|
| Appunti informatica |
|
|
| Appunti informatica |
|
| Visite: 1424 | Gradito: |
Leggi anche appunti:SchedulingScheduling Con Scheduler o Schedulatore si intende generalmente il Il meccanismo di simulazione e l'architettura ad oggetti di ASIMIl meccanismo di simulazione e l'architettura ad oggetti di ASIM 1.1 Il Descrizione del Programma di SimulazioneDescrizione del Programma di Simulazione 1 Introduzione Lo scopo |
 |
 |
Sistemi Operativi
Nella scorsa lezione abbiamo visto i metodi di allocazione ed in particolare quello più semplice possibile noto come allocazione contigua; tale metodo permette di tener conto della allocazione di un file in modo molto semplice: basta considerare il numero di blocco assoluto nell'ambito del disco da cui inizia il file ed il numero di blocchi consecutivi del file, cioè la sua lunghezza. In pratica però questo metodo non si utilizza perché richiede per garantire la contiguità del file in memoria la individuazione di un buco (numero di blocchi consecutivi) idoneo ed inoltre da problemi quando il file cresce di dimensioni perché presuppone lo spostamento dello stesso all'interno del disco; presenta inoltre il problema della frammentazione esterna che è lo stesso che si crea con la gestione della memoria partizione variabili. Bisogna utilizzare allora dei tipi di allocazione diversa. Vediamoli:
-ALLOCAZIONE LINKATA (vedi fig. 11.4 pag. 364 Silberschatz)
con questa tecnica nel descrittore di file, o meglio, nella tabella al cui entry punta il descrittore di file, abbiamo ancora il blocco di inizio del file così come nella allocazione contigua, però invece di avere il numero di blocchi consecutivi, i vari blocchi sono linkati mediante puntatori che sono contenuti nei blocchi stessi (si tratta quindi di una lista a puntatori i cui elementi sono i blocchi del disco). Per percorrere il file basta quindi entrare nel primo blocco e poi utilizzare i vari puntatori che si trovano in posizione standard nei blocchi. Con questo metodo si risolvono parecchi problemi visti prima perché non c'è più frammentazione esterna (alloco il file usando i blocchi così come li trovo senza bisogno di compattare), posso risalire in modo semplice al file occupando poco spazio (problema molto importante). Essa comporta comunque alcuni inconvenienti minori però della necessità di spostare il file (allocazione contigua); un primo inconveniente si vede tenendo conto del fatto che un sistema operativo prevede la tecnica di accesso sequenziale e quella di accesso diretto (per l'allocazione contigua abbiamo visto che sono entrambe ben supportati); per l'accesso sequenziale ho una notevole semplicità per l'allocazione linkata, mentre la tecnica diretta da grossi problemi perché si implementa comunque tramite un accesso sequenziale (per accedere al blocco 27 devo accedere a tutti i 26 blocchi precedenti per trovare il ventisettesimo puntatore); non posso più accedere al blocco tramite una somma (allocazione contigua) ma devo comunque percorrere una lista. Tale tecnica quindi non permette l'accesso diretto ai file perché presuppone dei tempi di accesso insostenibili. I sistemi operativi che la adottano usano anche un'altra tecnica a seconda del tipo di accesso. Per motivi di sicurezza uso anche un puntatore all'indietro per evitare problemi nel caso in cui si spezzi la catena perché ad esempio si perde un blocco del file. Volendo sintetizzare :
VANTAGGI: Semplicità di esprimere la posizione del file nella directory, velocità di accesso sequenziale
SVANTAGGI: Non utilizzabile per l'accesso diretto, perdita di spazio nel blocco per il puntatore (minimo),
inaffidabilità dovuta alla possibilità di perdere il file per interruzione della lista
(parzialmente ridotta introducendo una doppia lista linkata)
-ALLOCAZIONE LINKATA CON FAT
Alcuni sistemi come MS-DOS usano una variazione della allocazione linkata per permettere anche l'accesso
diretto. Per fare ciò si spostano i puntatori dei vari blocchi sul disco. In particolare memorizzo in alcuni blocchi di disco le catene di tutti i puntatori che stanno sul disco (vettore dei puntatori o File Allocation Table o FAT). Per maggiore chiarezza facciamo riferimento alla figura 11.5 di pag.366
Con tale sistema percorro sempre una lista a puntatori, ma invece di trovarla nei vari blocchi del disco, la trovo in alcuni blocchi speciali che si trovano in testa al file. Questo è già un notevole vantaggio perché per scoprire tutti questi puntatori dovrò leggere al massimo tutti i blocchi che contengono l'intero vettore indipendentemente dal fatto di dover scorrere una lista a puntatori fatta da 100, 200 o 300 blocchi perché tutti i puntatori si troveranno in quel vettore che occupa comunque pochi blocchi. Tutto ciò si migliora ancora di più facendo in modo che il sistema operativo metta tutti questi puntatori nella RAM (cacheing) nel momento in cui inseriamo ad esempio il dischetto nell'unità fisica. Quindi percorrerò una lista a puntatori che si trova in memoria e non sul disco (questo è ciò che fa MS-DOS). Questa modifica pur presupponendo una perdita di RAM per memorizzare la FAT permette di supportare l'accesso diretto.
Sintetizzando :
Sul disco esistono uno o più blocchi ben individuati che contengono un vettore di puntatori di lunghezza pari al numero di blocchi sul disco. Il vettore viene usato per contenere le liste a puntatori delle posizioni dei blocchi che appartengono ad uno stesso file. Ogni lista ha la testa nell'elemento della directory relativo al file di cui esprime l'allocazione.
Osserviamo inoltre che con questa tecnica esiste un particolare file linkato che è il file dei blocchi liberi; avrò quindi un numero di liste pari al numero di file caricati sul disco più 1; la lista in più e quella che collega i blocchi liberi. Questo permette di gestire in modo semplice lo spazio disponibile perché quando servono dei blocchi basta staccarli dalla lista dei blocchi liberi e quando si cancella un file basta collegare la catena di puntatori di quel file a quella lista. In realtà quella lista non viene mai visitata perché in entrambi i casi faccio riferimento alla sua testa perché, ad esempio prendo sempre i primi blocchi liberi e non gli altri.
La tecnica di allocazione dedicata a comunque dei problemi per dischi di grossa capacità; facciamo un piccolo calcolo: immaginiamo di avere un disco di 1 giga con blocchi di 1 k; ci sono quindi un milione di blocchi e quindi un vettore di un milione di puntatori di quattro byte ad esempio (ne basterebbero 3 per indirizzare un milione di blocchi, però 4 è lo standard); servirebbero quindi 4 megabyte di RAM per la FAT
(è un discorso estremizzato perché si usa la clasterizzazione per 4 blocchi consecutivi in un settore, quindi servirebbero molti di meno).
Per risolvere tale problema si usa la seguente tecnica :
-ALLOCAZIONE INDICIZZATA
E' la tecnica usata anche da UNIX; all'atto di allocare un file si crea un blocco che contiene tutti i puntatori di quel file; quando voglio risalire all'allocazione del file sul disco devo sapere dove è questo blocco di puntatori perché con esso risolvo tutti i problemi (vedi fig. 11.6 pag.367).
Troviamo una tabella le cui varie entry vengono puntate dai descrittore di file; c'è poi un puntatore che dice quale è il blocco indice (in UNIX è l'i-node) che contiene la lista degli puntatori.
Dobbiamo comunque risolvere dei grossi problemi legati al numero di puntatori e quindi allo spazio che devo associare per gestire file di grandi dimensioni o anche di dimensioni molto piccole. Potrei pensare di mettere un blocco indice di una certa dimensione, ma ciò limiterebbe la massima lunghezza di un file. Anche con la tecnica dei cluster avrei piccole dimensioni per i file. Potrei pensare di mettere due blocchi indice, ma nel caso di file brevi perderei due blocchi per dei puntatori non utilizzati. Si è visto che non conviene fissare il numero di puntatori, ma piuttosto conviene usare dei blocchi indice variabile a seconda di quanti ne servono. Si potrebbe realizzare una lista linkata di blocchi indice: dei 20 puntatori del blocco indice, ad esempio, 19 puntano a blocchi dati ed il ventesimo punta ad un altro blocco indice di 20 puntatori e così via. Con questo sistema non ho più vincolo sulla dimensione massima del file però ho di nuovo problemi per l'accesso diretto su file molto lunghi (è sempre una lista linkati) perché se i puntatori che mi interessano sono nell'ultima tabella devo comunque leggere tutte le tabelle. Si usa hanno allora una soluzione diversa:
-PUNTATORI MULTILIVELLO
Nel vettore di puntatori si trovano oltre a puntatori a dati anche puntatori a blocchi. E' diversa dalla lista linkata perché i puntatori non si trovano più nel blocco seguente e quindi si riduce il numero massimo di accessi. Nell'i-node di UNIX (versione BSD più diffusa) ci sono 15 puntatori di 4 byte (60 byte su 64) di cui 12 puntano a blocchi dati del file (molte versioni hanno 4 Kb per blocco e quindi 48 Kb per il file ); il tredicesimo puntatore punta ad un blocco indice di livello 0 (puntatori a soli blocchi dati), il quattordicesimo ad un blocco indice di livello 1 (puntatore a puntatori di blocchi indice), il quindicesimo ad un blocco indice di livello 2. Abbiamo quindi al massimo un accesso indiretto a 3 livelli.
Facendo un confronto possiamo dire che il metodo di allocazione condiziona molto le prestazioni che sono legate alle modalità di accesso al file e alla sua dimensione:
L'ALLOCAZIONE CONTIGUA ha buone prestazioni per accesso sequenziale e diretto indipendentemente dalla dimensione del file. Comporta però problemi dovuti alla necessità di spostare i file.
L'ALLOCAZIONE LINKATA va bene per accessi sequenziali al file.
L'ALLOCAZIONE INDICIZZATA va bene per entrambi gli accessi con prestazioni che decrescono con la dimensione del file perché devo utilizzare la tecnica a multilivello.
A questo punto ci resta da trattare la modalità di gestione dello spazio libero che deve essere comunque coerente con la tecnica di allocazione dei file utilizzata (ad esempio come avveniva con la FAT).
Il modo più semplice da utilizzare è il BITMAP consistente nell'associare ad ogni blocco un bit che vale 0 se il blocco è occupato e 1 se è libero. Scorrendo la BITMAP in cerca di un blocco libero basterà fermarsi al primo 1 trovato. Offre il vantaggio di favorire la scelta di blocchi adiacenti per allocare un file (all'inizio il disco è vuoto e la BITMAP è formata da tutti 1, poi alcuni blocchi si occupano però mediamente è abbastanza probabile che ci siano blocchi liberi adiacenti);ha però il problema che la BITMAP deve trovarsi in memoria. Supponendo di avere un disco da 1 Gb con 1 Kb per blocco avremo una BITMAP di 1.000.000 di bit (circa 130 Kb). Quindi tale sistema si usa per piccoli dischi (meno di 1 Gb); un altro problema è quello di esaminare velocemente la BITMAP. E' necessario per non avere un algoritmo particolarmente pesante che il processore abbia codici operativi ad hoc ( ad esempio il 68020 ); infatti in caso contrario dovremmo accedere ad un byte della BITMAP, controllare se è formato da tutti zeri ed in caso contrario calcolare la posizione del primo 1 ad esempio con una serie di ROTATE e di aggiornamenti di un contatore.
Riassumendo :
-TECNICA BITMAP
Esiste un vettore di bit ( BITMAP ) con tanti bit quanti sono i blocchi del disco e ogni bit indica se il corrispondente blocco è libero o meno. Con questa tecnica il braccio del disco si deve muovere poco (migliorano i tempi di accesso). E' la tecnica usata da Apple Macintosh con il 68020.
VANTAGGI : Semplice ricerca di blocchi liberi adiacenti.
SVANTAGGI : Devo avere il BITMAP in memoria; necessito di codici operativi opportuni.
Abbiamo già visto prima il metodo della lista linkata :
-LISTA LINKATA
Tutti i blocchi liberi sono linkati in una lista ed un puntatore Testa della lista permette l'accesso al primo blocco;
SVANTAGGIO : scarsa efficienza dovuta al tempo necessario a percorrere la lista che richiede operazioni
di I/O.
Un miglioramento di tale tecnica è il seguente :
-RAGGRUPPAMENTO
Riduciamo gli svantaggi della lista linkata in quanto teniamo raggruppati più puntatori a cui possiamo accedere con un'unica operazione di I/O. In pratica ogni blocco della lista punta oltre che al successivo blocco ad un gruppo di blocchi liberi (quindi abbiamo più puntatori che puntano a blocchi liberi direttamente ed uno che punta al prossimo blocco di puntatori);in questo modo si riduce il tempo per la individuazione degli indirizzi dei blocchi liberi richiesti per allocare un file.
Sia col RAGGRUPPAMENTO che con la LISTA LINKATA però non facilito l'allocazione del file su blocchi liberi contigui perché non è detto che quei puntatori puntino a blocchi adiacenti.
In realtà la cosa migliore da fare è di usare il seguente metodo:
-CONTEGGIO
La lista dei blocchi liberi non linka i blocchi che sono preceduto da altri blocchi liberi contigui. Per ogni blocco della lista si memorizza oltre al puntatore al blocco successivo anche un contatore che indica il numero di blocchi liberi che gli sono contigui per indirizzi crescenti o decrescenti.
Nel momento in cui stacco i blocchi liberi dalla lista cerco di staccarli in modo che siano adiacenti.
VANTAGGIO : si riduce il tempo di percorrenza della lista; è più agevole trovare i blocchi contigui che
sono da preferire in sede di allocazione di un file.
Ritorniamo ora allo schema seguente :
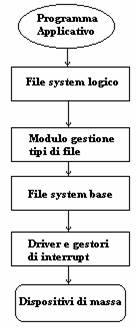
abbiamo visto quale è la struttura a blocchi del file system; ora abbiamo visto le varie tecniche di gestione del modulo di gestione dei tipi di file. Abbiamo detto che l'applicativo effettua l'accesso facendo riferimento al numero di blocco relativo all'interno del file che poi dovrà essere trasformato in numero di blocco assoluto all'interno del disco. Ciò si realizzerà consultando le informazioni sulla allocazione del file; la routine che effettua questa assolutizzazione tiene conto quindi della tecnica di allocazione e da l'indirizzo assoluto all'interno del disco. A questo punto il file system base deve trovare fisicamente questo indirizzo facendo riferimento a cilindro, traccia e settore per comandare il driver e realizzare l'accesso.
Diamo per scontata la conoscenza del supporto fisico disco (vedi Fig. 2.1 pag.43 ): abbiamo un cilindro, più superfici, le tracce ( 2 per faccia del disco) ed i settori. Quindi l'indirizzamento è tridimensionale e devo pilotare il movimento del braccio in modo da ottimizzare i tempi di accesso ordinando le varie richieste.
Per passare da un indirizzo assoluto di blocco ad un indirizzo fisico espresso da cilindro, traccia e settore basta sapere le caratteristiche del disco cioè il numero di cilindri n, numero di facce (di solito numero di dischi -2 perché non si usano la faccia superiore e quella inferiore) ed il numero di settori.
Si tratta di trovare i numeri i, j, k tali che :
b= k + j s + i t s dove s è il numero di settori per traccia,
t è il numero di tracce per cilindro
i è l'indirizzo di cilindro
j è l'indirizzo di traccia
k è l'indirizzo di settore
b è il numero di blocco assoluto
Ricordiamo che i tempi di accesso al disco sono due :
Tempo di SEEK impiegato per spostare radialmente il braccio per posizionare le testine sul cilindro
Tempo di LATENZA cioè il tempo che devo aspettare prima che il settore passi sotto la testina
( il tempo di SELEZIONE della testina sulla superficie è un tempo elettronico ed è trascurabile ).
In realtà la testina legge tutti i settori che gli passano sotto; ogni settore ha un MARK di inizio,
un indirizzo espresso di nuovo come la tripla cilindro, traccia e settore ed i dati che ci interessano.
Quindi basta comparare quei due indirizzi; in realtà la testina legge sempre i dati e ricopre sempre lo
stesso buffer; quando quei due indirizzi sono uguali si ha l'OK, il buffer non viene più ricoperto e
gli ultimi dati letti sono quelli cercati.
Se il disco è a teste mobili posso ottimizzare rispetto al Tempo di SEEK, rispetto al Tempo di LATENZA o rispetto ad entrambi. Conviene ottimizzare rispetto a quello di SEEK che è maggiore (tempo di spostamento
meccanico). Se invece il disco è a teste fisse ho tante testine quanti sono i cilindri e quindi il braccio non si
sposta mai ( non ho quindi tempo di SEEK ). Esistono poi dischi in cui il numero di testine è leggermente minore del numero di tracce e in cui lo spostamento è quindi molto minore. Per un il disco a teste fisse si ottimizza quindi rispetto al tempo di LATENZA (di solito considerando che esso è piccolo non vale la pena
di ottimizzare niente ).
Nel momento in cui mi pongo il problema di ottimizzare i tempi di accesso del disco, ho già una richiesta di accesso che ha specificato se è di input o di output ed ho già individuato il blocco a cui accedere in quanto conosco cilindro, traccia e settore. Conosco inoltre il buffer di memoria cui fare riferimento per l'operazione ed anche il numero di byte che voglio leggere o scrivere. (di solito è un numero fisso).
Per realizzare questa ottimizzazione si usano vari algoritmi di scheduling :
FCSF (First Come First Served)
E' il più semplice possibile ed equivale a non effettuare alcuno scheduling (siamo a livello del File system di base ). Non ottimizza sul tempo medio di servizio non effettuando alcun tipo di ordinamento.
(vedi Fig. 12.1 pag. 385)
SSTF (Shortest Seek Time First)
E' paragonabile all'algoritmo SJF della CPU. In questo caso servo la richiesta più vicina al punto in cui mi trovo sul disco. Ottimizzo sullo spostamento delle testine e quindi sul tempo di SEEK. Può dare luogo ad
attesa infinita (STARVATION) perché una richiesta molto lontana rispetto al punto in cui mi trovo potrebbe non essere mai servita. Quindi non è un algoritmo ottimale. (vedi Fig. 12.2 pag. 387)
SCAN (Algoritmo dell'ascensore)
Lo abbiamo già visto ed è quello ottimale perché elimina la STARVATION evitando di servire una richiesta
relativa allo stesso punto. (vedi Fig. 12.3 pag. 388)
Ne esistono alcune varianti che ora vediamo:
C-SCAN (Circular Scan)
Ha un tempo di attesa più uniforme; la testina serve le richieste a mano a mano che le incontra ma una volta
raggiunta l'estremità del disco torna subito all'inizio senza servire le richieste che incontra al ritorno ( è come se considerasse il disco circolare, come se la prima traccia seguisse l'ultima ). Ottimizza sul moto del disco che non è più a scatti. (vedi Fig. 12.4 pag. 389)
LOOK e C-LOOK
Si tratta di una variante degli algoritmi SCAN e C-SCAN in cui la testina non giunge mai alle estremità del disco ma si sposta solo fino all'ultima richiesta in ciascuna direzione.
(vedi Fig. 12.5 pag. 389)
Abbiamo visto gli algoritmi di scheduling più comuni per quanto riguarda la gestione dell'ordinamento di servizio di richieste di accesso a blocchi di settore. Facciamo ora un confronto tra questi algoritmi.
Gli algoritmi che abbiamo visto sono il client server (che è il più banale) che presuppone un ordinamento delle richieste pendenti in base all'arrivo di queste. Poi abbiamo visto l'algoritmo che minimizza il tempo di seek, cioè è quello in cui lo scheduling dà maggiore priorità alla richiesta che è relativa ad un cilindro prossimo a quello in cui si sta effettuando una operazione di lettura o scrittura ed abbiamo visto che questo ottimizza il tempo di seek ed equivale all'algoritmo della CPU per scelta del processo con routine più breve e fa in modo di trascurare le richieste di cilindri lontani se in quel momento abbiamo richieste di cilindri più vicini. Poi abbiamo visto l'algoritmo dell'ascensore e le sue varianti (classico, circolare, e quello che ottimizza il movimento del braccio dal cilindro più interno a quello più esterno e viceversa).
Detto questo è chiaro che possiamo fare dei
Criteri di scelta dell'algoritmo di scheduling
L'elemento da tenere conto quando facciamo una scelta sull'algoritmo è quello che riguarda il carico del disco. Infatti se facciamo riferimento ad un sistema il cui disco è scarico tutti gli algoritmi vanno bene poiché non esiste una lista di richieste pendenti e quindi non nasce nessuna esigenza di effettuare una scelta delle richieste che sono in attesa.
Quindi nei piccoli sistemi tutti gli algoritmi vanno bene e quindi anche l'algoritmo FCFS va bene, viceversa la tecnica di scheduling viene applicata ai grossi sistemi dove si possono concentrare una grossa richiesta di utenza.
Anche se ci sono molte richieste di utente, gli algoritmi individuati funzionano più o meno bene in relazione a quella che è la
- Modalità di allocazione dei file.
Se la modalità di allocazione dei file fosse quella continua, a questo punto tutte le richieste si concentrano in zone più o meno prossime e quindi di conseguenza non ha molto senso ottimizzare gli spostamenti e in questo caso i file vengono fatti in una versione linkata. Questo non esclude il fatto che se in una versione continua, abbiamo due file entrambi allocati in modo continuo e si alternano le richieste di accesso al primo e al secondo comunque si richiede un lieve spostamento dall'uno all'altro.
Un altro elemento fondamentale che condiziona molto l'opportuna scelta dell'algoritmo è come sono allocati i file directory e i blocchi indice. Infatti se i file directory ed i blocchi indice sono contenuti in dei cilindri destinati a contenerli è chiaro che si ottiene un excursus frequente di tracce da quelle posizioni preferenziali alle posizioni dei file e quindi di conseguenza ritorna rilevante l'opportuna scelta dell'algoritmo dell'accesso. Quindi, sostanzialmente sono questi i tre elementi che possono far preferire un algoritmo d'accesso che è la routine dell'ascensore con lo scambio circolare che viene utilizzato appunto quando i dischi sono molto carichi si crea una notevole dinamica.
Oss. Si tenga conto che questo algoritmo è implementata dalla parte bassa del file system, cioè nei grossi sistemi il S.O. si rivolge al controller e poi sarà questo che si preoccuperà di implementare l'ordinamento con delle routine di servizio e ovviamente gestirà il driver.
In altri grossi sistemi di solito il file system rinuncia a fare una richiesta perché l'ordinamento richiesto dal file system potrebbe andare in contraddizione con quello che è l'ordinamento di richieste che farebbe il controller, questo perché il controller è ottimizzato per fare un certo ordinamento ed il S.O. ne fa un altro passadogli le richieste una alla volta e quindi il controller in questo modo non ha più motivo di sussistere. Quindi chi ha implementato l'algoritmo del controller lo ha fatto tenendo conto delle caratteristiche di quel disco e tutta questa problematica viene bypassata e trascurata dal S.O.
Nel momento in cui facciamo l'ordinamento delle richieste d'accesso ad un disco, possiamo ottimizzare sia rispetto al tempo di latenza che a quello di seek e il compito degli algoritmi che abbiamo studiato fanno riferimento esclusivamente al tempo di seek.
In realtà nei dischi a testina mobile non si fa l'ottimizzazione rispetto al tempo di latenza, mentre per quelli a testina fissa non ha nessun senso l'ottimizzazione rispetto al tempo di seek e quindi l'ordinamento viene fatto rispetto ai settori per abbattere i tempi di latenza.
Ricordando come è fatto un disco (vedi FIG), nel caso in cui il disco sia a testine fisse il braccio
|
|
è fisso e le testine sono tutte posizionate sulle varie tracce e quindi sembra evidente che in realtà, per come è fatto il sistema, in un certo istante sotto le testine troviamo sempre, indipendente dal cilindro e ai settori cui appartengono, tutti i settori che occupano la stessa posizione per tutte le tracce.
Quello che vogliamo dire è che facendo riferimento ad una singola traccia questa conterrà i vari settori numerati in un certo modo, ora in un certo istante sotto questa testina c'è p. es. il settore numero sette ed analogamente per le testine poste al di sotto di questa. Ora questo è vero se abbiamo un singola testina per braccio, ma se immaginiamo che in questo braccio prenda tutti i cilindri questo significa che abbiamo una testina per ciascuna traccia e quindi contemporaneamente sotto tutte le testine in un certo istante abbiamo tutti i settori che hanno lo stesso indirizzo relativo nell'ambito della traccia a cui appartengono, quindi possiamo leggere contemporaneamente tutte le richieste indipendentemente dal cilindro a cui appartengono e dalla traccia a cui appartengono che fanno riferimento allo stesso numero di settore. Quindi l'ordinamento bisogna essere fatto rispetto a questo numero e quindi di conseguenza tutte queste richieste possono essere lette (sempre che la larghezza di banda del canale lo consenta) in parallelo. Questa è la logica in cui vengono soddisfatte le richieste.
Oss Nella realtà quindi non si leggeranno tette le testine contemporaneamente ma viene attivata solo la testina per cui abbiamo una richiesta di lettura e scrittura.
Naturalmente questo tipo di scheduling può essere applicato anche ad un disco a testine mobili, in tal caso ordineremo tutte le richieste in modo tale che scelto un cilindro che è quello in cui ci siamo posizionati per ottimizzare il tempo di seek, andiamo a leggere in sequenza tutte le richieste che sono relative(in parallelo e quindi dipende sempre dalla larghezza di banda del canale) alla stessa posizione di settore indipendentemente dalla traccia a cui appartengono i suoi bracci.
Questo beneficio e praticamente irrilevante nel disco a teste mobili, perché tutte le richieste a parità di settore devono essere riferite allo stesso cilindro ( che è uno solo), quindi non ce ne sarà nessuna e quindi questo tipo di ottimizzazione non ha senso. Se invece abbiamo il disco a testine fisse dato che è indifferente per le richieste a parità di settore a quale cilindro appartengono (e quindi ne abbiamo più di uno ) allora li possiamo ordinare e servirle contemporaneamente.
Quindi questo tipo di algoritmo vale solo per i dischi a testina fissa :
-Scheduling di settori
Lo scheduling di settore si applica a dischi molto carichi a testine fisse oppure a dischi con controllori dotati di memoria cache in cui viene letta tutto un cilindro alla volta.
Abbiamo detto che un disco non solo viene utilizzato per essere il supporto in cui viene memorizzato il file system, ma è anche il supporto che serve per implementare la memoria virtuale ed anche per implementare lo spazio di swap.
Oss. Ricordiamo che per la gestione della memoria centrale, qualunque sia la tecnica utilizzata, abbiamo sempre il problema dello swap, poiché in un certo istante (rispetto a quello che è lo spazio di memoria RAM) abbiamo l'esigenza che alcuni processi attivi siano swappati su memoria di massa.
E' chiaro che nel caso di memoria virtuale swappare significa portare tutte le pagine e comunque stare nello spazio fisico di memoria virtuale, ma se tralasciamo il discorso della memoria virtuale abbiamo bisogno di uno spazio di swap su cui andiamo a riportare il processo.
Quindi abbiamo il problema di come gestire questo spazio di swap, la quale gestione non è detto che debba avvenire con le stesse modalità con cui avviene la gestione di uno spazio del disco che è destinato a contenere il file system, infatti è evidente che le esigenze che abbiamo per la gestione di uno spazio di swap sono certamente diverse rispetto alle esigenze per la gestione dello spazio del file system.
Il problema della locazione dei file nella memoria di massa è un problema che cerca di ottimizzare in qualche modo lo spazio di massa.
Abbiamo detto che la locazione contigua non ci va bene per la gestione di memoria di massa per due motivi.
Il primo è dovuto ad una frammentazione interna e quindi in realtà fa sprecare memoria di massa, poiché il problema della ricompattazione è da recuperare e quindi non ottimizziamo la disponibilità di spazio che c'è in memoria di massa.
Il secondo motivo è dovuto al problema di dover continuamente spostare il file per fare spazio.
E quindi abbiamo avuto l'esigenza di fare altri metodi di allocazione, che tutto sommato abbassano il trasferimento. Infatti se dobbiamo trasferire un file che è allocato in modo continuo riusciamo a trasferire con maggiore velocità l'intero file attraverso il canale poiché leggiamo grossi blocchi sfruttando la larghezza di banda del canale e non dobbiamo continuamente spostare le testine, mentre se dobbiamo effettuare il trasferimento di un intero file che si trova in un a allocazione linkata indicizzata impiegheremo più tempo, poiché dovremo trasferire meno quantità di dati e dovremo periodicamente spostare il braccio.
Dal momento in cui andiamo a scrivere e a leggere in memoria di massa, nel caso del file system è ben difficile che abbiamo la possibilità di scrivere un intero file ma probabilmente dovremo effettuare accessi a parti di file ma questo tutto sommato non è un grosso problema. Si capisce che la questione è completamente diversa se trasferiamo un file con il quale abbiamo implementato lo spazio di swap, infatti in quel momento dobbiamo prendere tutta l'area programmi del processo e lo dobbiamo portare velocemente in memoria RAM perché è verificato l'evento in cui il processo è diventato ready e quindi deve competere alla funzione della CPU.
Quindi lo spazio di swap va gestito con delle tecniche che non sono quelle di gestione dello spazio destinate al file system perché gli obbiettivi prestazionali che si prefigge sono diversi, quindi a noi non interessa che lo spazio di swap viene sfruttato male ma ci interessa che la velocità di trasferimento swap-in swap-out siano alte, poiché tutto sommato un processo nello spazio di swap c'è per un tempo breve e quindi non è un fatto abbastanza statico.
Un altro elemento da mettere in evidenza è che l'allocazione contigua ci dava fastidio perché generava una frammentazione esterna, ma in questo caso è una frammentazione esterna abbastanza statica.
Infatti se carichiamo un certo file e poi lo leviamo sfruttiamo male lo spazio sul disco, ma in questo caso non abbiamo esigenza di ricompattare i buchi che si creano poiché si ha una dinamica così alta che possiamo dire che questi buchi si "ricompattano da soli".
Quindi tipicamente lo spazio di swap viene gestito con una locazione che è o contigua oppure lo è quasi, cioè il programma che viene swappato occupa una serie di settori e quindi blocchi consecutivi e viene restituito in un certo numero di blocchi di lunghezza prefissata(ma non tutti uguali) in modo tale da ridurre il problema della frammentazione.
Oss. Esistono S.O. i quali operano in modo diverso, in cui lo spazio di swap viene gestito come è gestito il file system (e questo è come opera windows dove appunto lo spazio di swap è gestito come il file system), nel senso che le routine che permettono di operare su spazio di swap sono le stesse che permettono di operare sul file system. Il che significa dire che dal momento in cui andiamo a swappare un programma dobbiamo creare un file, così come avviene nel file system, e dobbiamo trovare lo spazio di allocazione con una normale routine che utilizza il file system e questo significa che non è una partizione a parti. Anche in questo caso abbiamo una organizzazione a directory e sottodirectory (cioè nella directory abbiamo tutti i file di swap dei vari processi).
Tornando al discorso della separazione dello spazio di swap e allo spazio destinato al file system. Questo è quello che avviene in UNIX, dove l'allocazione non è contigua ma è a pezzi e nel momento in cui il programma viene swappato esiste un vettore di puntatori di swap il quale punta ai vari pezzi
|
|
|
(vedi FIG) ed ognuno di questi è di 512 Kb tranne l'ultimo che è di grandezza variabile ed in questo caso la frammentazione interna è bassa
Questo riguarda la parte dello swap dell'area istruzione del programma (cioè il codice, quello che è chiamato il " testo " del programma ).Quindi dal momento in cui un processo viene creato gli viene anche dedicato uno spazio di swap su cui si appoggerà.
Oss. Quindi questo spazio di swap non è che gli viene creato e tolto dinamicamente, ma è un fatto che nasce con il processo.
Per quanto riguarda la tabella relativa all'area dati i vari i vari segmenti non sono fissati a 512 kb ma sono di 16-32-64k, cioè sono segmenti diversi di dimensione multipla e quindi lo spazio di swap legato ai dati per programmi piccoli occupano poco spazio.
Quindi per la gestione dello spazio swap sia le regole di allocazione che le routine che vengono utilizzate sono diverse da quelle del file system .
Oss. In realtà non ci sarebbe neanche bisogno di implementare uno spazio di swap alla parte testo del processo poiché comunque il codice risiede nel file system.
Per quanto riguarda il codice nel caso in cui si dovrebbe swappare un programma con questa tecnica dovremmo prendere il codice e dall'area del file system copiarlo nell'area di swap e da lì portarlo dentro ogni volta che ci serve e quindi lo swap-out non lo facciamo mai poiché il codice è immutabile durante l'esecuzione.
Se invece di fare ogni volta lo swap-in nell'area di swap per quanto riguarda la parte di codice, possiamo fare direttamente lo swap-in dal file system e di conseguenza risparmiare ulteriormente tempo.
Quello che necessita invece un continuo swap e quello dell'area dati, poiché sul file system l'area dati non esiste, ma su questo abbiamo semplicemente i valori delle variabili da inizializzare e non quelle definite durante l'esecuzione del programma e quindi comunque abbiamo bisogno di uno spazio che non è quello del file system.
Particolari tecniche di miglioramento delle prestazioni o dell'affidabilità dei dischi.
Prima di parlare di affidabilità introduciamo il concetto di interliving che ci sarà utile per sviluppare l'affidabilità. Se abbiamo una serie di banchi di memoria in un calcolatore gli indirizzi non sono numerati in sequenza ordinata in un chip e poi nel secondo chip continua la sequenza del precedente, ma si mette l'indirizzo zero nel primo chip , l'indirizzo uno nel secondo chip etc. questo perché qualora andiamo a leggere una word anziché fare un accesso in sequenza di più byte all'interno dello stesso chip, possiamo lavorare in parallelo e sfruttiamo la banda del canale in cui l'address bus non è a otto bit ma a 32 bit.
Esempio
Supponiamo di avere quattro chip (vedi FIG) e supponiamo che il parallelismo della parola sia di 1
byte, cioè l'indirizzo uno è 1 byte, l'indirizzo due è un byte, etc.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Ora se vogliamo accedere all'indirizzo p.e. 1101000110 allora gli ultimi due bit vengono eliminati perché abbiamo quattro chip (se ne avessimo avuto otto chip avremmo eliminato tre bit (banale ?)), l'indirizzo che rimane lo mettiamo sull'address bus e seleziona l'indirizzo zero, uno etc. ed in questo modo possiamo scaricare o prelevare sul data bus tutta la word, questo si chiama progetto di memoria interlacciata e il metodo è di interliving di memoria.
Questa particolare architettura può essere sfruttata per l'affidabilità sui dischi e si fa questo particolare ragionamento, invece di mettere un disco di grosse capacità in cui il blocco è di 4-8 kb, possiamo costruirci una batteria di dischetti di bassa capacità e che abbiano lo stesso numero di blocchi di quello grande (p.e. blocchi di 4kb ma suddivisi in 4 dischi dove il primo kb è sul primo disco , il secondo kb sul secondo etc.). Quindi quando andiamo a leggere un blocco del disco di grosse capacità dobbiamo leggere tanti blocchi uno per ognuno dei dischi di piccole capacità i quali essendo interlacciati nel loro complesso fanno il grande disco.
Oss. Con il ragionamento fatto prima invece di avere un unico chip di memoria un registro di 32 bit , abbiamo 4 chip di memoria di cui su ognuno andiamo a leggere 8 bit. Nel caso dei dischi il ragionamento è analogo in quanto invece di avere un unico disco in cui andiamo a leggere un unico blocco di 4k , abbiamo 4 dischi in cui prendendo lo stesso indirizzo per tutti e 4 dischi adiamo a leggere il primo blocco del primo disco, il primo del secondo disco etc.
Questo ci consente di avere due grandi vantaggi:
1)Abbattiamo i tempi di accesso, poiché il trasferimento avviene in parallelo e i tempi li abbattiamo nella misura in cui disponiamo di un canale di banda adeguato.
2)Risparmio economico, poiché avere tanti dischi di piccole capacità costa meno rispetto ad un megadisco di grossa capacità.
Oss. La batteria di dischi si chiama RAID (o tecnica RAID cioè array di dischi)
Tecnica di inteliving di dischi
La tecnica più banale da fare, che però fa aumentare il costo perché aumenta al massimo la ridondanza, è quello di fare il mirroring (da mirror, specchio), cioè abbiamo due batterie di dischi ed ogni volta che scriviamo sulla prima, scriviamo anche sulla seconda.
Quindi abbiamo due batterie di dischi di cui uno è l'immagine speculare dell'altro, e questo fa si che in caso di crash non interrompiamo il lavoro, poiché possiamo comunque lavorare con l'altra batteria di dischi funzionante.
Oss. E' lo stesso discorso di una macchina che ha due CPU in cui nel caso di rottura di una CPU il sistema non si interrompe. Nel caso di rottura di una CPU le prestazioni decrescono, mentre nel caso di rottura di una batteria di dischi non si riducono le prestazioni ma l'affidabilità.
Tecnica con disco di parità
Un altro modo di lavorare sull'affidabilità è sempre basato sulla batteria di dischi però in questo caso anziché raddoppiare la batteria di dischi ne mettiamo uno sola in più (p.e. da due batterie di dischi invece di passare a 4 batterie(interliving) passiamo a tre batterie di dischi), questo è il concetto di parità mediante un disco di parità. Vediamo un
Esempio
Supponiamo di avere due batterie di dischi, vediamo come costruire il disco di parità.
Abbiamo il disco zero ed un settore sette di una certa traccia e di un certo cilindro, sul disco uno avrà anch'esso il settore sette della stessa traccia e dello stesso cilindro allora abbiamo un disco due che ha ancora il settore sette sempre della stessa traccia e dello stesso cilindro dove i bit che sono nel disco due sono i bit di parità dei bit omologhi che sono nel disco zero e uno(vedi FIG).
|
|
|
Quindi se il settore sette del disco zero è fatto dai bit 1101 e se il settore sette del disco uno è fatto dai bit 0110 allora il settore sette del disco due è dato da:
|
|
|
|
|
|
|
|
|
poiché questi sono i bit di parità rispetto ai bit omologhi.
Oss. Questa è detta parità trasversale e questo numero dipenderà dal numero di dischi che stiamo gestendo. Conviene applicare questa tecnica quando il numero di batterie di dischi è elevato.
Quindi dal momento in cui andiamo a scrivere su un certo disco dobbiamo ricalcolare la parità e scrivere sul disco di parità (si sfrutta la funzione XOR, cioè basta fare una XOR alla vecchia parità e ricalcolare la nuova parità)
Oss. Naturalmente il disco di parità può essere applicato anche alle tecnica di interliving.
S.O. distribuiti
Introduzione dei S.O. distribuiti
Sotto il nome di sistemi distribuiti si racchiude una moltitudine di argomenti che sono anche molto diversi tra di loro e che servono molte applicazioni in cui sono richieste delle elevate potenze di calcolo.
Le applicazioni di sistemi distribuiti su base geografica in cui l'applicazione e client-server, introduce il discorso di comunicazione su rete in cui sono collegate le varie unità di sistema . Questo discorso si rivolge ad un ambiente applicativo totalmente diverso e questo è un sistema in cui in realtà abbiamo tante macchine ed ognuno delle quali ha il proprio Kernel di S.O. e che nel loro complesso dovrebbero costituire (questi vari Kernel) quello che è il S.O. distribuito (cioè non esiste un unico Kernel ma esistono tanti Kernel presenti sulle macchine nel sistema).
Cosa ben diversa del parallel-computer che è una unica macchina che avrà più CPU ma ha un unico Kernel con un unico S.O..
Quindi una classificazione per i sistemi distribuiti sono:
1)Sistemi distribuiti su una base geografica, in cui abbiamo molte macchine e molte CPU ma distribuite geograficamente e connessi dalla network (cioè dalla rete);
2)Sistemi distribuiti ma concentrati in un punto dove comunque abbiamo lo stesso una serie di CPU tra di loro connessi;
I sistemi distribuiti nascono intorno agli anni '80, questi nascono sia con l'introduzione dei microprocessori che danno la possibilità di avere CPU a basso costo, sia perché nascono le reti di comunicazione, cioè nasce il modo per poter connettere diverse macchine.
Qualunque siano i sistemi distribuiti quello che li caratterizza rispetto ai sistemi centralizzati è il fatto di avere più CPU,(le quali possono essere contenute in unico box oppure saranno distribuite geograficamente ) le quali sono interconnesse in vario modo ed ovviamente ogni CPU è in grado di lavorare sul proprio segmento di codice e operare sui propri dati.
Oss. Il segmento di codice che opera sui propri dati potrebbe essere un segmento di codice che esegue un server di una applicazione in cui una parte client della applicazione stessa si è rivolta per avere un servizio, come potrebbe anche essere un segmento di codice di un processo di n processi cooperanti che servono a risolvere su una macchina (che nei fatti è concentrata in un unico box) una unica applicazione.
I sistemi distribuiti presentano molte architetture, molte aree applicative hanno S.O. che possono essere molto diversi, hanno diverse reti di comunicazione possibili tra le varie CPU e modelli elaborativi che possono anche essere molto diversi tra di loro.
I sistemi distribuiti sono nati in particolare per ottenere delle velocità di calcolo che non sono ottenibili con i sistemi concentrati.
Un'altra motivazione della nascita dei sistemi distribuiti è una motivazione di carattere economico poiché si era notato che il costo delle CPU non variava linearmente con la potenza offerta ma l'andamento era esponenziale (legge di Closch) cioè al raddoppio del costo la potenza offerta quadruplicava e quindi una rete come questa guardava anche al futuro sapendo che questa aveva tutte le potenzialità per crescere.
Un altro tipo di vantaggio è la programmazione parallela rispetto a quella sequenziale.
I svantaggi del sistema distribuito sono:
1)Scarso software di base ; solo adesso si sta sviluppando un software di base che è abbastanza stabile cioè che permettono lo sviluppo di applicazioni in rete ed accesso a banchi dati;
2)Ambienti di sviluppo e linguaggi di programmazione poco evoluti;
3)Modesta offerta di SW applicativo;
4)Overhead dovuto alle comunicazioni ed in particolare al software che gestisce la perdita di messaggi e gli errori;
5)Minore sicurezza dei dati dovuta alla condivisione;
Diamo ora delle definizioni.
Cominciamo col distinguere tra sistema distribuito in senso stretto e sistema parallelo.
-Sistema distribuito( in senso stretto ) : sistema costituito da più CPU variamente interconnesse che consentano a più utenti di lavorare contemporaneamente eventualmente in modo cooperativo.
-Sistema parallelo : sistema costituito da più CPU variamente interconnesse dedicato ad una singola applicazione che richiede una elevata velocità di calcolo.
Una classificazione maggiore dei sistemi distribuiti
Secondo la tassonomia di Flyn i sistemi distribuiti sono sistemi MIMD e possono suddividersi in:
-SISD (cioè una sola istruzione un solo dato), cioè sistemi in cui ogni CPU esegue proprie istruzioni su propri dati e quindi non esiste ne condivisione di istruzione ne condivisione di dati;
-SIMD (cioè una sola istruzione molti dati) , cioè sono sistemi in cui viene eseguita una istruzione alla volta però questa opera su un array di dati.
-MISD (cioè molti istruzioni un solo dato)
-MIMD(cioè molti istruzioni molti dati) cioè i sistemi distribuiti;
Quindi come prima abbiamo suddiviso i sistemi distribuiti come sistemi distribuiti in senso stretto e in parallelo, ora possiamo distinguere in sistemi multiprocessore e sistemi multicomputer, dove i sistemi multiprocessore intendiamo sistemi in cui ci sono tante CPU ed una memoria condivisa (comune), nei sistemi multicomputer invece abbiamo tante CPU ognuna con la propria memoria (locale) vedi FIG
|
|
|
E' evidente che quello che abbiamo chiamato sistemi distribuiti in senso stretto sono certamente sistemi multicomputer, mentre quello che avevamo chiamato sistemi paralleli sono i sistemi multiprocessore.
Un'altra classificazione per i sistemi distribuiti in senso lato
1)Sistemi strettamente connessi;
2)Sistemi lascamente connessi;
Dove per strettamente e lascamente connessi si intende la velocità con cui questi sistemi comunicano tra di loro:
Si dicono strettamente connessi quei sistemi che hanno vie di comunicazione che lavorano a grosse velocità, si dicono lascamente connessi quelle vie di comunicazione che lavorano a basse velocità.
I sistemi che comunicano a grande velocità hanno un bus in comune e quindi si dispone di una memoria comune e comunichiamo tramite un bus alla memoria.
Viceversa sono sistemi lascamente connessi sistemi che non condividono l'area di memoria e che comunicano tramite una rete(tipo rete locale o geografica).
Quindi questa distinzione è un modo diverso di riproporre ancora la classificazione prima introdotta poiché quello che abbiamo chiamato sistemi multiprocessore sono in realtà sistemi strettamente connessi, quello che avevamo chiamato sistema multicomputer sono sistemi lascamente connessi.
Abbiamo poi una classificazione sulla rete di comunicazione (cioè sul modo in cui sono connesse le CPU) e sono dati dai sistemi a BUS e quelli switch(commutati) e anche in questo caso i sistemi a bus sono sistemi strettamente connessi e quindi sistemi multiprocessore mentre quelli switch sono sistemi lascamente connessi e quindi sistemi multicomputer.
In figura abbiamo una struttura multiprocessore con struttura a bus in cui abbiamo tante CPU (con la cache della CPU) con unico bus.
|
|
|
|
In figura abbiamo un sistema multiprocessore in cui abbiamo tanti processori e tante memorie che sono condivise da tutti i processori.
Volendo fare le stesse cose per i sistemi multicomputer abbiamo la classica rete Internet dove abbiamo la CPU la memoria locale (e quindi questa è una workstation) ed abbiamo tante workstation.
|
|
In quest'altra figura abbiamo il trasputer che però non ha avuto molto successo ed era un componente che poteva essere connesso a maglia con altri componenti uguali in cui ognuno di questi ha una propria memoria locale(in realtà ognuno di questi era un multicalcolatore e non un multiprocessore) e questo è un caso limite tra sistemi distribuiti in senso stretto e sistemi paralleli, infatti si potrebbe vedere come sistema distribuito in senso stretto poiché ognuno CPU ha una propria memoria locale ma nei fatti questa risolve una unica applicazione(questa era destinata ai calcoli di compagnie petrolifere per studi geologici).
Ci occuperemo esclusivamente della tipologia di sistemi distribuiti in senso stretto in cui abbiamo un workstation lascamente connesse e sono connesse in rete locale (o geografica) e quindi quando parleremo di S.O. faremo riferimento a questo tipo sistema e alla interconnessione con i vari S.O.
Ieri, dicemmo che vi erano due tipi di architetture distribuite, che erano in sostanza le macchine multiprocessore con una memoria comune e le reti di calcolatori. Quest'ultimo è il tipo di sistemi distribuiti che ha noi più interessa. Quindi noi ci occuperemo di sistemi operativi per questo lo tipo di architettura. Dicemmo ieri, che la tendenza attuale è in realtà duplice: il mondo scientifico sta cercando di creare dal nuovo, sistemi operativi per queste macchine che devono realizzare delle funzionalità che dopo vedremo, mentre le aziende, invece, sfruttano i sistemi operativi esistenti e ci calano sopra un software di comunicazione che permette in realtà di creare un file system distribuito.
Questa duplice tendenza fa sì che si possa parlare di sistemi operativi lascamente commessi e sistemi operativi strettamente connessi.
Si utilizza il termine 'sistemi operativi lascamente connessi' quando esso nasce dai vari sistemi operativi delle singole macchine integrati dal software di rete.
Sistemi operativi lascamente connessi
Sono costituiti dai sistemi operativi delle singole macchine e da un sistema operativo di rete.
Possono supportare a seconda dei casi:
La condivisione di risorse: device fisici (ad esempio stampanti), file, basi di dati(questo è quello che succede quando io realizzo un files server) , gestori di comunicazione (ad esempio un programma che permetta ad una rete locale di collegarsi ad Internet che è condiviso da tutte le macchine della rete) , applicativi utente.
Login remoto (cioè la possibilità di far il login da una macchina diversa da quella in questione)
Questi sono i servizi base che ogni sistema operativo distribuito lascamente connesso certamente mette a disposizione.
I sistemi operativi distribuiti strettamente connessi, partono invece dal concetto base di fare apparire all'utente del sistema distribuito così come se fosse un sistema monolitico, cioè si cerca di rendere del tutto trasparente a chi si siede dietro una stazione di lavoro il fatto che quella stazione di lavoro sia in rete.
Sistemi operativi strettamente connessi
Sono i veri sistemi operativi e mirano alla trasparenza ossia a far apparire il sistema come un sistema virtuale centralizzato.
Si caratterizzano per:
Un unico meccanismo di comunicazione globale tra i processi (cioè valido per tutti i processi che girano sulle macchine a prescindere da quali sono le macchine; ciò attualmente non è ancora possibile nella realtà) .
Un unico sistema di protezione e sicurezza di accessi.
Un'unica tecnica di gestione dei processi (questa è un altra cosa che sicuramente i sistemi lascamente connessi non hanno) .
Stesso Kernel di sistema operativo sulle singole macchine (osserviamo la differenza fondamentale con i sistemi precedenti dove ogni macchina poteva avere un sistema operativo differente ad esempio windows, UNIX eccetera. Del resto questo è l'unico modo per avere l'unico meccanismo di comunicazione globale tra i processi e un unico modo di avere una unica tecnica di gestione dei processi, in quanto, ovviamente, il gestore dei processi su una macchina è il Kernel di quella macchina) .
(Vedi Tanembaum Figura 9.15: a) Kernel monolitico, b) microKernel)
Il modo di realizzare ciò è quello di avere un microKernel su ogni macchina. Un microKernel è un Kernel molto ridotto che fornisce solo i servizi base (ovviamente uguali per tutte le macchine) che sono nei fatti i meccanismi di gestione dei processi.
La ragione di ciò è dovuta al fatto che alcune di queste macchine devono essere specializzate, e il modo di specializzare una macchina è quello di metterci sopra del software che poi mi realizza le funzionalità specifiche che io voglio assegnare a quella macchina. Tale software deve essere visto come processi di sistema, che devono basarsi sul microKernel così come si basano i normali processi utente.
Nella figura, ad esempio vediamo il microKernel su una macchina e subito sopra l'utente, cioè il normale utente che ci lavora sopra; poi abbiamo il microKernel e sopra il file server; poi abbiamo il microKernel e sopra il server delle directory ( questa è un ulteriore specializzazione cioè un server che serve a gestire semplicemente l'accesso alle directory del file system distribuito, cioè su questa macchina non ci sono file di utente ma ci sono semplicemente i file directory con i quali poi si accede ai file di utente); poi abbiamo server dai processi sopra il microKernel, il che vorrebbe dire una macchina specializzata per decidere su quale macchina del sistema vanno allocati i processi di utente, potendosi spostare, questi processi, da una macchina all'altra macchina a seconda del carico.
Alcune cose che abbiamo detto sono abbastanza futuribili; ad esempio avere da qualche parte un server di processi che sia in grado di gestire una applicazione commerciale non esiste. Esistono solo semplici applicazioni di laboratorio (a livello di ricerca universitaria) che stanno studiando dei meccanismi con i quali distribuire i processi su una rete di macchine, processi cooperanti ovviamente, ottimizzando la allocazione del carico di queste macchine.
Altre cose invece sono già reali, come ad esempio il file server cioè un data base server. Tuttavia, quelli che ci sono attualmente, vengono realizzati guardando sotto un Kernel che non è un Kernel omogeneo ma è un Kernel di un sistema operativo centralizzato: se io voglio attualmente realizzare un file server lo faccio su una macchina UNIX e quindi vedo il Kernel di UNIX oppure su una macchina windows NT e quindi avrò il suo Kernel.
Ci siamo sicuramente resi sconto che un sistema operativo strettamente connesso non è di facile realizzazione. Vediamo adesso quali sono i principali problemi.
Il primo è quello della trasparenza; questa è la cosa più difficile da fare se si vuole realizzarla pienamente. La difficoltà sta nel fatto che vi sono diverse cose da garantire se vogliamo garantire la trasparenza perché noi dobbiamo garantire diversi tipi di trasparenza.
Trasparenza :
Alla posizione: gli utenti ignorano le posizioni delle risorse (se esso vede un unica macchina virtuale, non deve ad esempio vedere che il file sul quale sta lavorando si trova sulla macchina Pinco o sulla macchina Pallino, ma esso si trova sulla sua macchina virtuale).
Alla migrazione: le risorse, migrano sempre senza che gli utenti ne abbiano percezione (rifacendoci all'esempio del punto precedente, l'utente deve anche ignorare se il file sul quale sta lavorando, per qualche motivo, sia fatto spostare dalla macchina Pinco alla macchina Pallino, il che significa poi, che la sua applicazione (la quale ricordiamo è stata scritta una sola volta ed è sempre la stessa) deve continuare a funzionare a prescindere dalla locazione del file, il che implica a sua volta che nella applicazione non ci deve essere nessun riferimento alla macchina, in modo tale che questo file possa migrare da un server ad un altro server senza che lui se ne accorga).
Alla replicazione: esistono più copie di una risorsa gestite dal sistema all'insaputa dell'utente (ad esempio ho più stampanti, una stampante Pinco si guasta e il sistema redireziona automaticamente l'output verso la stampante Pallino senza che l'utente se ne accorga. Oppure, ad esempio, se io tengo un file duplicato e una copia non è più utilizzabile in quanto ha avuto un crash e automaticamente il sistema mi fa lavorare sulla seconda copia senza che io me ne accorga mantenendomi inoltre allineata la coppia a e la copia b)
Alla concorrenza: il sistema gestisce l'accesso sequenziale alle risorse condivise (cioè, significa che io gestisco la mutua esclusione senza che l'utente se ne accorga, cioè senza che lui me lo abbiamo detto)
Al parallelismo: il sistema riconosce le attività da svolgere in parallelo.
Ancora una volta, alcune delle cose sopra elencate sono futuribili mentre quelle che attualmente sono state già in parte risolte con del software apposito che viene già adesso utilizzato ad integrazione di un sistema distribuito sono la trasparenza alla migrazione (in parte),alla posizione e duplicazione dei file.
Un altro requisito che i sistemi distribuiti devono avere è la flessibilità.
Il discorso della flessibilità è risolto dal fatto che i sistemi operativi di questo genere devono essere costituiti da un microKernel uguale per tutte le macchine. Questo mi da' la flessibilità in quanto la disponibilità di un microKernel uguale su tutte macchine mi offre tutti i servizi base identici, e nello stesso tempo, permette di avere servizi più sofisticati con del software apposito che su certe macchine ci sta e su delle altre no.
Flessibilità:
Requisito che si traduce nella necessità di realizzare il sistema operativo delle singole macchine con un microkernel che garantisca servizi di:
Comunicazione dei processi
Gestione base della memoria (di basso livello, non della memoria virtuale)
Gestione base della schedulazione dei processi
Ingresso/uscita a basso livello
spostando quindi all'esterno gli altri servizi in modo da implementarli a seconda delle esigenze (esempio file server UNIX e DOS sulla stessa macchina in quanto essi vengono realizzati da qualche software che è calato sul microkernel della macchina)
Gli ultimi requisiti che questo tipo di sistemi dovrebbero avere, sono la affidabilità, le prestazioni e la scalabilità.
Affidabilità:
Requisito che si presenta sotto gli aspetti di:
Disponibilità del sistema in presenza di guasti di alcune sue componenti .
Sicurezza nei confronti di usi di risorse non autorizzati
Tolleranza ai guasti, cioè la capacità di recuperare i malfunzionamenti senza che l'utente intervenga (nel caso di malfunzionamento avere comunque parte del sistema che funziona ancora e che mi recuperi i guasti)
Prestazioni
Requisito che dipende in positivo dal numero di CPU disponibili per le computazioni e in negativo dall'overhead delle comunicazioni.
Richiede quindi un'accorta definizione della grana delle computazioni perché la tolleranza ai guasti condiziona le prestazioni di un sistema distribuito
Scalabilità
Requisito che misura la capacità del sistema operativo e del software applicativo di essere calato su un sistema distribuito indipendentemente dal numero di CPU
Questi ultimi, sono comunque requisiti più lontani dal essere attualmente garantiti.
La tendenza attuale è di realizzare sistemi operativi di tipo aperto basati su UNIX (anche se ultimamente si sta diffondendo anche l'utilizzo della macchina windows NT; potremmo avere anche una rete nella quale invece di utilizzare windows NT utilizziamo windows 95 ma in tal caso avremmo un sistema distribuito neanche lascamente connesso ma avremmo solo dei PC che sono collegati in rete attraverso un qualche software).
Esistono due organizzazioni che hanno tale obiettivo:
Open Software Fondation (DEC,HP,IBM,Microsoft e altri) essa è un associazione fatta da costruttori i quali hanno scelto una certa versione di UNIX. La scelta è caduta su UNIX della Digital (hanno a che fare con il Distribuited Computer Environment DCE).
(inoltre, c'era un'altra organizzazione di cui non sono riuscito a prendere nota ma che non ha molta importanza N.d.A.).
Quindi, ripetendo ancora una volta, quello che si sta cercando di fare è quello di mettere su queste macchine UNIX del software che permetta di realizzare un sistema lascamente connesso. Cioè si cerca di implementare quella che è stata definita l'architettura DCE).
Architettura del DCE
Questo tipo di architettura prevede che su macchina UNIX siano disponibili i seguenti componenti:
File sistema distribuito (DFS)
Gestione di un direttorio di oggetti (servizi di rete, mailbox, computers, eccetera)
Chiamate a procedura remota (il che significa garantire l'implementazione di applicazioni client server)
Gestione dei thread (quando abbiamo parlato dei processi abbiamo detto che ci potevano essere due tipi di processi: i processi classici e i processi leggeri. Questi ultimi sono i thread. La differenza tra un processo classico e un processo leggero è che mentre i processi classici (diciamo alla UNIX) hanno ciascuno una propria area di memoria, quindi non c'è condivisione di area di memoria, nel caso dei processi leggeri io ho nei fatti dei processi che condividono del tutto l'area di memoria e quindi mi devo preoccupare dei conflitti e delle mutue esclusioni sulle strutture dati. Quindi il sistema operativo deve mettere a disposizione dei meccanismi tali che mi consentono di risolve facilmente la mutua esclusione sulla memoria condivisa (dei meccanismi tipo semafori).
Gestione dei clock e di macchine (cioè avere la capacità di gestire l'allineamento dei vari clock di macchina in modo tale da definire con una certa approssimazione un tempo globale di riferimento)
Quindi noi andiamo a definire un architettura complessiva in cui andiamo a mettere i vari componenti software che ci servono a garantire l'insieme di servizi sopra visto.
Teniamo presente che non è detto che questi componenti software siano prodotti dalla casa costruttrice che ha creato il sistema operativo UNIX che gira su quella macchina, perché io posso tranquillamente avere un sistema operativo UNIX comprato dalla DIGITAL, questo supporta la architettura DCE e io ci vado a mettere sopra un software della casa Pinco o della cassa Pallino (la quale aderisce a questo schema architetturale) che fornisce uno dei servizi sopra elencati.
Con questo abbiamo finito la parte di introduzione ai sistemi distribuiti; adesso dovremmo entrare un po' più in dettaglio in alcuni degli argomenti sopra citati. Prima di fare ciò dobbiamo fare ancora una piccola introduzione ai concetti generali che riguardano le reti di calcolatori.
Classificazione delle reti: tipologie LAN, WAN, MAN
Sì diversificano per
Distanza fra i nodi
Rete di comunicazione
Velocità di trasmissione
LAN: Local Area Network
Utenti dislocati a moderata distanza (in un edificio o un campus)
Rete di comunicazione costituito da apposito cablaggio che include elementi attivi (hub, repeater, terminal server, bridge) (nell'hardware della rete abbiamo degli elementi attivi e degli elementi passivi cioè esiste un supporto fisico che serve a mantenere i segnali elettrici che viaggio sulla rete e ci sono poi degli elementi attivi che permettono di gestire la comunicazione, cioè i bit, che viaggiano sulla rete. Nei fatti per elemento passivo intendiamo il filo elettrico che può essere il cavo coassiale oppure può essere il cavo giallo che si usava fino a sette o otto anni fa, un altro supporto di rete può essere il doppino telefonico).
Velocità di trasmissione da 1 a 100 Mb/sec. (anche se adesso stiamo a livelli più alti)
Sempre riguardo all LAN.
Metodi di trasmissione e controllo degli accessi in una LAN:
Doppino telefonico cavo coassiale in banda base e a larga banda, fibra ottica (Il doppino telefonico viene utilizzato specialmente quando cresce il numero di macchine che sono in rete. Teniamo presente che con il doppino telefonico, la connessione fisica è a stella, cioè a livello topologico la rete appare a stella, mentre con il cavo coassiale la rete e a bus).
CSMA/CD (reti Eternet) e CSMA/CA (reti token ring e token bus)
velocità di trasmissione da 50 a 600 Mb/sec
Integrazione completa in sistemi di cablaggio strutturati Eternet Token Ring ecc. sono in pratica dei protocolli di rete.
Man: Metropolitan Area Network
utenti dislocati in un'area metropolitana
rete di comunicazione costituita da linee telefoniche e da infrastrutture tipiche di un'area metropolitana
velocità di trasmissione da 50 a 600 Mbps, grazie ad ATM e DQDB
Wan: Wide Area Network
Utenti a grande distanza (ad esempio migliaia di chilometri)
Rete di comunicazione costituita da linee telefoniche, canali a microonde, fibra ottica, collegamenti via satellite
Velocità di trasmissione da 1200 b/sec a 1 Mb/sec
Attualmente siamo su livelli di 32 Mb/sec. a 622 Mbps con la tecnologia ATM
__________ ______ ____ __________ ______ ____ _________
La comunicazione nei sistemi distribuiti
E' l'elemento chiave di sistemi distribuiti lascamente connessi e a memoria locale in cui lo scambio di dati tra processi avviene unicamente mediante uno scambio di messaggi
Deve essere strutturata a livelli astratti per supportare tutti i possibili aspetti della comunicazione coinvolti nel colloquio tra entità sia di alto che di basso livello di astrazione (esempio: la comunicazione tra due programmi applicativi, è un tipo di comunicazione che si pone ad un livello molto alto e che deve essere permessa. Per permettere ciò noi dobbiamo fare comunicare due processi di cui uno crea un messaggio e un altro lo riceve; i processi mittente e destinatario si trovano ad un livello di astrazione certamente più basso di quello dei programmi applicativi a cui i processi appartengono. Dobbiamo quindi avere un software di gestione dello scambio di un messaggio tra due macchine. Del resto, per scambiare un messaggio c'è bisogno di scambiare dei byte, anzi dobbiamo scambiare i singoli bit del messaggio e quindi dobbiamo far colloquiare i due attori che permettono di trasmettere un bit sulla linea (che saranno sicuramente degli attori hardware. Prima i due attori che dovevano colloquiare erano rispettivamente i due programmi applicativi e i due processi ). C'è bisogno quindi anche di una logica per l'invio di un singolo bit su una linea seriale). Riassumendo quindi, la comunicazione coinvolge due attori che si pongono ad un livello di astrazione diversa e ciò significa dire che la comunicazione deve prevedere necessariamente dei meccanismi che sono strutturati a livelli così come sono strutturati a diversi livelli di astrazione gli attori che utilizzano questi meccanismi.
Richiede la definizione di protocolli ossia di regole che devono essere seguite dalle entità di pari livello per poter colloquiare tra loro
Quindi, riassumendo i concetti riportati in questo lucido, abbiamo che:
noi dobbiamo far colloquiare due attori che si pongono allo stesso livello di astrazione; per far questo debbo definire un protocollo ossia delle regole, ed è chiaro che, probabilmente, poiché gli attori ad un certo livello di astrazione non possono colloquiare tra di loro direttamente, il colloquio tra le due entità di un certo livello avviene, nei fatti, utilizzando colloqui tra due entità del livello immediatamente inferiore le quali a loro volta, ovviamente, utilizzeranno un protocollo di livello inferiore, cioè delle regole di livello inferiore, e così via a scendere fino a quando non arriviamo alle due entità che sono in grado di scambiarsi un bit, che sono lei uniche entità che sono in grado di colloquiare direttamente tra loro.
Quindi, nei fatti, abbiamo il concetto non solo di protocollo, ma anche il concetto di livello di protocollo.
Un esempio:
Abbiamo due manager che debbono comunicare fra di loro, per fare un certo affare. Questi due attori colloquiano nell'ambito di un contesto ben definito in cui ognuno conosce esattamente la semantica del problema che deve trattare cioè conoscere il livello cognitivo. Questi due manager scambiano queste informazioni probabilmente non in modo diretto (nei fatti anche se parlassero uno di fronte all'alto userebbero dei meccanismi di più basso livello come il suono che si propaga nell'aria, e viene ascoltato ) ma parleranno tramite le loro segretarie che rappresentano gli attori di livello più basso. Quindi ogni manager parlerà con la propria segretaria per poter comunicare con l'altro manager. La segretaria non conosce il significato delle parole che deve comunicare all'altro manager ma batterà semplicemente a macchina il messaggio da comunicare. Peraltro questo messaggio non sarà dato a mano all'altra segretaria ma, per esempio, sarà inviato via fax cioè verrà messo su un fax che parlerà con l'altro fax.
Quindi, in sostanza, abbiamo un discorso di attori che devono comunicare tra di loro ad un certo livello di astrazione caratterizzato da delle proprie regole e da una propria semantica del messaggio. Del resto questi attori non sono in grado di comunicare tra di loro e quindi devono usare attori di livello più basso che hanno una comunicazione a loro volta caratterizzata da una propria semantica e da un proprio protocollo. Questo discorso si ripete fintanto non si giunge ad un livello in cui i due attori sono in grado di comunicare tra loro, anche questo livello è caratterizzato dalla propria semantica e dalle proprie regole di comunicazione.
Ne segue che la comunicazione non coinvolge un unico protocollo, ma coinvolge n protocolli che sono tutti i protocolli degli attori di livello più basso che sono coinvolti nel colloquio tra i due attori diciamo base.
Il lucido seguente non fa altro che ribadire i concetti appena esplicitati.
Un altro esempio:
La comunicazione tra le persone coinvolge:
un livello cognitivo che include concetti e conoscenze note alle persone che comunicano tra loro(ad es. il concetto i libro se si sta parlando del suo contenuto)
un livello linguaggio utilizzato per tradurre la semantica dei messaggi scambiati in parole (ad esempio la lingua italiana)
un livello fisico che fornisce il mezzo utilizzato per lo scambio di messaggi (ad esempio le onde sonore o un foglio di carta)
Concetti chiave
Ciascun livello include servizi di comunicazione
I servizi offerti da livelli distribuiti sono tra loro indipendenti
La comunicazione avviene sempre tra entità di pari livello allocate in distinti nodi della rete
La comunicazione tra due entità di livello di astrazione I richiede necessariamente il supporto di livelli inferiori in quanto un servizio di livello I viene implementato mediante servizi di livello I-1
Le regole e i formati che specificano lo scambio di dati a due livelli adiacenti costituiscono una interfaccia tra i livelli
Una cosa fondamentale che bisogna sottolineare, è che ogni entità offre dei servizi alle entità di livello più alto utilizzando servizi offerti dai livelli più bassi, e, ciascuna entità, è indipendente sia da quelle di livello più alto che da quelle di livello più basso. Questo significa dire che in una suite di protocolli io posso sfilare un livello, sostituirlo con un altro, e far rimanere inalterati sia tutto lo stack dei livelli inferiori che quello dei livelli superiori. Questo concetto, in termini pratici, è importantissimo ed è quello che per esempio mi permette di realizzare lo scambio di un file tra due macchine mediante un protocollo T C P A P il quale viene implementato su una rete locale che può essere sia Eternet che token ring dove il protocollo Eternet e il protocollo token ring sono due protocolli di livello più basso che sono tra di loro in alternativa. Quindi io posso avere, ad esempio, una rete costituita da un doppino telefonico ( quindi ci sarà un protocollo per scambiare un bit sul doppino), su cui è implementato il protocollo Eternet per scambiare i frame (pacchetti, insieme dei byte che bit dopo bit vengono mandati. Esiste una differenza fondamentale tra il termine pacchetto e il termine frame: pacchetto e è un fatto logico, il frame è un fatto fisico, quindi essi si pongono a due livelli di astrazione differenti) e sul frame implemento il protocollo IP (Internet Protocol) che è un protocollo che mi permette di scambiare i frame tra due macchine che non sono strettamente connesse ma due macchine che sono connesse attraverso una terza macchina. Quindi I P può tenere sotto un livello che è sia Eternet sia token ring che sono in alternativa e quindi io posso sostituire un protocollo di un livello con un altro protocollo dello stesso livello e questo mi deve consentire di far rimanere inalterati sia i protocolli utilizzati ai livelli più alti che quelli utilizzati dai livelli più bassi. Se immaginiamo che questi livelli sono molti capiamo le combinazioni che possono venire a crearsi e ciò è importante per chi studia i sistemi di comunicazione perché deve capire se due livelli sono tra di loro compatibili perché in realtà appartengono a livelli distinti oppure se sono tra di loro in antagonismo perché appartengono allo stesso livello e quindi non possono coesistere nell'ambito di uno stesso sistema.
E' implicito in quello che abbiamo appena detto che se io sostituiscono un livello con un altro devo rispettare l'interfaccia stabilita tra quei due livelli.
Vantaggi della struttura a livelli
Indipendenza tra i livelli. Un livello deve conoscere i servizi offerti dal livello immediatamente inferiore ma non come sono implementati
Flessibilità. Una modifica ai servizi offerti da un livello non ha conseguenze sui livelli inferiori e una modifica alle modalità di erogazione di un servizio offerto da un livello non ha conseguenze sugli altri livelli
La decomposizione facilita il progetto modulare dei livelli e la loro manutenzione
Con la struttura in livelli e l'incapsulamento delle funzioni che implementano i servizi è il presupposto della attività di standardizzazione della struttura di un sistema di comunicazione (Ad esempio il grande successo avuto dal modello OSI è dovuto al fatto che esso ha fissato una struttura a livelli e standardizzato ciascun livello di protocollo. In questo modo è stato possibile recepire una buona parte dei protocolli esistenti e ciò ha consentito di far comunicare tra di loro macchine tra loro diverse).
Figura 10.1 livelli, interfaccia e protocolli nel modello osi
Il modello Open System Interconnection (OSI)
È stato definito dal ISO (International Standard Organizzation)
E' strutturato in 7 livelli ed include gli aspetti sia hardware che software di una architettura di rete (pensa ad attori che devono colloquiare su ciascuno di questi livelli e quindi definisce le caratteristiche dei servizi che debbono offrire i protocolli a ciascuno di questi 7 livelli)
Include sia i protocolli orientati alla connessione che deve essere stabilita tra mittente e destinatario prima di scambiarsi i dati, che protocolli privi di connessione
Una intestazione (header) viene sempre aggiunta ad un messaggio prima di essere scambiato tra livello I e il livello I-1 della macchina mittente. Un messaggio che viaggia su di una rete è quindi preceduto da molte intestazioni (il numero di intestazioni quindi cresce quando scendiamo nei livelli della stessa macchina mentre diminuisce quando saliamo tra questi livelli. Ogni livello aggiunge un'intestazione che il livello omologo della macchina destinataria considera come informazione, tale informazione viene soppressa se si deve passare dal livello I-1 al livello I mentre viene sostituita se si deve riscendere per passare alla macchina successiva. Nell'intestazione vi sono non solo le informazioni che servono a gestire il messaggio ma anche quelle che mi consentono di capire se debbono continuare a salire o scendere e tutte le informazioni che mi permettono di effettuare i controlli ( debbo controllare che l'informazione che mi è arrivata è corretto). Tali controlli sono previsti a tutti i livelli; quando uno di questi controlli fallisce, la trasmissione si interrompe e c'è un messaggio di ritorno lungo la rete di comunicazione per poter permettere all'attore principale di poter ritrasmettere il messaggio che ha subito il guasto cioè ha perso il contenuto informativo. Questo recover della comunicazione è del tutto trasparente allo attore principale che ha iniziato il protocollo )
figura 10.2: un tipico messaggio..
I vari livelli che sono descritti nella figura 10 verranno da noi ora analizzati uno ad uno mettendo in luce i protocolli che appartengono a questi livelli in modo tale che li possiamo riconoscere avendoli in qualche forma sentiti (tuttavia non saranno approfonditi perché non riguardano esplicitamente il nostro corso).
Livello fisico
Si occupa della trasmissione dei singoli bit. A tale livello viene definita:
La modalità di rappresentazione fisica dei bit
La velocità di trasmissione
L'unidirezionalità e la bidirezionalità
Il mezzo di comunicazione
La dimensione e la forma dei connettori
Esistono molti protocolli standard per tale livello fisico; il più noto è il protocollo RS232C per la linea di comunicazione seriale
__________ ______ ____ __________ ______ ____ _________
Il livello fisico tipicamente riceve un byte dal livello superiore (immaginiamo la tipica interfaccia seriale) e spara ad uno ad uno i vari bit sulla rete. Questo viene certamente implementato dall'hardware della interfaccia seriale cioè dalla scheda Eternet. Quindi in questo livello viene definito un protocollo che fissa i punti elencati nel lucido precedente.
La comunicazione nei sistemi distribuiti
Nel modello Open System Interconection abbiamo degli algoritmi che colloquiano a più livelli:
Livello 1 : il livello fisico
Si occupa della trasmissione tramite cavo e con un protocollo specifico. Ma questo non ci interessa molto;
Livello 2 : livello dei dati
Questo è il protocollo che permette di trasmettere dei frame tra due macchine.
La caratteristica importante è che le macchine che si scambiano il frame (che è un insieme di byte), sono macchine in cui esiste una connessione fisica.
Oss. Un frame è un messaggio a livello di link ed indica un qualcosa di strutturato che non dipende dalla particolare semantica dei byte.
Ricordiamo che il messaggio che va sulla rete si presenta come in FIG:
|
esiste il contenuto informativo dove è stato aggiunto delle "testate" (sono 6) e la coda è relativa del livello dati.
Quindi abbiamo marcato , aggiungendo la testa e la coda, l'inizio e la fine del frame ed abbiamo aggiunto nella coda delle informazioni di controllo. In particolare abbiamo calcolato ed aggiunto il byte di checksum ed introducendo in questo il concetto di pacchetto numerato. Il ricevente può scoprire degli errori di trasmissione o tramite il checksum (il quale avrà un valore errato) o tramite il numero di frame (il quale o è per salto oppure è per ripetizione).
Per vedere come funziona vediamo la fig.
|
|||||||||||||||
Abbiamo il trasmittente A e il ricevente B, il trasmittente A manda il Dato0 a B il quale si accorge dell'errore, ma nel frattempo A sta mandando il Dato1, ma con il segnale di controllo B avverte A di ritrasmettere il Dato0.
Riepilogando per il livello 2 :
Si occupa della trasmissione dei frame su di un link e della individuazione e correzione degli errori di trasmissione. Un frame è un messaggio a livello di link.
Inoltre si fa carico di:
1)Marcare l'inizio e la fine di un frame;
2)Calcola ed aggiunge il byte di checksum;
3)Verifica il checksum;
4)Associa ad un frame un numero;
5)Richiede e ritrasmette i frame errati (per checksum o sequenza);
Citiamo dei protocolli di livello 2:
-Avanced Data Communication Control Procedure (ADCCP) dell'ANSI;
-High level Data Link Control (HDLC) dell'ISO;
-**Syncronus Data Link Control (SDLC) della System Network Architeture (SNA) dell'IBM;
-**I Protocolli IEEE 8022 (Carrier Sense Multiple Access with Collision Detection - CSMA/CD TOKEN BUS e TOKEN RING);
N.B. con il simbolo ** abbiamo indicato i protocollo più usati.
Parliamo in particolare del CSMA/CD (e CSMA/CA) perché è quella che utilizza l'Ethernet.
Si chiama Collision Detection poiché la struttura fisica di trasmissioni dati ipotizzata per l'Ethernet il bus che è strutturato con un protocollo dato da :
10 base T twisted poiv
10 base 2 their
10 base 5 thick
|
|
|
|
Questi tre supporti fisici permettono di creare il bus.
Ora grazie al CSMA/CD permette di far vedere l'Ethernet come se fosse collegato ancora ad un bus
anche quando abbiamo un grosso numero di accessi ad un nodo(vedi FIG) e fa in modo che quando ci sono delle collisioni (cioè due attori chiedono il server) ritarda i frame segmentando la rete (vedi FIG) ed il Bridge deve riconoscere l'indirizzo della macchina per dargli l'autorizzazione a passare o tenerlo sospeso in un segmento.
Vediamo il CSMA/CA
Supponiamo di avere delle macchine che sono connesse ad anello, quindi ogni macchina ha una macchina antecedente ed un macchina seguente ed ogni macchina colloquia con quella seguente.
Quindi per poter colloquiare due macchine distanti devono essere coinvolte tutte le macchine che stanno in mezzo e deve avere una autorizzazione dalla macchina che la seguente (token, cioè puoi farlo).
Ora se la macchina ha qualcosa da trasmettere passa il messaggio alla successiva la quale riconosce se il messaggio è rivolto a lei oppure ad un'altra macchina. Se il messaggio era destinato ad un'altra macchina aspetta a sua volta il token della macchina successiva e così via fino a quando il messaggio è arrivato a destinazione.
Livello 3 : livello rete
Si occupa della trasmissione dei frame tra macchine che non sono strettamente connesse, e quindi ha il compito di trovare il percorso che il pacchetto deve fare per la destinazione. Quindi questo livello deve riconoscere verso chi si deve instradare il pacchetto. Allora in altre parole :
1)Si occupa della trasmissione dei pacchetti ossia dei messaggi a livello nodi rete;
2)Si fa carico di controllare la congestione della rete e instradare (routing) i messaggi;
3)Al livello appartengono sia protocolli orientati alla connessione quali X.25 del CCITT che protocolli senza connessione quali IP (Internet Protocol che usa una tabella ) del DoD;
Livello 4 : il livello trasporto
Ha il seguente compito:
1)Si occupa della trasmissione dei messaggi che provengono dal livello superiore suddividendoli in pacchetti da affidare al livello inferiore;
2)Al livello appartengono sia protocolli orientati alla connessione, cioè quelli che garantiscono una connessione diretta virtuale senza controllo dell'errore, quali TCP (Trasmission Control Protocol) che protocolli senza connessione UDP (Universal Datagram Protocol) entrambi del DoD;
3)Entrambi i tipi di protocollo possono essere implementati con protocolli del livello inferiore sia orientati alla connessione che privi di connessione (il tipo di connessione dipende dal tipo di Bus);
4)Le combinazioni più note sono TCP/IP e UDP/IP;
Questi sono i livelli più importanti quelli che seguono li vedremo più velocemente.
Livello 5 : il livello di sessione
In questo livello un attore colloquia con un altro attore per una intera sessione di lavoro e il messaggio per una intera sessione di lavoro vengono passati al livello 4 il quale che li suddivide in pacchetti etc.
Livello 6 : il formato dei messaggi
Nella strutturazione del messaggio si deve conoscere il formato;
Livello 7 : livello delle applicazioni
In questo livello i due attori sono due applicazioni che colloquiano;
Il modello a scambio di messaggio
Vediamo quali sono le modalità di interazione (o comunicazione)di processi che sono allocate su macchine distinte, le quali modalità abbiamo già cominciato a discutere quando abbiamo parlato della cooperazione tra processi.
Abbiamo visto che due processi possono cooperare(e non c'è competizione) nel modello a scambio di messaggio.
Ricordiamo che nel modello a scambio di messaggio, ciascun processo evolve in un proprio ambiente e non può essere modificato da altri processi e questo implica che una qualsiasi iterazione tra processi avviene mediante scambio diretto di messaggi tramite Kernel o in fase di compilazione.
Per i vari processi esiste un gestore di risorse e da questo nasce il concetto di server il quale è un gestore per contro di altri processi di proprie risorse private.
Quindi i processi dovranno :
1)Ricevere messaggi di richiesta ;
2)Dovranno operare sulle risorse che gestiscono ;
L'implementazione di questi processi per la gestione delle risorse funziona bene nel modello client server in cui il file fa la richiesta e va in attesa del servizio
Oss. Due operazioni si dicono sincronizzati quando in ogni momento l'uno sa lo stato dell'altro.
Lo scambio di messaggio avviene tramite :
-send (dest,mptr)
-receive(addr,mptr)
in cui per la send i parametri sono il destinatario e il messaggio e nel caso della receive sono un puntatore address il quale potrebbe qualificare il messaggio ricevente o una nostra mailbox tra le varie mailbox che possediamo.
In realtà address è l'indirizzo di ascolto della macchina destinataria.
Primitive bloccanti e non bloccanti
Ricordiamo che send bloccante(sincrona, cioè se il mittente e il destinatario non appartengono alla stessa macchina il blocco permane fin quanto il messaggio viene copiato a cura del Kernel dal buffer del mittente al destinatario, se il mittente e destinatario appartengono alla stessa macchina il blocco non si ha quando il messaggio è ricevuto ma quando è trasmesso ) e non bloccante(asincrona), quindi:
send bloccante
Il mittente è bloccato finche il messaggio non viene completamente trasmesso e si libera quando il buffer ha depositato il messaggio;
|
send non bloccante
Il mittente è bloccato soltanto per il tempo necessario a liberare il buffer in cui ha depositato il messaggio copiandolo in un buffer interno al Kernel
Il mittente non viene affatto bloccato ed il suo buffer liberato ma il Kernel segnalerà questa evenienza mediante una interruzione.
|
receive bloccante
Il destinatario che esegue la receive è bloccato se il messaggio non è disponibile e lo sarà finche questo non perviene;
receive non bloccante
Il destinatario non viene mai bloccato. Si possono avere i seguenti casi:
-la receive riceve il messaggio e questo è presente;
-la receive non riceve il messaggio perché questo non è presente (passaggio al Kernel);
Oss. Le primitive non bloccanti sono anche dette sono anche dette sincrone mentre quelle bloccanti sono dette anche sincrone
Primitive bufferizzate e non bufferizzate
La send non bloccante presuppone una bufferizzazione di messaggio, cioè non basta avere il buffer del mittente ma dobbiamo avere anche un buffer nel Kernel, poiché dobbiamo liberare il buffer del mittente per una prossima send, mentre le send bloccanti non sono bufferizzate.
nello stesso modo possiamo avere:
receive non bufferizzata
Una receive comporta la perdita di un messaggio se il destinatario segnala la volontà di ascoltare un messaggio (cioè esegue la receive) dopo che il mittente si blocca
receive bufferizzata
Il processo può richiedere al Kernel di creare un mailbox associata ad un indirizzo
Oss una send non bloccante non è affidabile
Lezione tratta da Tanenbound.
Il modello client server:
per modello client-server si intende: vi sono due processi i quali cooperano, nel contesto della stessa applicazione, di questi due processi in realtà nel contesto del primo viene eseguito un programma chiamante mentre nel secondo, il server, viene eseguito (diciamo) il sottoprogramma che l'applicazione richiede.
abbiamo utilizzato questo esempio brutale perché nel contesto di un unico processo, nel momento in cui ho una applicazione sequenziale, in tale contesto viene eseguito sia programma chiamante che il chiamato; e è quindi ovvio che in esecuzione può esserci sono uno dei due. nel modello client server nel momento in cui faccio l'ipotesi che chiamante e chiamato vengono eseguiti nel contesto di due processi differenti allora il chiamante e chiamato potrebbero evolvere in parallelo nel qualcaso non si tratterebbe di una computazione client server perché nella computazione client server si fa l'ipotesi che il processo chiamante si sospendere per il tempo necessario acciocché la routine, che verrà eseguita nel contesto di un altro processo, venga completamente eseguita e finquando questa routine (ossia il processo nel cui contesto la routine è eseguita) non restituisce al contesto in cui viene eseguito il chiamante il risultato dell'elaborazione.
ecco quindi il concetto di cliente-servitore ciò significa dire nei fatti che il processo nel cui contesto viene eseguito il chiamante funge da cliente per il processo nel cui contesto viene eseguito il chiamato, nel senso che richiede un servizio a quest'ultimo.
Cerchiamo ora di capire perché si utilizza questo modello: ovviamente il modello Client-Server non è utilizzato per esplodere il parallelismo intrinseco dell'applicazione in quanto tale (il client è bloccato quando lavora il server) ma serve per mettere a comune il processo servitore a più processi clienti; e quindi nei fatti il servitore è un gestore di risorse che permette la condivisione di risorse proprietarie (del servitore) tra più processi clienti.
Introduzione alle architetture client server:
Se pensiamo alle architetture comunemente realizzate negli ultimi anni tipicamente non siano più in un ambiente centralizzato ma andiamo verso grosse macchine dove anziché avere terminali stupidi collegati ad un host abbiamo terminali stupidi collegati ad una macchina che gestisce terminali e essa è collegata all'host, questo tipo di macchina ha dato vita ad un'architettura denominata master/slave in cui nei fatti l'applicazione girava sull'host e i terminali gestivano l'input/output. Questo modello è stato poco usato, viene qui citato in quanto è un modello dall'architettura intermedia tra la macchina centralizzata e il modello client-server.
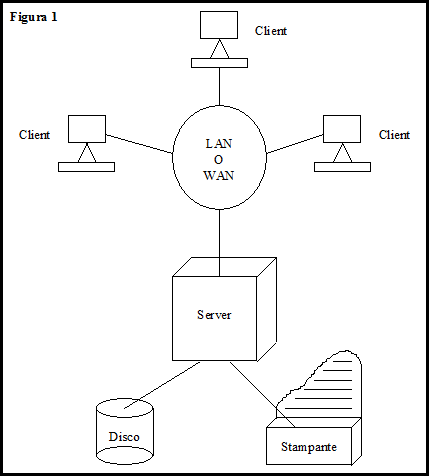
Nel modello client server si può anche avere un client che gestisce sono l'input/output ma l'avvio dell'applicazione non avviene sull'host (server) ma sul client stesso; si ha quindi un capovolgimento di logica. Un'architettura di certo più sofisticata è l'architettura pear to pear (pari a pari) dove ho più processi che cooperano tra di loro ma non esiste un legame di tipo master/slave (non c'è alcuna gerarchia) ad esempio il processo A può richiedere l'attivazione del processo B, ricevuti i dati li può spedire a un processo C richiedendo la sua attivazione e così via. Questa è l'architettura che viene usata nelle macchine parallele.
Quindi posso dire che quando parlo di un'applicazione client-server mi riferisco ad un'architettura del tipo in figura 1, dove ho una rete locale (o geografica), tante macchine intelligenti (client) su cui gira l'applicazione e infine ho il server su cui gira la restante parte dell'applicazione, in particolare si occupa di gestire le risorse condivise dai client.
La sofisticazione sta' nella modalità con cui partiziono l'applicazione, vedi figura 2, anziché avere un sistema monolitico distribuisco l'applicazione tra la macchina client e la macchina server. vediamo ora quali sono le possibilità di distribuzione intendendo con ciò che posso suddividere l'applicazione in diverse parti, di cui una si occuperà delle modalità di input/output, 1'altra parte invece si occuperà della fase elaborativa (algoritmica), avrò inoltre la gestione dei dati (Data Base), quindi occorrerà un DBMS che è parte integrante della mia applicazione nonostante sia una piattaforma sulla quale si poggia l'applicazione.
Il livello di sofisticazione dipendere da dove vado a tagliare questo discorso, cioè come vado a distribuire i pezzi dell'applicazione una parte sul client e una parte sul server; la logica più banale è quella di dire: la logica di presentazione sta sul client e tutto il resto sul server. Ancora più banale è quella di utilizzare il client come emulatore di terminali e tutto quanto è poi gestito dal server, ma questo non è client-server in quanto sottoutilizzo le macchine client e demando tutto alla macchina server.
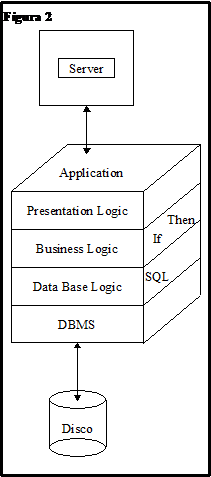
L'altra suddivisione classica è quella di tagliare all'opposto ovvero sulla macchina server ho il data base e il DBMS (Data base management server), in tal caso si usa dire data base server, mentre sulla macchina client ho tutto il resto dell'applicazione; quando faccio un accesso al Data base questo viene intercettato sulla macchina client e quindi si passa al server che fornisce il servizio. Questo tipo di suddivisione già fornisce un'applicazione client-server di un certo livello di sofisticazione.
Altro esempio ancora più sofisticato è quello di avere sul client la presentation logic e una parte del business logic dove la parte algoritmica viene distribuita su 2 o 3 macchine che lavorano in parallelo, (sto' facendo riferimento in questo caso ad un modello pari a pari).
Siamo ora giunti al punto in cui nei fatti dobbiamo risolvere (indipendentemente dalla distribuzione dell'applicazione) questo problema: devo porre su di una macchina una procedura chiamante sull'altra macchina dello allocare una procedura chiamata e devo fare in modo di costruire un'enviroment intorno al chiamante e al chiamato in modo tale che invece di fare una normale call a procedura, devo far sì che scateni un insieme di attività tali che la call viene fatta ma non alla reale procedura bensì ad una procedura fittizia (in modo tale che il chiamante non si accorga di nulla) che provvede poi ad implementare tutto il meccanismo di scambio di messaggi che permetterà di attivare un altro processo, sul server, il quale, a sua volta, farà in modo di lanciare la procedura chiamata senza che questa si renda conto che non è stata lanciata direttamente dal chiamante ma bensì in modo indiretto.
Per chiarire meglio le idee vediamo la figura 3. Come si può notare nel contesto del processo client viene eseguito il chiamante, la procedura chiamata viene eseguita nel contesto del processo server (come già più volte esposto), il problema fondamentale è che chi scrive l'applicazione non deve vedere questa situazione ma per lui le cose devono funzionare come se si trovasse di fronte alla macchina centralizzata: quindi esistono ambienti di sviluppo che consentono di fare ciò creando automaticamente degli stub (parti in grigio). Lo stub funge praticamente da interfaccia in quanto il chiamante esegue la normale call a procedura ma in realtà, a sua insaputa, viene attivato lo stub che
si mette in contatto con lo stub del chiamato, gli passa i parametri con una delle procedure studiate (send e receive), quindi viene attivata la procedura chiamata che non si accorge di essere stata lanciata dallo stub, esegue le sue operazioni quindi restituisce i parametri allo stub, in modo del tutto analogo vengono ritornati i parametri alla procedura chiamante.
Facciamo ora un passo indietro:
Vediamo un esempio di codice client-server. Figura 10.6 da Tanenbound.
L'analisi di tali procedure è facilitato dai commenti inoltre sono anche auto esplicative.
Suppongo di avere un file-server (utility per creare, leggere, scrivere, cancellare un file). Il server ha una receive bloccante in testa: al momento dell'accensione il server parte e attende, da buon servitore, la richiesta. Questo praticamente è il send stub: quando riceve un messaggio viene sbloccato, quindi fa il case su M1 e lancia la routine che esegue il servizio. Fatta l'operazione mette il risultato in un campo di un messaggio il quale viene spedito con una send al processo client. Il fatto caratterizzate è la receive in testa e la send in coda.
Notiamo che questo server è solo didattico in quanto un buon processo server deve essere multi trend (con più flussi di controllo in grado di evolvere parallelamente). Vediamo come si articola il client: il client vuole copiare un file, infatti fa read e write consecutivamente. Il codice a questo punto non ha bisogno di altre spiegazioni.
Indirizzamento del server:
quando fa faccio una send devo individuare sia la macchina che il processo, vediamo come posso fare ciò:
indirizzo assoluto: individuo un solo indirizzo in cui alcune cifre (generalmente quelle di maggior peso) individuano l'host e altre il processo. Questo tipo d'indirizzamento ha l'inconveniente di non fornire alcuna trasparenza (non possono spostare il processo server su di un'altra macchina).
Identifico il nodo tramite un indirizzo e il processo tramite una mailbox. Ciò implica però che il server quando nasce delle dichiarare la mailbox. Anche in questo caso non ho trasparenza.
Identifico il server mediante un indirizzo assoluto e chiedo quindi al server di identificare il client in modo simbolico. È un tipo strano lasciamolo stare.
Vediamo ora il caso più generale: identifico il processo server mediante un nome simbolico, risolvono la corrispondenza individuando nell'ambito della rete un particolare server che è
un server di nomi, il quale possiede una tabella che restituisce la posizione dell'host e il numero di processo che mi serve. La stessa cosa è fatta nell'esempio su visto con la routine INIZIALIZE.
Altra soluzione è quella di mandare i messaggi su tutta la rete, quello che risponde sarà ovviamente il server.
Altra cosa da sottolineare è il protocollo:
Quando faccio una send posso stare su rete locale o su rete geografica, quindi come faccio a decidere il protocollo da utilizzare?
In generale devo utilizzare un protocollo che si colloca al livello 5 della modello ISO-OSU; un messaggio per me rappresenta un qualcosa che deve essere suddiviso in pacchetti per cui il Kernel utilizzerà un protocollo che probabilmente (dipendere dallo specifico Kernel) ha una routine che affetta il messaggio, mi crea dei pacchetti e li passa a IP sulla rete. L'applicativo sta a livello 5 chiama TC/ IP che sta a livello 5 fa la send al Kernel e spedisce il messaggio sulla rete.
Posso avere dei problemi nel senso dell'efficienza: se mi trovo su di una rete locale è inutile usare TC/IP ma posso usare UDP facendo solo l'affettamento e posso non mettere su IP scendendo direttamente a livello 2.
Nello sviluppo dell'applicativo in genere non si fanno protocolli ad hoc per mantenere la genericità.
Entriamo ora nel merito del problema da cui siamo partiti:
Come si realizzano i client-stub e i server-stub; ovvero come tradurre una chiamata a procedura remota in modo tale che sembri una normale chiamata a procedura.
|
| Appunti su: https:wwwappuntimaniacominformaticacomputersistemi-operativi64php, |
|