|
| Appunti informatica |
|
|
| Appunti informatica |
|
| Visite: 2780 | Gradito: |
Leggi anche appunti:Funzione erroriFUNZIONE ERRORI Scopo: la function calcola l'errore relativo e l'errore La porta parallelaLA PORTA PARALLELA La porta parallela (detta anche LPT) è un'interfaccia usata inizialmente Protezione e SicurezzaProtezione e Sicurezza Si parla di protezione in presenza di meccanismi, messi |
 |
 |
Sistemi Distribuiti: Introduzione
I sistemi distribuiti nascono negli anni '80 con l'introduzione di microprocessori a basso costo e la nascita delle reti di comunicazioni: un sistema distribuito è sostanzialmente un insieme di calcolatori e risorse tra loro interconnessi, in genere secondo il principio per cui la rimozione di un elemento non impedisce al sistema di continuare a funzionare (sebbene con capacità ridotta) e la differenza fondamentale rispetto ad un sistema centralizzato è la molteplicità delle CPU.
I principali vantaggi di un SD sono la velocità di calcolo, la scalabilità (la possibilità di aggiornare e sostituire i singoli componenti lasciando immutato l'impianto complessivo) e la possibilità di implementare una programmazione parallela (ovvero più CPU reali eseguono contemporaneamente processi differenti, eventualmente tra loro cooperanti); i principali svantaggi attengono viceversa ad oggi alla scarsa disponibilità di software (software di base, modesta offerta di software applicativo, ambienti di sviluppo e linguaggi di programmazione ancora poco evoluti), alla minore sicurezza delle informazioni (rispetto ad un sistema centralizzato, a causa della condivisione) e all'overhead aggiuntivo (sempre rispetto ad un sistema centralizzato) introdotto dalle comunicazioni e dai software che si occupano di gestirle.
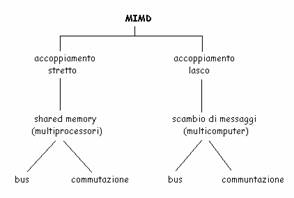
I SD presentano molte possibili architetture, aree applicative, reti di comunicazione tra le varie CPU e SO, e molteplici sono le classificazioni possibili dei SD. Secondo la cosiddetta Tassonomia di Flynn, i sistemi hardware possono essere classificati in:
SISD Single Instruction stream Single Data: un sistema in cui ogni CPU esegue le proprie istruzioni sui propri dati e non c'è condivisione nè di istruzioni nè di dati.
SIMD Single Instruction stream Multiple Data: un sistema in cui ogni istruzione opera su un array di dati.
MISD Multiple Instruction stream Single Data
MIMD Multiple Instruction stream Multiple Data: cioè i sistemi distribuiti.
 Si
può distinguere tra SD su base
geografica - molti calcolatori e molte CPU distribuite geograficamente e
connessi da una rete - e SD concentrati
in un punto - una serie di CPU localmente
interconnesse.
Si
può distinguere tra SD su base
geografica - molti calcolatori e molte CPU distribuite geograficamente e
connessi da una rete - e SD concentrati
in un punto - una serie di CPU localmente
interconnesse.
Si può distinguere tra SD in senso stretto - molteplici CPU variamente interconnesse che consentono a più utenti di lavorare contemporaneamente, eventualmente in modo cooperativo (architettura client/server) - e Sistemi paralleli - molteplici CPU variamente interconnesse dedicate però tutte insieme all'esecuzione di un'unica applicazione che richiede elevata capacità computazionale (calcolo parallelo o distribuito
Si può distinguere tra Sistemi Multicomputer (o a scambio di messaggi) - tante CPU ognuna con la propria memoria locale (SD in senso stretto) - e Sistemi Multiprocessore (o Shared Memory) - tante CPU e una memoria condivisa (Sistemi paralleli).
Si può distinguere tra Sistemi Lascamente Connessi - sistemi con vie di comunicazione a bassa velocità, tipicamente tanti computer che comunicano attraverso una rete locale o geografica (Sistemi Multicomputer) - e Sistemi Strettamente Connessi - sistemi con vie di comunicazione ad alta velocità, tipicamente tante CPU comunicano con una memoria comune tramite un bus condiviso (Sistemi Multiprocessore).
Si può distinguere, in base alla natura del canale di comunicazione, tra Sistemi a Switch (o commutati) - Sistemi lascamente connessi - e Sistemi a Bus - Sistemi strettamente connessi.
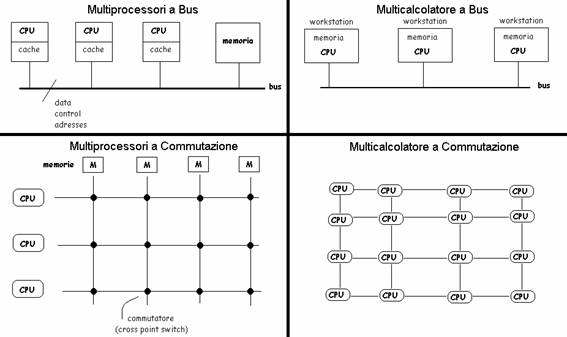 Nei
Sistemi Multiprocessore a Bus, ogni
accesso alla memoria condivisa avviene in modo serializzato tramite bus e ogni
CPU conserva una copia della memoria comune in una cache privata. Il problema della consistenza del contenuto della memoria comune può essere risolto
usando il meccanismo del write-to-cache:
le operazioni di lettura sono fatte localmente, le scritture eseguite in
memoria comune, infine tutte le CPU controllano il bus e quando passa un dato
write questo viene ricopiato nelle memorie cache mantenendole sincronizzate (snoopy cache, cache ficcanaso
Nei
Sistemi Multiprocessore a Bus, ogni
accesso alla memoria condivisa avviene in modo serializzato tramite bus e ogni
CPU conserva una copia della memoria comune in una cache privata. Il problema della consistenza del contenuto della memoria comune può essere risolto
usando il meccanismo del write-to-cache:
le operazioni di lettura sono fatte localmente, le scritture eseguite in
memoria comune, infine tutte le CPU controllano il bus e quando passa un dato
write questo viene ricopiato nelle memorie cache mantenendole sincronizzate (snoopy cache, cache ficcanaso
Nei Sistemi Multiprocessore a Commutazione, se due CPU vogliono accedere alla stessa memoria una delle due viene sospesa e per N CPU occorrono O(n2) cross point.
Un esempio storicamente sorpassato di Multicalcolatore a Commutazione era basato sul transputer, componente ideato negli anni '80 che poteva essere connesso a maglia con altri 4 componenti uguali, ciascuno con una propria CPU e memoria locale: rappresenta un caso limite tra SD in senso stretto (memoria locale) e Sistemi Paralleli (l'insieme dei componenti era impiegato per eseguire un'unica applicazione
Nel seguito ci occuperemo sostanzialmente di SD in senso stretto, in particolare di Workstation lascamente connesse in rete.
Un SO distribuito (cioè un SO per SD) lascamente connesso nasce dai SO delle singole macchine integrati da un software di rete e consente condivisione di risorse (device, file, database, applicazioni, ) e login remoto.
Un SO distribuito strettamente connesso è invece un unico programma distribuito (solo qui si può parlare di vero e proprio SO distribuito), il cui scopo è far apparire all'utente il SD come fosse un sistema monolitico e centralizzato, ed è caratterizzato in linea di principio da un unico meccanismo di gestione dei processi (che i SOD lascamente connessi non offrono), un unico meccanismo di comunicazione globale tra processi (indipendentemente dalla macchina su cui essi girano per il momento non disponibile nella realtà), un unico sistema di protezione/sicurezza degli accessi e da uno stesso Kernel di SO sulle singole macchine (che i SOD lascamente connessi non hanno, necessario invece qui per garantire almeno le prime due caratteristche). Il modo in cui ciò si realizza consiste nell'installare su ogni macchina un MicroKernel, cioè un kernel molto
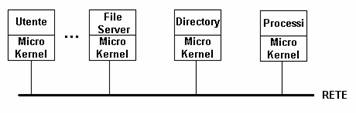 ridotto che fornisce solo i servizi di base (uguali per tutte le macchine) ovvero
proprio i meccanismi di gestione dei
processi, dopodichè ciascuna macchina viene specializzata sovrapponendo al microkernel un software che, visto in
esecuzione come processo di sistema,
realizza la funzionalità specifica prevista: su una macchina opera l'utente, su una macchina opera il file server (i file server oggi esistenti in realtà non operano su un SO
distribuito ma su un SO centralizzato, per cui se il file server opera su una
macchina Unix vedrà il kernel Unix, se opera su una macchina WinNT vedrà il
kernel WinNT), su una macchina opera il server delle directory (che non contiene file utente ma solo file directory, tramite i
quali gestisce l'accesso al FS distribuito), su
un'altra ancora opera un server dei
processi (cioè una macchina specializzata per
decidere su quale macchina del SD vanno allocati o spostati a seconda del
carico i processi utente attualmente non esistono applicazioni commerciali
di questo tipo, solo applicazioni da laboratorio di ricerca
ridotto che fornisce solo i servizi di base (uguali per tutte le macchine) ovvero
proprio i meccanismi di gestione dei
processi, dopodichè ciascuna macchina viene specializzata sovrapponendo al microkernel un software che, visto in
esecuzione come processo di sistema,
realizza la funzionalità specifica prevista: su una macchina opera l'utente, su una macchina opera il file server (i file server oggi esistenti in realtà non operano su un SO
distribuito ma su un SO centralizzato, per cui se il file server opera su una
macchina Unix vedrà il kernel Unix, se opera su una macchina WinNT vedrà il
kernel WinNT), su una macchina opera il server delle directory (che non contiene file utente ma solo file directory, tramite i
quali gestisce l'accesso al FS distribuito), su
un'altra ancora opera un server dei
processi (cioè una macchina specializzata per
decidere su quale macchina del SD vanno allocati o spostati a seconda del
carico i processi utente attualmente non esistono applicazioni commerciali
di questo tipo, solo applicazioni da laboratorio di ricerca
Un primo requisito che un SOD strettamente connesso deve avere è la trasparenza, che può essere di diversi tipi: la trasparenza alla posizione consente all'utente di ignorare la posizione precisa delle risorse (per esempio un file) su cui sta lavorando, la trasparenza alla migrazione consente all'utente di continuare a lavorare su una risorsa (per esempio un file) anche se questo viene spostato su un'altra macchina, la trasparenza alla replicazione consente all'utente di vedere un'unica risorsa (per esempio una stampante) in presenza di più istanze utilizzate secondo necessità (se la stampante A è occupata la stampa è automaticamente redirettata sulla stampante B libera), la trasparenza alla concorrenza consiste nel fatto che il sistema gestisce in modo automatico la mutua esclusione (quindi un accesso sequenziale) alle risorse condivise, la trasparenza al parallelismo - infine - fa sì che il sistema riconosca automaticamente le attività che possono essere eseguite in parallelo (i primi tre tipi di trasparenza hanno già avuto una implementazione, gli altri sono ancora in gran parte futuribili). Un secondo importante requisito è la flessibilità, la cui realizzazione si basa fondamentalmente sull'uso del microkernel comune per tutte le macchine (al quale poi sovrapporre software specifici) che garantisca i servizi di base cui abbiamo già accennato: comunicazione dei processi, gestione base della memoria, gestione base dello scheduling dei processi, I/O di basso livello. Terzo requisito fondamentale è l'affidabilità: tolleranza del sistema al guasto di suoi componenti, capacità del sistema di rimanere disponibile in caso di malfunzionamenti, sicurezza contro l'uso non autorizzato delle risorse. Quarto requisito sono le prestazioni, che dipendono in realtà positivamente dal numero di CPU presenti nel sistema e negativamente dall'overhead introdotto dalle comunicazioni: occorre definire con accuratezza la grana delle computazioni in modo da trovare un compromesso tra prestazioni e tolleranza ai guasti del sistema. Ultimo requisito minimale è la scalabilità, cioè la capacità del SOD di calarsi su un SD indipendentemente dal numero di CPU.
L'OSF (Open Software Foundation) è un consorzio di costruttori, utilizzatori, università e istituti di ricerca, fondato nel 1988 (tra i soci fondatori IBM, DEC, HP, Microsoft, ) per valutare tecnologie UNIX (e altri open systems) e cercare soluzioni tecnologiche che consentano a sistemi di diversi costruttori di lavorare insieme in un unico ambiente aperto.
Il DCE (Distributed Computing Environment) è una piattaforma software completa - definita semplicisticamente una 'scatola di montaggio' software - che comprende i componenti e le tecnologie scelte da OSF necessari alla realizzazione di ambienti di calcolo distribuiti: usando la tecnologia DCE si possono sviluppare applicazioni distribuite senza dover scrivere codice specifico di un certo distributore o per un certo protocollo di rete, quindi portabili su hardware e software differenti. I componenti del DCE si possono immaginare stratificati su due livelli: il livello più basso è quello degli strumenti di programmazione che consentono di costruire le applicazioni (Fundamental Distributed Services), mentre il livello superiore è quello degli strumenti a disposizione dell'utente come i FS distribuiti (Data Sharing Services); i componenti principali del DCE sono il DFS, meccanismi di gestione di un direttorio di oggetti (PC, servizi di rete, ), la Remote Procedure Call, multithreading distribuito, il security service per l'accesso alle risorse e per la protezione dei dati e il time service per la sincronizzazione dei clock dei sistemi in rete. La tendenza è di realizzare sistemi basati sull'implementazione Unix della Digital e, di recente, sono in corso sperimentazioni anche su piattaforme Windows NT.
Sistemi Distribuiti: Architettura Client-Server
L'elemento chiave dei SD in senso stretto (a memoria locale, lascamente connessi) è lo scambio di messaggi tra processi, da una macchina all'altra della rete. Normalmente la comunicazione coinvolge due attori, un trasmettitore e un ricevente: un processo A desidera inviare un messaggio ad un processo B; tuttavia i due processi A e B non comunicano direttamente tra loro, delegano invece la trasmissione/ricezione a processi di più basso livello preposti ad eseguire solo operazioni di questo tipo; i processi trasmettitore/ricevente a loro volta dovranno interagire con processi gestori (device driver) che interfacciano direttamente l'hardware usato per la comunicazione; l'hardware infine strutturerà i messaggi in modo consono alla tecnologia del mezzo trasmissivo in uso. Una comunicazione strutturata a livelli coinvolge (sia dal lato trasmettitore che ricevente) una pila di attori di livello sempre più basso/alto in trasmissione/ricezione, in cui ciascun livello include propri specifici servizi di comunicazione, ciascun attore comunica logicamente solo con il suo corrispondente (dall'altra parte) di pari livello di astrazione utilizzando un certo protocollo (scelto tra un insieme di protocolli specifici di quel livello), ma comunica direttamente solo con il livello immediatamente adiacente attraverso un'apposita interfaccia (che definisce appunto le regole e i formati da utilizzare nella comunicazione tra livelli adiacenti), il quale (livello adiacente) userà a sua volta uno specifico protocollo per comunicare logicamente con l'entità di livello omologo dall'altra parte, e così via fino all'ultimo livello, nel quale la trasmissione/ricezione ha fisicamente luogo: in pratica, ogni servizio di livello i-esimo viene implementato mediante servizi del livello (i-1)esimo e richiede quindi necessariamente il supporto di livelli inferiori. I principali vantaggi della struttura a livelli appena descritta sono l'indipendenza tra i livelli (un livello devo conoscere i servizi offerti dal livello immediatamente inferiore ma non come sono implementati), la flessibilità (una modifica ai servizi offerti da un livello non ha conseguenze sui livelli inferiori e una modifica delle modalità di erogazione di un servizio da parte di un livello non ha conseguenze in generale sugli altri livelli) e la decomposizione (che facilità il progetto modulare dei livelli e la loro manutenzione). Inoltre, presupposto irrinunciabile per la standardizzazione di una specifica struttura a livelli - si pensi al modello ISO/OSI - è l'incapsulamento (o information hiding) delle funzioni che implementano i servizi, perchè solo così si può fare in modo che un livello recepisca molteplici protocolli alternativi tra loro in grado di far comunicare macchine tra loro differenti.
Le reti (di comunicazione) possono essere LAN, MAN e WAN, differenti tra loro per distanza tra i nodi, tecnologia (tipo di rete) di comunicazione e velocità di trasmissione. In una rete LAN (local area network) gli utenti sono dislocati ad una distanza moderata (stesso edificio o stesso campus), l'hardware della rete è costituito da elementi passivi (cavo coassiale, doppino RJ11, cavo UTP, fibra ottica, ) e attivi (hub, bridge, repeater, ) e può produrre configurazioni della rete a bus (cavo coassiale) o a stella (doppino). In una rete MAN (metropolitan area network) gli utenti sono dislocati su un'area metropolitana, la rete è costituita da linee telefoniche e infrastrutture tipiche di un'area metropolitana. In una WAN (wide area network) gli utenti sono a grande distanza, la rete è basata non solo su linee telefoniche ma anche su fibra ottica, microonde e satelliti. In tutti i casi, la velocità di trasmissione dipende dalla particolare tecnologia impiegata e può arrivare fino a 622Mbps (utilizzando ATM
Il modello ISO/OSI (Open System Interconnection definito dall'International Standard Organization) è strutturato in 7 livelli, include sia aspetti hardware che software di una architettura di rete e protocolli sia orientati alla connessione (stabilita tra mittente e destinatario prima della comunicazione) che privi di connessione. Ad ogni messaggio di livello i-esimo viene aggiunta una intestazione (header) prima di essere affidato al livello (i-1)esimo, per cui il messaggio che viaggia sulla rete fisica contiene normalmente molte intestazioni, poi singolarmente rimosse in ricezione durante la risalita tra i livelli: ogni intestazione costituisce un'informazione di gestione e di controllo correttezza che ciascun livello invia al suo omologo sulla macchina remota, mentre il messaggio vero e proprio (destinato al processo destinatario) è annidato all'interno di tutti gli header; se uno dei controlli previsti lungo la risalita del messaggio (tra i livelli in ricezione) fallisce viene tipicamente avviata (in modo trasparente per l'utente) una fase di recovery del messaggio corrotto.
Qui di seguito la descrizione dei 7 livelli del modello ISO/OSI
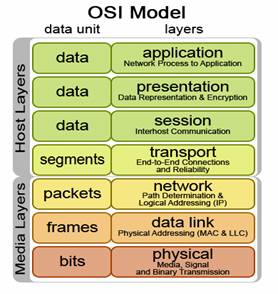 1) Livello Fisico si occupa della trasmissione
di un flusso di dati non strutturati (sequenza di bit) attraverso un
collegamento fisico, sovrintendendo
alla gestione delle procedure meccaniche ed elettroniche necessarie a
stabilire, mantenere e disattivare un collegamento fisico. In questo
livello si decide la modalità di rappresentazione
fisica dei bit (scelta delle tensioni
associate ai valori 1 e 0), la velocità di trasmissione (durata del
segnale che identifica un bit), la direzionalità della trasmissione (unidirezionale
o bidirezionale), il mezzo di comunicazione e la forma (e
la meccanica) dei connettori. I principali protocolli
di livello sono il Bluetooth (wireless a 2,45Ghz), il DSL (Digital Subscriber Line,
trasmissione digitale su ultimo miglio del doppino telefonico), l'RS-232 (comunicazione seriale) e l'UWB (Ultra
Wide Band
1) Livello Fisico si occupa della trasmissione
di un flusso di dati non strutturati (sequenza di bit) attraverso un
collegamento fisico, sovrintendendo
alla gestione delle procedure meccaniche ed elettroniche necessarie a
stabilire, mantenere e disattivare un collegamento fisico. In questo
livello si decide la modalità di rappresentazione
fisica dei bit (scelta delle tensioni
associate ai valori 1 e 0), la velocità di trasmissione (durata del
segnale che identifica un bit), la direzionalità della trasmissione (unidirezionale
o bidirezionale), il mezzo di comunicazione e la forma (e
la meccanica) dei connettori. I principali protocolli
di livello sono il Bluetooth (wireless a 2,45Ghz), il DSL (Digital Subscriber Line,
trasmissione digitale su ultimo miglio del doppino telefonico), l'RS-232 (comunicazione seriale) e l'UWB (Ultra
Wide Band
2) Livello Data-Link si occupa del trasferimento affidabile di dati attraverso il livello fisico, ovvero tenta di far apparire al livello superiore il mezzo fisico come una linea di trasmissione esente da errori. In questo livello, l'operazione di framing (tramatura) frammenta i dati in blocchi, indipendentemente dalla semantica dei singoli byte, e li incapsula in pacchetti, detti frame, provvisti di header e tail, intestazioni che contengono tipicamente un codice di controllo per errori (checksum) e numeri progressivi di frame per la sincronizzazione del flusso: per ogni pacchetto ricevuto, il destinatario invia al mittente un pacchetto ACK (acknowledgement, conferma) contenente lo stato della trasmissione, sicché il mittente ripete l'invio dei pacchetti persi o corrotti (per ottimizzare l'invio degli ACK si usa una tecnica detta piggybacking, che consiste nell'accodare ai messaggi in uscita gli ACK relativi ad una connessione in entrata, per ottimizzare l'uso del livello fisico); lo scambio di bit di stato tra mittente e destinatario può anche servire, in caso di sbilanciamento di velocità di trasmissione, a rallentare la macchina più veloce, minimizzando così le perdite dovute a sovraccarico. I principali protocolli di livello sono ADCCP (Advanced Data Communication Control Procedure, dell'ANSI), HDLC (High level Data Link Control, dell'ISO), SDLC (Syncronous Data Link Control, della SNA) e PPP (Point to Point Protocol) per le connessioni punto-punto, protocollo standardizzato IEEE 802.2 riferito al LLC (Logical Link Control, sottostrato superiore del livello data-link) e orientato al controllo di flusso, protocollo CSMA/CD (Carrier Sense Multiple Access / Collision Detection) riferito al livello MAC (Media Access Control, sottostrato inferiore del livello data-link), i protocolli Ethernet e Token Ring (802.4) basati su CSMA/CD, FDDI (Fiber Distributed Data Interface, basato su fibra ottica), Wi-Fi (802.11) e ATM (Asynchronous Transfer Mode, a commutazione di cella anzichè di pacchetto). Lo standard IEEE 802.3 descrive una tecnologia per reti LAN derivata nel 1985 dalla precedente tecnologia Ethernet (anche se erroneamente 802.3 e Ethernet vengono usualmente considerati sinonimi) che nella pila ISO/OSI occupa il livello fisico e il sottostrato MAC del livello data-link. IEEE ha infatti ritenuto opportuno dividere il livello data-link in due parti: LLC comune a tutti gli standard della famiglia 802.2 e MAC sottolivello più strettamente legato al livello fisico, le cui diverse implementazioni hanno il compito di offrire un'interfaccia comune al livello LLC. Le caratteristiche di 802.3 sono ben riassunte dal protocollo CSMA/CD su cui si basa: Carrier Sense, cioè ogni stazione sulla rete locale ascolta continuamente il mezzo trasmissivo; Multiple Access, il mezzo trasmissivo è condiviso da ogni stazione; Collision Detection, le stazioni sono in grado di rilevare la presenza di collisioni dovute alla trasmissione simultanea e reagire di conseguenza. Per Ethernet e 802.3 il mezzo fisico di trasmissione è il bus, secondo diverse specifiche di livello fisico quali 10BaseT su due doppini intrecciati non schermati (UTP3, Unshielded Twisted Pair, di derivazione telefonica), 10Base2 su cavo coassiale sottile (Thin Ethernet) e 10Base5 su cavo coassiale spesso (Thick Ethernet). L'utilizzo di dispositivi come gli Hub (che è possibile definire "ripetitori multiporta") consente di ottenere un collegamento logico a bus con un collegamento fisico a stella (gli hub possono essere collegati in cascata realizzando anche una complessa topologia ad albero, purchè non si creino cicli). Un bridge (ponte) è un dispositivo di rete più evoluto (si colloca al livello data-link) in grado di riconoscere i frame, individuando indirizzo del nodo mittente e del nodo destinatario: consente di connettere più segmenti di una stessa rete e invia selettivamente un frame solo verso il segmento nel quale presumibilmente si trova il destinatario. Ancor più evoluto è lo switch (commutatore), dispositivo di rete (collocato sempre a livello data-link) che, collegato direttamente agli host (anzichè a interi segmenti di rete), inoltra i frame direttamente al destinatario consentendo di aumentare l'efficienza di una rete Ethernet anche di un fattore 10, riducendone le collisioni. Lo standard IEEE 802.5, alias Token Ring, definisce una rete ad anello con passaggio del testimone, un particolare messaggio detto token, in cui l'host che lo detiene acquisisce il diritto di trasmettere sul bus circolare, dopodichè il token viene passato al prossimo host. Indipendentemente dallo standard adottato, tipicamente il cablaggio prevede per ogni palazzo un centro stella principale e centri stella sui diversi piani, tutti connessi tra loro in fibra ottica: collegati alla rete vi sono sia computer che apparecchi telefonici.
3) Livello Rete si occupa di stabilire, mantenere e terminare una connessione, garantendo il corretto e ottimale funzionamento della sottorete di comunicazione, e mascherando ai livelli superiori i meccanismi e le tecnologie di trasmissione usate per la connessione. In questo livello si garantisce: l'instradamento (routing) ottimale dei pacchetti (unità dati fondamentale del livello) attraverso i router (instradatore), dispositivi di rete (collocati a livello network) che collegano tra loro intere sottoreti; la gestione della congestione, evitando che troppi pacchetti arrivino allo stesso router contemporaneamente; l'indirizzamento e la conversione delle informazioni trasportate (traduzione degli indirizzi ed eventuale ulteriore frammentazione dei dati) nel passaggio da una rete ad un'altra con caratteristiche differenti. Al livello appartengono protocolli orientati alla connessione come X.25 e protocolli privi di connessione come IP (Internet Protocol).
4) Livello Trasporto è il primo livello realmente end-to-end, cioé da host sorgente a destinatario. A differenza dei livelli precedenti (che si occupano di connessioni tra nodi contigui di una rete), questo livello si occupa solo del punto di partenza e di quello di arrivo, si occupa di effettuare la frammentazione dei dati provenienti dal livello superiore in segmenti / messaggi (unità dati fondamentale del livello), e di trasmetterli in modo affidabile (controllo degli errori e delle perdite), trasparente (usando il livello rete ed isolando da questo i livelli superiori) ed efficiente (cercando di prevenire la congestione). Al livello appartengono TCP (Transfer Control Protocol, orientato alla connessione) e UDP (Universal Datagram Protocol, non orientato alla connessione), ambedue implementati con protocolli di livello inferiore (tipicamente IP).
5) Livello Sessione si occupa di gestire l'apertura e la terminazione di una connessione logica tra un nodo e la rete, e durante la fase di colloquio si occupa della sincronizzazione dei messaggi inviati.
6) Livello Presentazione si occupa di trasformare i dati forniti dal livello superiore in un formato standard, fornendo servizi aggiuntivi di crittografia, compressione e riformattazione.
7) Livello Applicazione si occupa di interfacciare i processi (attori della comunicazione) delle applicazioni e inoltra le richieste a livello presentazione
Alternativo al modello ISO/OSI c'è il modello TCP/IP, uno standard de facto con soli 5 livelli
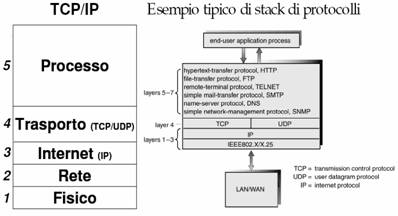
Un'applicazione client-server è un tipo di applicazione nella quale è possibile identificare due processi distinti ma cooperanti: un processo client richiede un servizio ad un processo server, che a sua volta gli restituisce un risultato; in verità due processi siffatti che vengano eseguiti in modo strettamente sequenziale non realizzano un'applicazione client-server, dal momento che il modello client-server richiede che ci sia un dialogo tra essi; analogamente, anomalo è il caso in cui i due processi vengano eseguiti totalmente in modo parallelo, dal momento che un client (per definizione) deve rimanere bloccato (in attesa) finchè il server non ha risposto alla sua richiesta. Più semplicemente, si può dire che i sistemi client-server sono un'evoluzione dei sistemi basati sulla condivisione semplice delle risorse: la presenza di un server permette ad un certo numero di client di condividerne le risorse, lasciando che sia il server a gestire gli accessi alle risorse per evitare conflitti.
Ragionando su un SD, è interessante valutare in che modo sia possibile distribuire una applicazione (tipicamente multiutente) su più macchine collegate tra loro in rete, in alternativa al classico schema centralizzato con terminali stupidi direttamente connessi ad un unico host. In una architettura master-slave, i terminali stupidi sono collegati ad una macchina che li gestisce direttamente e questa a sua volta è collegata ad un host: l'applicazione vera e propria risiede sull'host e i terminali gestiscono solo l'input/output. Più evoluta è l'architettura client-server, in cui si assiste ad un capovolgimento di logica: l'avvio dell'applicazione non avviene sull'host (server) bensì sul client stesso, che quindi non è in generale un terminale stupido. Ancor più sofisticata è una architettura peer-to-peer (da pari a pari), tipica delle macchine parallele, nella quale (anzichè un unico servente e più clienti) si hanno più processi che cooperano tra loro senza gerarchie di tipo master/slave (un processo può richiedere a B dei dati, che questo invierà a C per richiedere un ulteriore servizio
Con particolare riferimento ad una architettura client-server, in generale si può descrivere una situazione tipica in cui c'è una serie di macchine client (non stupide) su cui gira parte di una applicazione, connesse attraverso una rete LAN o WAN ad una macchina server, su cui gira la restante parte dell'applicazione, che si occupa di gestire le risorse condivise dai client. Naturalmente la sofisticazione di una tale architettura cambia a seconda di come l'applicazione viene partizionata tra le macchine client e server. Una multi-tier architecture (o più tipicamente three-tier architecture) è una architettura multistrato nella quale si usa generalmente distinguere la presentation logic (o presentation tier) - l'interfaccia utente, la business logic (o logic tier) - ovvero gli algoritmi funzionali che gestiscono lo scambio di informazioni tra l'interfaccia utente e un database - e la database logic (o data tier) - modulo di accesso e gestione dei dati (tipicamente un DBMS), memorizzati generalmente su uno storage a sua volta indipendente. Orbene, la soluzione di partizionamento più banale che si possa concepire consiste nel mettere sui client la sola presentation logic e tutto il resto sul server, oppure (in modo ancora più drastico) è possibile concepire i client come semplici emulatori di terminali e tutto viene gestito dal server: ambedue appaiono immediatamente soluzioni insoddisfacenti perchè le macchine client sono sottoutilizzate.
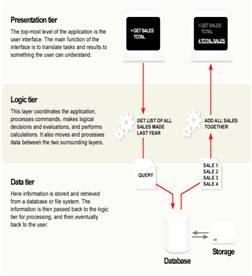
Altro partizionamento classico (comunque largamente utilizzato, già abbastanza sofisticato) consiste nel lasciare sul server il solo DBMS, portando sui client tutto il resto dell'applicazione: in tal caso si parla semplicemente di database server. Altra possibilità consiste nel mettere sui client la presentation logic e parte della business logic, mentre la restante parte viene distribuita su 2 o 3 macchine che lavorano in parallelo (architettura P2P
Sono state già analizzate in precedenza le diverse primitive di Send e Receive, così come la RPC, fondamentali in ogni modello di interazione tra processi basato sullo scambio di messaggi, in particolare su una rete. Nell'ambito della comunicazione tra client e server, il primo esegue una qualche Send di richiesta di un servizio al server, e questo deve rispondere: occorre risolvere un serie di problemi legati a questo dialogo.
Prima di tutto occorre stabilire in che modo eseguire l'indirizzamento al server: si può scegliere di utilizzare un indirizzo assoluto, nel quale alcune cifre (le più significative) individuano l'host e le altre il processo (questa soluzione non fornisce alcuna trasparenza dacché il processo server non può essere spostato); si può identificare il server tramite un indirizzo e il processo tramite una mailbox, il che implica però che quando il server "nasce" deve dichiarare la mailbox (anche in questo caso non c'è trasparenza); si può identificare il server con un indirizzo assoluto chiedendo poi al server stesso di assegnare ai client identificativi simbolici; si può assegnare al processo server un nome simbolico risolvendo (a tempo di esecuzione) la corrispondenza con l'host effettivo e il processo servente attraverso un opportuno server di nomi; si può, infine, inoltrare i messaggi sempre a tutti gli host, attendendo che il server (e solo esso) si identifichi, rispondendo al messaggio.
In secondo luogo occorre decidere quale protocollo utilizzare quando si esegue la Send, perchè il destinatario può stare su rete locale o geografica: si può usare un protocollo di livello 5 (nella pila ISO/OSI) per gestire la sessione, il messaggio viene suddiviso in pacchetti attraverso un protocollo di livello 4 (TCP o UDP) inviati poi sulla rete tramite un protocollo di livello 3 (IP); si tenga presente comunque che protocolli differenti a livello 2 (Ethernet piuttosto che ATM, per esempio) hanno limiti di lunghezza dei pacchetti (Maximum Transmission Unit) differenti e chiaramente il framing produrrà uno spezzettamento più o meno spinto dei messaggi originari: in generale conservare messaggi grandi velocizza il trasferimento, tuttavia inviare sulla rete pacchetti piccoli può costituire un vantaggio dacché consente, in caso di errore, di recuperare (richiedendone la rispedizione) la sola porzione del messaggio corrotta. Tipicamente si adotta il TCP/IP, che però può essere inefficiente se ci si trova su una rete locale, nel qual caso si può optare per un UDP direttamente su protocollo di livello 2 (per esempio, se gli host sono connessi tramite un bus non c'è possibilità che la sequenza ordinata dei pacchetti si alteri, per cui la funzionalità di ordinamento dei pacchetti di TCP è superflua). In ogni caso, nello sviluppo di un applicativo, non si utilizzano protocolli ad hoc per conservare la genericità.
Una volta individuato l'host destinatario e il protocollo da usare, il terzo requisito è la trasparenza nell'esecuzione della RPC: serve uno stub lato client che esegua effettivamente la Send e uno stub lato server che esegua la Receive, che si interfaccino rispettivamente con la procedura chiamante e la procedura chiamata (la procedura chiamante sull'host client riconoscerà come procedura chamata lo stub lato client, la procedura chiamata riconoscerà come procedura chiamante lo stub lato server) e che comunichino tra loro tramite la rete scambiandosi (opportunamente impacchettati) parametri (con la tecnica del copy and restore) e risultati. In realtà, chi sviluppa l'applicazione si preoccupa solo delle procedure chiamante/chiamata e non dei dettagli dell'architettura client-server su cui l'applicazione opererà: della creazione degli stub e della mappatura su di essi della RPC (che sintatticamente è identica ad una qualunque chiamata a procedura) si occupa, in modo trasparente per l'utente, direttamente l'ambiente di sviluppo. Inoltre, l'applicazione lato client e quella lato server potrebbero girare su host con architetture differenti che abbiano una diversa rappresentazione dei dati (numeri rappresentati in virgola fissa o mobile con diverso numero di bit per mantissa ed esponente, numeri rappresentati in formato big-endian anzichè little-endian, uso di caratteri ASCII oppure non standard, uso di stringhe di bit differenti per rappresentare i valori logici true o false) e occorre garantire, ancora in modo trasparente per l'utente, l'interoperabilità tra formati differenti, il che può avvenire secondo due strategie: si può fare riferimento ad una rappresentazione canonica, ovvero tutti i dati, qualunque sia il loro formato all'origine, vengono convertiti dagli stub in un formato terzo comune al lato client e server (il che genera overhead inutile nel caso in cui le architetture degli host siano uguali); oppure, l'ambiente di sviluppo può prevedere un linguaggio di descrizione del client e del server (usato nel messaggio di domanda e risposta) e routine di conversione agganciate agli stub, di modo che le conversioni avvengano secondo necessità contingenti direttamente a monte e/o a valle della comunicazione nel modo più efficiente. Si è detto, infine, dello scambio di parametri attraverso la tecnica del copy and restore, usata per i parametri passati per riferimento (A viene prelevato dalla sua locazione di memoria e copiato nel messaggio, dopodichè A' modificato dalla RPC viene ricopiato nella locazione di memoria originaria): in realtà essa è necessaria solo quando un parametro è di input/output ma ridondante negli altri casi (si può evitare il copy se è di output, si può evitare il restore se è di input) per cui l'ambiente di sviluppo deve prevedere nell'interfacciamento (tramite gli stub) tra la procedura chiamante e chiamata anche la possibilità di indicare se i parametri scambiati sono di input o di output.
Si è parlato all'inizio del problema dell'indirizzamento del server. Una soluzione ottimale (che combina le ultime due strategie citate) consiste nel definire un particolare processo Binder (collegatore) di nomi che conosce l'allocazione dei diversi processi server sulla rete ed è in grado di associare al nome simbolico di un server l'indirizzo fisico di un host e il PID del processo server. In realtà il binder esso stesso è un server, può non stare sempre sulla stessa macchina e può essere replicato su più macchine (per evitare che costituisca un collo di bottiglia a causa delle eccessive richieste), per cui si pone il problema di rendere nota la sua posizione ai client che devono interpellarlo: quando il client esegue per la prima volta il suo stub (fase di test dello stub), all'atto dell'invio del suo primo messaggio, esso manda in broadcast un messaggio di richiesta per un certo server e il binder lo intercetta rispondendo adeguatamente; d'altra parte, ogni qualvolta il binder si sposta su un'altra macchina, manda a sua volta in broadcast un messaggio di identificazione per aggiornare le informazioni di indirizzamento dei client. Il binder gestisce al suo interno una tabella in cui a ogni nome simbolico di server corrisponde un indirizzo e degli attributi: quando un server esegue per la prima volta il suo stub, all'atto della sua prima attivazione, esso si registra sul binder rimanendo poi in attesa di messaggi dei client, viceversa esso si deregistra dal binder prima di terminarsi; si noti che con questo sistema, se un server non è pronto (e quindi non è nemmeno registrato sul binder) automaticamente non risulta rintracciabile. Si noti infine che l'uso di un binder consente di implementare meccanismi di sicurezza (un client accede ad un server solo passando attraverso il binder, che dunque può filtrare le richieste) e di gestione dell'aggiornamento dei server (quando ad un server viene applicato un aggiornamento delle routine i client che non hanno subito il medesimo aggiornamento, risultando non allineati, possono patire malfunzionamenti all'atto del collegamento: il binder può bloccare l'accesso ai client con software non aggiornati
I principali problemi che un'applicazione client-server può incontrare sono legati alla caduta dei client o a malfunzionamento o caduta dei server. Può succedere che un client non riesce ad identificare il server: se manca il binder la richiesta del client va in timeout e il tentativo di comunicazione termina. Può succedere che la richiesta/risposta del client/server si perde: la perdita di un messaggio di richiesta viene risolto dal lato client reinviando ciclicamente la richiesta (fino ad un numero massimo di volte) ogni volta che scatta un timer (gestito dallo stub), mentre la perdita di un messaggio di risposta dal lato server può in generale non essere gestita, nel senso che in caso di mancata risposta sarà il client (non avendola ricevuta) a rieffettuare la richiesta e il server si limiterà a rispondere nuovamente; in quest'ultimo caso, il problema può sorgere se le richieste replicate inviate al server sono non idempotenti (per cui la replicazione di un'operazione, ad esempio l'incremento di un puntatore, può risultare indesiderata) e la soluzione consiste sostanzialmente nel numerarle: il server può riconoscere dal numero del messaggio il caso in cui ha già servito quella richiesta e può quindi inviare solo una nuovo messaggio di risposta senza replicare l'operazione. Può succedere, ancora, che un server vada fuori servizio dopo aver ricevuto una richiesta ma prima di aver risposto: problema serio perchè può causare inconsistenza sui dati gestiti dal server (per esempio se è un DB server). Può succedere, infine, che un client vada fuori servizio dopo aver inviato una richiesta ma prima di aver ricevuto risposta: i messaggi introdotti sulla rete dal server non vengono raccolti da nessuno e scadono naturalmente (si pensi al campo TTL - Time To Live - dei pacchetti IP
Sistemi Distribuiti: File System Distribuiti
Il FS distribuito (DFS) è probabilmente l'aspetto più interessante di un SD. Una rete può ospitare (connessi tra loro) host e terminali passivi, e questi ultimi possono essere connessi alla rete direttamente oppure tramite un altro host (architettura master-slave). In tutti i casi, un utente che lavora su un terminale qualunque vuole vedere il DFS della rete in modo perfettamente analogo all'FS monolitico della macchina cui è direttamente collegato, senza accorgersi della differenza, in perfetta trasparenza: in realtà, nei SD odierni, questo requisito non è comunque mai completamente soddisfatto e in molti casi, per poter operare correttamente, l'utente ha addirittura bisogno di capire come il FS è distribuito esattamente sulla rete.
I servizi offerti da un DFS (relativi a file e directory) sono in realtà forniti da processi server creati dal SO e collocati su qualche macchina, e coincidono tipicamente con quelli offerti da un comune FS monolitico di una macchina centralizzata. In realtà i classici servizi di Open/Close file offerti da un FS monolitico (che sfruttano una cache per velocizzare le operazioni) possono essere sconvenienti in un DFS a causa dei problemi che la scelta e la gestione della cache comporta: il caricamento di un file remoto su una cache locale può generare inconsistenza dei dati in caso di modifica o caduta del client. Alcuni FS consentono l'Open/Close dei file (adottano quindi chiaramente meccanismi di mutua esclusione nell'accesso ai file e di tutela della consistenza) e si dice che hanno File Server con stato, viceversa in alcuni altri FS i File Server sono privi di stato, cioè non offrono i servizi di Open/Close dei file, l'utente non può quindi richiedere l'esplicita apertura di un file e questo viene automaticamente aperto e chiuso ad ogni operazione di Read/Write: ad ogni lettura/scrittura, client e File Server si scambiano (con appositi messaggi) le informazioni sulla specifica operazione di apertura-lettura o apertura-scrittura, dopodiché il FS può dinamicamente decidere se eseguire effettivamente ogni volta l'apertura (e poi la chiusura) del file oppure se portarlo nella sua cache, e operare successivamente direttamente su di essa (il tutto in modo occulto al client). Si tenga presente inoltre che le operazioni sui file possono essere implementate secondo due distinte strategie: la prima (caso più semplice) prevede solo un meccanismo di upload/download, ovvero ogni accesso ad un file produce il suo scaricamento totale sul client e la contemporanea definizione di un lock per impedirne ad altri l'accesso (per salvaguardare la consistenza), dopodiché, eseguite le operazioni, il file ormai aggiornato viene ritrasferito sul server remoto e il lock rilasciato; la seconda strategia (maggiormente flessibile) prevede invece l'accesso selettivo ad un singolo record di un file, purchè non locked, ovvero il FS server (gestendo in maniera dinamica il file tra il disco e la sua cache) si occupa solo di impedire che due processi operino simultaneamente in scrittura o lettura/scrittura su uno stesso record, ma consente il parallelismo degli accessi a record differenti o anche la sola lettura su un record acceduto in modo condiviso. Il NFS (Network File System) della Sun è un DFS che ha file servers privi di stato che non supportano l'Open/Close dei file.
La struttura delle directory in un FS può avere diverse implementazioni: in una macchina DOS c'è una foresta di alberi (singoli alberi dei singoli dischi rigidi e albero del floppy), in una macchina Windows c'è un unico albero (quello della gestione risorse), in una macchina UNIX c'è un unico grafo aciclico rispetto al quale bisogna fare il mounting (ovvero un innesto) dell'albero del floppy. Nei FS distribuiti l'obiettivo è mostrare all'utente osservatore un unico albero, indipendentemente dalla posizione dell'utente nella rete. Tale obiettivo non viene comunque garantito dai FS distribuiti più rudimentali (come NETWARE) dove compaiono più alberi distinti, alcuni dei quali riferiti a dischi virtuali (immagini di dischi remoti), con gli inconvenienti che ciò comporta: l'utente vede una foresta di alberi distribuiti su più macchine ed è inoltre vincolato alla sua postazione di lavoro, dacché la sua visione del FS dipende proprio da essa, mentre invece sarebbe utile che da ogni postazione fosse visibile un unico albero. Altri FS distribuiti sono invece più evoluti Il NFS (Network File System) della Sun funziona su qualsiasi rete PC e Unix offre sia una visione unitaria sia viste parziali (utile per utenti che usano sempre la stessa postazione e le stesse applicazioni) del FS, presupponendo però l'operazione di mounting (fattibile in modo differente in diversi punti della rete), che avviene automaticamente al boot del sistema oppure alla prima richiesta di un file remoto (automounting), evitando quindi che un server spento sia comunque visibile nell'albero generando un errore nell'accesso ad un file non disponibile: ogni volta che un server si attiva (boot) o più efficientemente quando un client richiede un file che risiede su di esso, l'host client riceve dal server in questione la lista dei suoi alberi di directory importabili e ne fa il mounting sul proprio sottoalbero locale. Il Andrew File System della Transare, nato per gestire la condivisione di file tra un gran numero di studenti universitari, consente a ciascun utente di avere una vista con un unico albero, avente un sottoalbero standard da un lato e un sottoalbero generato dal mounting del floppy dall'altro (visibile comunque da ogni macchina
Il naming dei file (come i file vengono nominati) è un altro aspetto fondamentale. Tipicamente un file viene nominato con un path che inizia col nome simbolico del server che lo ospita, il che lo rende certamente trasparente alla locazione (perchè posso cambiare la macchina fisica associando ad essa lo stesso nome simbolico) ma non trasparente alla posizione (è difficile ottenere di svincolare completamente il nome del file anche solo da un nome simbolico contingentemente legato ad una specifica macchina
Il principale problema che si incontra quando si implementa la condivisione è il rischio di inconsistenza dei dati: una semantica della condivisione fornisce i criteri di comportamento che il FS assume quando due o più utenti condividono un file e hanno contemporaneamente più sessioni aperte su quel file, definendo il modo in cui il singolo utente deve può produrre modifiche al file e vedere quelle apportate da altri utenti. La semantica Unix prevede che, ogni volta che un utente altera un file condiviso, le modifiche vengano rese immediatamente disponibili agli utenti che hanno una sessione aperta su quel file: strategia ovvia e relativamente facile da implementare su un sistema centralizzato, meno facile invece da mettere in pratica in un sistema distribuito, ancor di più se il file condiviso è caricato nelle cache dei singoli client (con i conseguenti disallineamenti tra "cache client" e "disco server"). Altra strategia semplice da implementare è basata su una semantica delle sessioni, ovvero quando un utente apre una sessione di accesso ad un file condiviso, egli carica per sè una immagine totale del file così com'è al termine della precedente sessioni di lavoro, ogni modifica viene apportata su questa copia personale, totalmente svincolata dalla prima copia, e al termine della sessione la copia modificata sostituirà in toto quella originale; si noti che questa strategia supporta perfettamente (e presuppone anzi) il caching dei dati rendendone facile l'implementazione sui sistemi distribuiti; in realtà, comunque, il principale difetto di questa strategia è frutto proprio la sua semplicità, dal momento che se, due utenti aprono due sessioni di lavoro sullo stesso file e lo modificano in modi diversi, alla fine sopravvivono solo le modifiche apportate dall'utente che chiude per ultimo la sessione, mentre le altre vanno totalmente perdute: si assume in questo caso che il SO fornisce una strategia per la condivisione, ma se questa è giudicata insoddisfacente dall'applicazione allora sarà quest'ultima a mettere in campo specifici meccanismi supplementari per risolvere autonomamente il problema. L'adozione di una semantica dei file immutabili fa sì che il FS ammetta operazioni di lettura (non critiche per la consistenza di un file condiviso) ma non di scrittura, e per modificare un file esistente occorre necessariamente crearne uno nuovo (nella stessa directory) e poi sostituirlo al precedente; in realtà qui si riscontra lo stesso problema della semantica delle sessioni (due utenti creano due file modificati e li sostituiscono alla copia originaria, ma solo l'aggiornamento ultimo in ordine di tempo sopravvive) e in più resta da stabilire cosa fare se un utente sostituisce un file mentre un altro lo sta leggendo: in Unix l'utente in lettura continua a vedere una copia temporanea con il precedente contenuto, che poi può eventualmente essere ripristinato. Infine, una semantica delle transazioni concepisce ogni operazione di scrittura come transazionale, ovvero indivisibile (atomicità) che non produca inconsistenze (consistenza) indipendente dall'esecuzione contemporanea di altre operazioni (isolamento) e i cui effetti siano persistenti (durability): un transaction monitor garantisce in pratica una mutua esclusione nell'accesso alla risorsa file condivisa, serializzando le operazioni e garantendo in caso di fallimento di una di esse il suo disfacimento (rollback) a salvaguardia della consistenza.
Come si è visto, nell'ambito della condivisione, il caching consiste nel trasferire in memoria centrale la copia dei dati su cui l'host sta lavorando (lettura o scrittura) al fine di ridurre al minimo l'interscambio tra server e client, tuttavia bisogna associare ad esso una opportuna semantica di condivisione (necessaria, perchè deve gestire il riallineamento delle modifiche tra client e server) che consenta di salvaguardare la consistenza dei dati. Il caching a livello server non costituisce un caso interessante perchè non produce alcun problema. Viceversa, con il caching a livello client si tende sostanzialmente a ridurre il traffico sulla rete (i dati vengono trasferiti una volta sola, le modifiche sono locali sulla cache), ma quando al caching viene associata una semantica di condivisione complicata da realizzare, può aversi sulla rete un traffico di messaggi superiore a quello che si è cercato di evitare con il caching, annullandone quindi gli effetti positivi (caso limite è dato dall'accoppiamento tra caching e semantica UNIX, con cui il traffico sulla rete diventa proibitivo). Le politiche di aggiornamento della cache sono descrivibili nel caso significativo di unico server e due client (A scrive sul file condiviso, B lo legge soltanto) e sono la scrittura diretta, la scrittura ritardata e la scrittura su chiusura. Secondo la scrittura diretta ogni volta che A scrive sulla propria cache viene mandato un messaggio di aggiornamento del record modificato anche al server, il che equivale a non sfruttare i benefici della cache in scrittura ma solo in lettura (per ogni lettura succesiva non c'è bisogno di traferire dati dal server in quanto la cache locale è già allineata al server): tale politica risolve il problema del crash improvviso del client ed è compatibile con qualunque semantica, ma genera elevato traffico sulla rete e occorre un meccanismo supplementare (come quello alla base della semantica Unix) che si occupi di propagare l'allineamento anche a B che stanno leggendo una copia (ormai vecchia) dei record modificati. Secondo la scrittura ritardata le modifiche ai dati prodotte da A sulla propria cache vengono inviate al server solo periodicamente (il tempo può essere scandito da un timer): pur riducendo un minore traffico sulla rete rispetto alla politica precedente, questa NON risolve il problema del crash, NON é compatibile con qualunque semantica (essendo intrinsecamente incompatibile con la semantica Unix) e permane immutata la necessità di propagare l'allineamento anche a B, il che può essere realizzato comunque con una semantica Unix-like (cioè eseguita in differita, dopo un certo delay dipendente dal timer sopra citato). Nella scrittura su chiusura, infine, l'aggiornamento del file su server viene eseguito da A solo a sessione di scrittura completata: il traffico sulla rete è ulteriormente ridotto, NON si risolve il problema del crash, l'unica semantica veramente compatibile è la semantica delle sessioni (non si può usare più nemmeno una semantica Unix-like) e permane immutata la necessità di propagare l'allineamento anche a B. Le politiche per garantire l'allineamento (o coerenza) tra server e client sono essenzialmente l'approccio garantito dal server e l'approccio garantito dal client. Secondo l'approccio garantito dal server quest'ultimo gestisce una maxi-tabella contenente informazioni sui dati di cui i diversi client dispongono una copia in cache, per cui ogni volta che riceve un aggiornamento da uno di esso provvede a contattare gli altri per propagarglielo: in realtà questo approccio è abbastanza oneroso (la maxi-tabella va scansionata interamente anche molto frequentemente) e ha il difetto di trasformare un server in client dei client, cui di fatto finisce per chiedere un servizio. Nell'approccio garantito dal client quest'ultimo associa ad ogni record un bit di validità che dipende da un timer, per cui alla scadenza il client stesso richiede al server una nuova copia di quel record (più frequentemente si usa aggiornare l'intera cache), inglobando quindi gli aggiornamenti occorsi fino a quel momento: questo approccio va bene sia con un scrittura ritardata associata ad una semantica Unix-like, sia con una scrittura su chiusura associata ad una semantica delle sessioni. Il NFS (Network File System) della Sun adotta una semantica della condivisione di tipo Unix-like, con scrittura ritardata ogni 30 secondi e politica di approccio garantita dal client gestita da 2 timer, uno per i record dati condivisi (3 secondi) e uno per i record directory (30 secondi), dacchè i primi vanno aggiornati più frequentemente dei secondi: quando il client accede ad un record nella cache ne controlla il bit di validità e, se il daemon è già scattato resettandolo, viene richiesto al server un nuovo trasferimento del record di interesse.
|
| Appunti su: sistemi distribuiti appunti scuole superiori, architetture sistemi distribuiti scuole superiori, https:wwwappuntimaniacominformaticacomputersistemi-distribuiti-introduzio83php, |
|