector(7 downto 0);
signal intmask: std_logic_vector(2 downto 0);
signal effective_int: std_logic_vector(7 downto 0);
signal is_int: std_logic;
signal int_code: std_logic_vector(2 downto 0);
signal internal_int_code: std_logic_vector(2 downto 0);
signal latch_enable: std_logic;
signal buffered_code: std_logic_vector(7 downto 0);
signal enable_data_bus: std_logic;
signal inta_pulse: std_logic;
signal in_cycle: std_logic;
begin
intmask <= '111';
irr: irr_reg port map(IR, mask, int_sig);
imsk: imask port map(intmask, mask);
prioriter: prio port map(int_sig,is_int,int_code);
reg_int: reg8 port map(d => '00000'&int_code, en => latch_enable, rst => '0', q => buffered_code);
buffer_tstate: for i in 7 downto 0 generate
buf: tstate port map(buffered_code(i),enable_data_bus,d(i));
end generate;
p1: process(is_int)
begin
if is_int = '1' and not in_cycle = '1' then
INT <= '1' after port_delay;
inta_pulse <= '0';
in_cycle <= '1';
end if;
end process p1;
p2: process(intan)
begin
if intan = '0' and intan'event and in_cycle = '1' then
if inta_pulse = '0' then
int <= '0' after port_delay;
inta_pulse <= '1';
latch_enable <= '1';
latch_enable <= '0' after port_delay;
enable_data_bus <= '1' after reg_delay;
elsif inta_pulse = '1' then
enable_data_bus <= '0';
inta_pulse <= '0';
in_cycle <= '0';
end if;
end if;
end process p2;
end COMPONENTI;
Di seguito riepiloghiamo quanto ottenuto dai test dei principali componenti e del dispositivo PIC, mediante appositi test bench realizzati per il caso.
Abbiamo innanzi tutto simulato il corretto funzionamento della NOR a 2 ingressi, mediante un test che coprisse tutti i possibili input. Data la semplicità della porta, siamo stati in grado di realizzare un test completo.
Di seguito il grafico della simulazione
![]()
I segnali x e y rappresentano gli ingressi della NOR, mentre o rappresenta l'uscita.
Dopo i primi 5ns dall'inizializzazione a 00 della coppia (x,y), l'uscita si assesta su 1. A 50ns, y commuta e di conseguenza l'uscita viene posta a zero. Solo a 200ns, quando l'ingresso viene portato nuovamente a (0,0), l'uscita è di nuovo alta.
Riepiloghiamo brevemente la funzione di questo dispositivo, descritto in modo comportamentale. Ad ogni combinazione dei segnali IRQ di ingresso (eventualmente filtrati a monte da una maschera), il dispositivo pone in uscita i segnali INT e CODE nel modo seguente:
INT alto indica la presenza di almeno una linea IRQ alta
Qualora INT sia alto, CODE indica, in formato numerico binario, l'identificativo minore tra quelli delle linee IRQ attualmente alte, altrimenti è trascurato
Il dispositivo è una rete combinatoria. Il ritardo nella logica è di 15ns, paragonabile a 3 livelli di porte NOR a 5ns di delay. La codifica delle linee IRQ è tale che il bit meno significativo rappresenti la linea 0, quella a massima priorità.

Osserviamo che dopo i primi 15ns, l'uscita INT è bassa, in quanto l'ingresso è stato inizializzato a 0. Il valore di CODE è il valore Undefined della Standard Logic. Tale valore cambia, in concomitanza con l'alzarsi di INT, solo quando tra le linee IRQ si presenta almeno una linea alta. In questo caso il codice è 10011100, dove il bit 2 è quello alto a priorità maggiore. L'uscita è dunque 010, due appunto.
Nella terza combinazione, intorno ai 100ns, a ingresso 11000000 corrisponde uscita INT alta e CODE pari a 110, che è 6. Ricordiamo che il fatto che CODE valga zero, significa, quando INT è alto, che la linea IRQ0 è alta e ha vinto l'arbitraggio delle priorità.
Osserviamo infine, anche se non mostrato chiaramente in figura, che dopo i 400ns l'ingresso di IRQ torna a 00000000, e di conseguenza l'uscita INT va a 0. Tuttavia, il valore di CODE rimane a 000, ossia il valore mostrato all'ingresso 11111111.
Il test che abbiamo eseguito non è completo. Servirebbero 256 combinazioni per testare con certezza assoluta il corretto funzionamento del dispositivo. Tuttavia lo si può ritenere accettabile.
Il registro D a 8 bit, come già illustrato, è basato sui flip-flop di tipo RS. Per ogni cella RS, un circuito di adattamento dei segnali di interfaccia da segnali di controllo D a segnali di controllo RS.
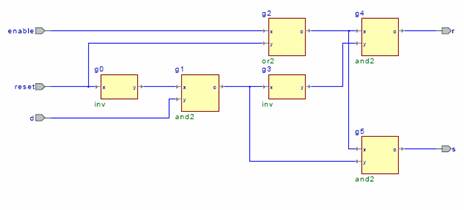 Come possiamo osservare, tale circuito traduce i segnali enable, reset e d in segnali reset e set. Esso è
posto all'ingresso di ogni cella. Il registro a 8 bit è realizzato in modo che
tutte le celle condividano le linee reset ed enable, e con le linee d, q e q
negato formino tre distinti byte.
Come possiamo osservare, tale circuito traduce i segnali enable, reset e d in segnali reset e set. Esso è
posto all'ingresso di ogni cella. Il registro a 8 bit è realizzato in modo che
tutte le celle condividano le linee reset ed enable, e con le linee d, q e q
negato formino tre distinti byte.
La rete combinatoria di adattamento, sfortunatamente, è implementata senza minimizzazione, e ciò porta (considerando che le porte AND, OR e NOT sono realizzate su NOR) a ritardi di oltre 20ns. Avremmo potuto sfruttare uno dei principali punti di forza di VHDL, il binding delle architetture, e re-implementare il circuito direttamente in logica NOR a 2 livelli, riducendo i ritardi a 10ns. Un costruttore che avesse voluto poi implementare tale componente in NAND avrebbe potuto fare la medesima cosa, ma ciò va oltre i fini didattici.

Iniziamo col dire che il registro è una rete sequenziale, e ciò pone dirette implicazioni sulla validità dei test. In teoria, un test completo di una rete sequenziale si ha per tutti i possibili ingressi di tutti gli che la rete può assumere. Nel caso del registro si tratterebbe di 210 ingressi e 28 stati interni, per un totale di 262144 possibili combinazioni. Pertanto è da escludere a priori qualunque pretesa di completezza nel test.
Non c'è molto da commentare sul comportamento del registro durante il test: dopo 30ns dall'abilitazione dello stesso, il valore in ingresso viene catturato e mostrato in uscita. Osserviamo che l'uscita negata si aggiorna prima dell'uscita affermata.
Abbiamo realizzato un test bench che simula, complessivamente, il comportamento di processore e periferiche. Da un lato, collegate alle linee IR7-IR0, vi sono le periferiche, mentre dall'altro, collegato alle linee INT e INTA', vi è il processore.
Come già detto, abbiamo implementato una versione semplificata del protocollo di segnalazione degli interrupt. Di seguito è mostrato il grafico della simulazione, seguito dal relativo commento.
 Iniziamo col dire che il PIC viene inizializzato
portando a zero tutte le linee di interrupt e fornendo alimentazione (in verità
essa è fittizia ai nostri scopi) alle linee Vcc e GND. A quel punto le linee IRQ vengono poste a
zero.
Iniziamo col dire che il PIC viene inizializzato
portando a zero tutte le linee di interrupt e fornendo alimentazione (in verità
essa è fittizia ai nostri scopi) alle linee Vcc e GND. A quel punto le linee IRQ vengono poste a
zero.
Nella nostra simulazione, a 200ns circa, si alza IRQ 5, e di conseguenza il segnale INT. Posto che il processore sia pronto a servire la richiesta, inizia la prima pulsazione su INTA' e subito INT viene posta a zero, ed entro un lasso di tempo di circa 35ns il bus viene abilitato a scrivere l'identificativo della periferica. Osserviamo che, per ragioni dovute al meccanismo di cattura da parte del registro, il segnale sul bus diviene stabile solo dopo i 35ns. Infatti, dopo i primi 5 nel bus è scritto un valore non valido. Avremmo potuto imporre una tempificazione specifica nella progettazione del PIC per evitare il fenomeno, ma riteniamo sufficiente imporre, a livello progettuale, un'attesa minima di 40ns dal fronte di discesa di INTA' per la lettura di dati validi dal bus.
Come vediamo, il dato sul bus è la stringa 00000101, ossia 5. Alla seconda pulsazione INTA' il bus viene scollegato, e allo stesso tempo il test bench abbassa IRQ5, in quanto la periferica si ritiene ormai servita.
Continuiamo fino a poco prima di 800ns in una situazione di inattività. A quel punto, due periferiche, collegate a IRQ 5 e IRQ 2, sollevano un interrupt. Ad un primo esame, il codice che dovrà essere scritto sul bus dovrebbe essere 010, cioè IRQ 2. Durante la prima pulsazione INTA', però, anche IRQ 0, che ha priorità massima, si alza. E proprio verso i 900ns, in concomitanza (puramente casuale) con il termine della pulsazione di INTA', cioè sul fronte di salita, sul bus viene scritto 00000000, cioè proprio IRQ0. In questo caso, come osserviamo, a ciclo di segnalazione già iniziato avviene un cambiamento: IRQ 0 scavalca la priorità acquisita da IRQ 2. Una volta servito IRQ 0, il ciclo si riavvia con IRQ 2.
Facciamo una precisazione: il fatto che l'interrupt di IRQ 0, a massima priorità, venga servito, significa esclusivamente che l'interrupt viene rilevato dal sistema e che la CPU si prepara ad eseguire la appropriata ISR. Quando il ciclo di segnalazione termina, ci si aspetta che il processore esegua la ISR e poi sia nuovamente pronto ad eseguire una nuova ISR. Proprio quando il ciclo di segnalazione di IRQ 2 termina, viene eseguito subito un nuovo ciclo di segnalazione per IRQ 5, quando il processore sta ancora servendo IRQ 2. Il processore serve la richiesta non sapendo se si tratta di un IRQ inferiore o superiore (che andrebbe servito subito). Dunque il senso del PIC rischia di perdersi se la CPU si fa interrompere da interruzioni di priorità inferiore.
La soluzione a questo problema, in applicazioni pratiche, è il settaggio della maschera. Tuttavia, il PIC qui implementato non è da scartare. Un dispositivo che funziona in questo modo può rispondere a tutte le richieste di interrupt in arrivo e poi schedularle in una coda a priorità, o comunque decidere quando accettare nuove richieste dal PIC ritardando l'acknowledgement.
|
| Appunti su: |
|