|
| Appunti informatica |
|
|
| Appunti informatica |
|
| Visite: 2728 | Gradito: |
Leggi anche appunti:Il dispositivo priority interrupt controllerIl dispositivo PRIORITY INTERRUPT CONTROLLER I campi relativi alla configurazione L'inventore del microprocessoreL'inventore del microprocessore Sono passati quasi trent'anni dalla sua straordinaria La quarta generazione: dal 68' ad oggi - microprocessoriLa quarta generazione: dal 68' ad oggi - microprocessori La quarta generazione |
 |
 |
LA GESTIONE DELLA MEMORIA
Le tecniche che sono state studiate fino ad oggi per la gestione della memoria possono essere raggruppate in due grandi classi:
1) Tecniche che richiedono che il codice e i dati di un processo siano integralmente contenuti nella memoria RAM;
2)Tecniche che richiedono che il codice e i dati di un processo siano solo in parte contenuti nella RAM.
Quando il processo è running, è necessario in ogni caso che tutti i sui dati e tutte le sue istruzioni siano presenti in uno spazio di memoria ad esso visibile indicato come memoria centrale. Nel caso 1, quindi, la memoria centrale coincide con la RAM; quando invece è sufficiente che solo parte dei dati e delle istruzioni siano in RAM, la memoria centrale non coincide interamente con la RAM, ma il suo ruolo è rivestito dall'insieme di memoria RAM e memoria di massa e si parla in questo caso anche di MEMORIA VIRTUALE.
Alcuni dei concetti fondamentali riguardanti la gestione della memoria dovrebbero esserci già noti. Ricordiamo in particolare che, al momento dell'esecuzione di un programma, se viene richiesta la lettura o la scrittura di un dato o di una istruzione contenuti nella RAM, è necessario inviare a quest'ultima un indirizzo assoluto. Nei fatti, l'indirizzo fisico assoluto mandato verso la RAM può essere generato in fase di:
1) compilazione;
2) collegamento;
3) caricamento in memoria;
4) esecuzione.
L'indirizzo delle istruzioni e dei dati del processo (ovvero la sua posizione nella memoria centrale) possono essere conosciuti o determinati in una delle prime tre fasi, e in tal caso viene generato quello che si chiama codice assoluto del processo. Qualora gli indirizzi vengano invece generati in tutto o in parte in fase di esecuzione, nel codice del processo figureranno indirizzi di riferimento ad uno spazio logico, anziché fisico, di memoria.
Si intende con il nome di BINDING l'operazione di trasformazione dell'indirizzo (di dati e istruzioni) dalla forma logica alla forma fisica. Essa può essere effettuata in una qualunque delle quattro fasi succitate: ciò dipende dalla risposta alla domanda: in quale fase si può conoscere l'indirizzo esatto di istruzioni e dati? La situazione limite è quella in cui l'associazione indirizzo logico - indirizzo fisico sia possibile solo in fase di esecuzione e in tal caso il BINDING è eseguito dinamicamente. Si rifletta sulle conseguenze che questo comporta: se un programma (e quindi la sua area codice, la sua area dati etc.) risiede in memoria ad indirizzi assoluti, non è possibile modificare la sua posizione, ovvero far 'migrare' i codici da un segmento all'altro della memoria. Questo è invece possibile se si fa riferimento ad uno spazio logico. Se ad esempio la regola di binding utilizzata è quella che indicheremo qui di seguito, basterà modificare a run time la base [1] .
Il sistema più banale e conosciuto di binding (trasformazione da indirizzi logici a fisici) è quello della base e della costante di spiazzamento, illustrato nella figura 1.
|
|
figura 1
Per ricavare l'indirizzo fisico, ovvero quello di memoria, occorre sommare al contenuto del registro BASE (o REGISTRO DI RILOCAZIONE) quello del registro SPIAZZAMENTO (che rappresenta l'indirizzo logico). Questa procedura si chiama associazione dinamica degli indirizzi e può essere realizzata solo su di una macchina che abbia una speciale, apposita struttura HW; in particolare essa deve provvedere uno o più registri contenenti la o le basi (non è detto infatti che un programma faccia riferimento ad un unico spazio logico).
Immaginando ad esempio di avere in memoria, a valle del caricamento, un programma che presenti la situazione descritta in figura 2.
|
|
|
|
|
|
|
|
|
cod op | add |
|
Dati |
|
Stack |
|
|
|
|
|
Z |
|
figura 2
|
|
AI |
|
|
AD |
|
X |
AS |
figura 3
Vi sarà cioè uno spazio logico di istruzioni (che va dall'indirizzo logico 0 all'indirizzo 20000), uno spazio logico di dati (indirizzi da 0 a 10000) e un'area stack (indirizzi da 0 a z). Nel programma utente gli indirizzi di istruzioni e dati sono espressi sempre in forma logica, dato che questo semplifica non poco la programmazione. Quindi in questo caso abbiamo bisogno di almeno tre registri base. Nulla vieta che all'atto di caricare il programma in memoria il caricatore provveda a raccogliere i tre spazi in un solo spazio logico, come illustrato in figura 3. In questo modo il processore nell'andare a ricercare in memoria dati e istruzioni da eseguire può fare riferimento ad un unico spazio logico, delimitato dagli indirizzi 0 e X, nel quale trovano posto, nell'ordine, l'area istruzioni, quindi l'area dati e infine l'area stack. Di conseguenza saranno necessari solo un registro - base ed un registro destinato a contenere la costante di spiazzamento.
Per fare un esempio pratico, l'ormai vetusto processore UNIVAC 1100 era progettato in modo da 'vedere' due spazi logici: uno per le istruzioni e uno per i dati. L'appartenenza di un indirizzo logico all'uno o all'altro spazio era determinata in base al suo primo bit. Se il bit maggiore dell'indirizzo logico era zero, esso faceva riferimento allo spazio logico delle istruzioni; se era uno, allo spazio dei dati. Di conseguenza a seconda del valore del primo bit veniva selezionato uno fra due diversi registri base, a cui veniva poi sommato l'indirizzo logico.
In genere si presenta la necessità di gestire un certo numero di registri base (è questo il caso del processore INTEL, in cui i registri base sono quattro). Ogniqualvolta si verifica un cambio di contesto (si salta da un processo all'altro) il contenuto di tali registri viene generalmente ridefinito. Infatti questi registri di macchina contengono informazioni relative al processo attualmente in fase di running, e quando quest'ultimo viene rimpiazzato da un altro processo essi vanno reinizializzati. Affinché allora non si perda memoria di quella che era situazione della CPU al momento del cambio di contesto, è indispensabile che il contenuto dei registri macchina venga salvati da qualche parte, e come ormai dovremmo sapere, tale salvataggio viene fatto all'interno del descrittore del processo sospeso.
Il BINDING è uno dei due compiti fondamentali di cui deve occuparsi il GESTORE DELLA MEMORIA. L'altro è costituito dall'evitare che i processi in memoria si sovrappongano l'uno all'altro.
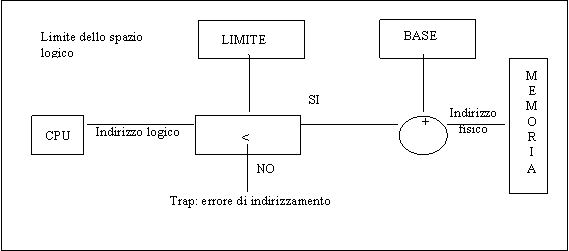
figura 4
Il meccanismo classico di prevenzione di questo problema consiste nell'effettuare, prima di utilizzare l'indirizzo logico, una comparazione tra l'indirizzo logico ed un limite logico precedentemente stabilito (cfr. figura 4) (si tratta naturalmente di un limite superiore, essendo sempre zero il limite inferiore per un indirizzo logico). Se l'indirizzo logico risulta maggiore, si verifica un trap. Ad ogni cambiamento di contesto vengono definiti, fra i vari registri di macchina, anche i registri limiti di memoria relativi al nuovo processo running.
L'OVERLAY
Ci sarà utile ora esaminare una tecnica di gestione della memoria che veniva usata molti anni fa nei piccoli sistemi di elaborazione. All'epoca uno dei problemi più ostici era costituito dall'impossibilità di disporre di banchi di memoria indirizzabile sufficientemente grandi, anche laddove si doveva far girare un solo programma alla volta. Questo problema era aggirato mediante un trasferimento di informazioni fra memoria di massa e memoria centrale, come del resto avviene oggi nei sistemi a memoria virtuale. Ma la differenza in termini pratici è enorme. In un moderno sistema a memoria virtuale, infatti, di questo 'travaso' si occupa esclusivamente il SO, in modo da rendere la cosa assolutamente trasparente all'utente.
In quel caso accadeva l'esatto contrario: il SO era in grado di 'vedere' la sola memoria centrale del sistema e del trasferimento informazioni fra memoria di massa e memoria centrale doveva farsi carico l'utente, mediante una tecnica nota come OVERLAY. Essa si basava sulla possibilità di conservare in memoria solo le istruzioni e i dati utilizzati con maggiore frequenza. Quando sono necessarie altre istruzioni, queste vengono caricate nello spazio che precedentemente era occupato dalle istruzioni che ora non vengono più utilizzate.
Un esempio può essere dato dall'assembler a due passi. Durante il passo 1, l'assembler costruisce una tabella di simboli; durante il passo 2, genera il codice in linguaggio macchina. Supponiamo che le dimensioni delle componenti del processo siano queste:
- Passo 1 : 70 K ;
- Passo 2 : 80 K ;
- Tabella dei simboli : 20 K ;
- Routine comuni : 30 K.
Quindi per caricare in memoria l'intero programma servono 200 K di memoria. Supponiamo che ne siamo disponibili solo 150. In tal caso, si può notare che non è necessario che il passo 1 e il passo 2 si trovino contemporaneamente in memoria. Si possono allora definire due overlay: l'overlay A costituito dalla tabella dei simboli, dalle routine comuni e dal passo 1; l'overlay B costituito dalla tabella dei simboli, dalle routine comuni e dal passo 2. Deve essere presente in entrambi un gestore (o driver) dell'overlay, che poniamo occupi 10 K, indispensabile per passare da un overlay all'altro.
Si inizia il processo con in memoria l'overlay A. Terminato il passo 1, subentra il driver dell'overlay che sovrascrive in memoria l'overlay B (prelevandolo dal disco) all'overlay A e trasferisce il controllo al passo 2. Si noti come dunque il programma assembler a due passi possa essere eseguito nei 150 K. Il caricamento sarà più rapido, perché coinvolge meno dati; l'esecuzione invece, naturalmente, risulterà rallentata dalla necessità di effettuare l'operazione di I/O delegata a sovrascrivere il codice dell'overlay B a quello di A.
|
|
|
|
SIMBOL TABLE |
20k |
|
|
|
|
|
|
ROUTINE COMUNI |
30k |
|
|
|
|
PASSO 1 |
|
GESTIONE OVERLAY |
10k |
PASSO 2 |
80k |
|
|
|
|
|
|
|
|
LO SWAPPING
Questa tecnica è in effetti stata già incontrata quando abbiamo parlato dello schedulatore a medio termine. Il suo scopo è quello di lavorare con un quantitativo di processi attivi maggiore di quello che potrebbe essere consentito con le tradizionali tecniche di gestione della memoria..
Se il kernel ha un certo numero di processi aperti, ma non c'è abbastanza spazio per contenerli tutti nella memoria centrale, alcuni di essi vengono spostati nella memoria di massa (deve trattarsi di un'unita di memorizzazione con una buona velocità di trasferimento e una sufficiente capienza, come un disco fisso). Un processo può essere ad esempio 'swappato' nella memoria di massa quando si mette in attesa del completamento di un'operazione di I/O (con le dovute precauzioni, come si dirà fra poco): questa è l'operazione di swap out. I processi ready dovrebbero trovarsi tutti in memoria centrale, per velocizzare il più possibile la transizione degli stati ready - running. Se ciò non è possibile, si deve cercare comunque di fare in modo che lo swap in di un processo sia effettuato prima che lo schedulatore a breve termine lo faccia divenire running. Il processo di volta in volta scelto dallo schedulatore della CPU dovrebbe cioè essere sempre presente in memoria centrale. Se deve essere eseguito un processo che si trova residente nella memoria di massa occorre effettuarne lo swap in e contemporaneamente fare lo swap out di uno dei processi attualmente presenti in memoria, il che costituisce un'evidente inefficienza. In altri termini, se ben gestito, lo swapping consente, a parità di memoria disponibile, un livello di multiprogrammazione più alto; contrariamente può finire con l'aumentare l'overhead del sistema.
La tecnica di swapping trova riscontro un po' in tutte le tecniche di gestione della memoria: memoria a partizioni variabili, memoria paginata, memoria virtuale etc.. Ne esistono inoltre varie interpretazioni, a seconda della tecnica di schedulazione dei processi adottata dal SO. Se vige una disciplina round-robin, ad esempio, trascorso un quanto di tempo il gestore della memoria esegue lo swap out del processo appena terminato e lo swap in di un altro processo nello spazio di memoria centrale che si è così liberato. Nel frattempo, lo schedulatore a breve termine avrà dato la parola ad un altro processo ready, ed è auspicabile che si sia trattato di un processo residente nella memoria centrale. In memoria, cioè, dovrebbero sempre esserci dei processi pronti per essere eseguiti. In presenza di un sistema a priorità lo swapping prende anche il nome di rolling: In tal caso, se giunge un processo a maggiore priorità occorre prerilasciare la memoria occupata dal processo attualmente in esecuzione, eseguendo su di esso uno swap (o roll) out, attendere la terminazione del nuovo arrivato e poi richiamare il processo 'swappato' e continuare con la sua esecuzione.
Si noti che in quest'ultima circostanza lo swap out viene effettuato su di un processo ready. Precedentemente abbiamo accennato allo swap out fatto per un processo che si trova sull'attesa di un'operazione di I/0 (processo wait). Questo però non può essere fatto sempre e comunque, perché potrebbe dar luogo a malfunzionamenti. In particolare, ciò non è possibile se la situazione è tale che l'I/O accede continuamente e in modo asincrono alla memoria utente per leggervi i dati di un processo che ha richiesto un servizio. Se quest'ultimo fosse swappato e se un altro processo occupasse il suo spazio di memoria, l'operazione di I/O potrebbe tentare di usare la memoria che ora appartiene ad una altro processo.
Un processo che è in attesa di un'operazione di I/O può essere swappato solo se le operazioni di ingresso uscita vengono fatte attraverso un'apposita area di memoria del SO, anziché direttamente nell'area di memoria del processo. Il trasferimento dati tra il buffer del SO e la memoria del processo potrà avvenire in un momento posteriore, dopo che il processo sarà stato sottoposto a swap in.
GESTIONE DELLA MEMORIA A PARTIZIONI
Nella memoria centrale sono presenti più processi contemporaneamente, e ogni processo occupa una propria partizione di memoria. Generalmente viene effettuata la seguente distinzione:
1) partizioni fisse: il numero delle possibili partizioni è costante (cioè è un numero ben preciso);
2) partizioni variabili: il numero delle partizioni dipende dalle esigenze dell'utente, e viene quindi determinato dinamicamente. In tal caso questo numero sarà legato alla quantità di processi che è necessario mantenere nello stesso tempo in memoria e dalle esigenze in termini di spazio di memoria di ciascun processo. L'effettiva occupazione di memoria cambierà nel tempo, con la conseguente necessità di gestire opportunamente lo spazio che si viene a liberare o che viene ad essere occupato.
Il sistema delle partizioni fisse si usa solo nei piccoli sistemi, e normalmente in questo caso il programma in memoria è sempre a indirizzi assoluti, anziché relativi; i suoi indirizzi vengono inizializzati al massimo in fase di caricamento. Ben più interessante è la questione della gestione della memoria a partizioni variabili, della quale ci occuperemo nel seguito.

0 K SISTEMA OPERATIVO
![]()
UTENTE
![]()
SPAZIO LIBERO
512 K
Facciamo almeno un cenno a quella che è la tecnica di gestione a partizioni più semplice possibile e immaginabile: allocazione con partizione singola. In questo modello, il SO risiede nella 'memoria bassa' ed un singolo processo utente è in esecuzione, all'interno della propria partizione, nella 'memoria alta', come risulta dalla figura precedente (in realtà non ha importanza l'ordine dei segmenti di memoria). Il problema più immediato che questa banale struttura comporta è la possibilità che si abbia una sovrapposizione dell'area di memoria occupata dal SO da parte della partizione utente, ma questo problema può essere agevolmente superato mediante uso opportuno di un registro base e di un registro limite di memoria, come detto in precedenza.
Proseguiamo il discorso sulla gestione della memoria, che abbiamo introdotto in occasione della scorsa lezione. In particolare, abbiamo introdotto la tecnica dell'OVERLAY che aveva lo scopo di consentire che programmi di grosse dimensioni potessero essere eseguiti in memorie di capacità ridotta.
Una strategia simile a questa consisteva nel conservare in memoria un unico programma ed uno speciale buffer destinato a contenere delle routine di errore, realizzate con lo scopo di mandare il programma in abort. Si trattava di programmi di tipo commerciale dei quali l'80% circa era costituito di routine d'errore. La probabilità di generare un errore dipendeva dalla poca esperienza dell'utente; non appena l'utente imparava a conoscere bene il programma, quest'ultimo 'si stabilizzava'. Le routine d'errore perdevano dunque la loro ragione di esistere, continuando però a occupare inopportunamente spazio in memoria. Oggi una tecnica come questa sarebbe considerata obsoleta.
Abbiamo visto infine la tecnica dello SWAPPING, usata per mantenere più processi in vita contemporaneamente all'interno del sistema, e abbiamo considerato un semplice schema di gestione della memoria: quello dell'allocazione con partizione singola.
Entriamo ora nel merito delle più importanti tecniche di gestione della memoria.
GESTIONE DELLA MEMORIA: PARTIZIONI VARIABILI MULTIPLE
In questa tecnica (ormai abbandonata; ad esempio dalla famiglia INTEL, che ora adotta la tecnica della paginazione) a ciascun processo viene associata una partizione, ovvero una 'fetta' di memoria a indirizzi consecutivi, la cui lunghezza è dimensionata in modo che vi possano essere contenuti il codice, lo stack e i dati del processo stesso. L'illustrazione seguente permette di comprendere come evolve la gestione di memoria usando questa tecnica.

|
400K |
|
2560K |
Inizialmente in memoria c'è la parte 'vivente' del SO (cioè quella che è necessario che rimanga sempre residente in memoria) mentre risultano liberi i restanti 2160K. Devono essere caricati i 5 processi della tabella di destra; di conseguenza, vengono allocate varie partizioni in modo dinamico. Il problema sorge nel momento in cui alcuni processi terminano liberando così il proprio spazio di memoria, o anche, qualora sia lecito, nel momento in cui alcuni processi già allocati richiedono una estensione della memoria ad esso assegnata. Nel primo caso si creano dei 'buchi' di memoria liberata; lo spazio libero non è più ad indirizzi consecutivi, ma la memoria risulta frammentariamente ripartita tra segmenti occupati e segmenti liberi. Naturalmente se due o più buchi di memoria sono adiacenti, è possibile collegarli per formare un unico buco più grande. Quando un nuovo processo deve essere allocato, occorre assegnargli uno fra i 'buchi di memoria' disponibili che sia idoneo a contenerlo. Vediamo come ci si comporta se sono disponibili uno o più buchi di memoria adatti. È necessario in tal caso individuare un criterio d'assegnazione; le strategia fra le quali è possibile scegliere sono tre: FIRST-FIT, BEST-FIT e WORST-FIT.
FIRST-FIT alloca il primo buco sufficientemente grande. La ricerca può cominciare dall'inizio dell'insieme di buchi, oppure dal punto in cui era terminata la ricerca precedente, e può essere fermata non appena viene individuato un buco libero di dimensioni sufficientemente grandi.
BEST-FIT alloca il più piccolo buco in grado di contenere il processo. La ricerca va effettuata su tutta la lista, a meno che questa sia ordinata per dimensione. Questa strategia produce le più piccole parti di buco inutilizzate.
WORST-FIT: alloca il buco più grande. Anche in questo caso è necessario esaminare tutta la lista, a meno che questa non sia ordinata per dimensione. Questa strategia produce le più grandi parti di buco inutilizzate, che possono essere più utili delle parti più piccole ottenute con la strategia best-fit.
Il primo criterio tende a far perdere meno tempo in quanto non sono effettuate ricerche. Il secondo tende a ridurre gli spazi vuoti, mentre l'ultimo tende a lasciare più spazio libero per altri eventuali processi. Non esiste un criterio ottimale per ciò che riguarda l'utilizzo di memoria, mentre si può affermare che firsi-fit è il più veloce. Tutte e tre le tecniche comunque presentano il problema della frammentazione esterna, ovvero della frantumazione dello spazio libero di memoria in piccole fette inutilizzabili. Può succedere cioè che non sia possibile allocare memoria ad un processo, dato che non c'è al momento un 'buco' abbastanza grande, nonostante il fatto che il totale della memoria libera ('somma' di tutti i buchi) sia sufficiente per le esigenze del processo in questione. È questo il motivo fondamentale per cui questa tecnica ha finito con il cedere il posto ad altre più idonee, in primis quella della paginazione.
Per risolvere la frammentazione esterna continuando a rimanere nel contesto delle partizioni multiple variabili si applica un intuitivo sistema di compattazione: lo spazio viene recuperato andando a ricompattare periodicamente la memoria, in pratica 'accorpando' lo spazio libero in un unico 'buco'. Questo si può fare però solo se il programma sia rilocabile, ovvero espresso mediante indirizzi relativi; in altre parole, è impossibile applicare la compattazione se l'allocazione del programma viene effettuata in fase di compilazione, assemblaggio o caricamento ed è quindi statica. Ad esempio nel sistema base + spiazzamento, la compattazione può essere realizzata facendo 'migrare' le partizioni occupate verso un'estremità della memoria e modificando il contenuto del registro di rilocazione (base) per i processi che sono stati spostati (esistono anche altre possibilità, sulle quali non ci soffermiamo). Tale swap non viene fatto direttamente all'interno della memoria, ma utilizzando un apposito canale, allo scopo di sollevare il processore da questo compito ed avere quindi un minore overhead.
Esiste poi una problematica di frammentazione interna, dovuta al fatto che un processo potrebbe andare ad occupare un buco che è di poco più grande rispetto al processo stesso, e lo spazio che rimane è troppo piccolo per essere gestito, in quanto la sua gestione (ovvero la registrazione della duplice informazione indirizzo di memoria - dimensione del buco, solitamente effettuata in un'apposita tabella) richiederebbe più spazio del buco stesso. Nella tecnica di gestione a partizioni multiple, il problema della frammentazione interna risulta trascurabile, mentre si fa sentire (talora pesantemente) quello della frammentazione esterna; nella tecnica della paginazione accade l'esatto contrario.
Un'alternativa alla compattazione consiste nel disporre di più registri base, in modo che uno stesso programma possa essere suddiviso in memoria in più parti, ad esempio allocando l'area programma, l'area stack e l'area dati in punti differenti della RAM (cioè ad indirizzi non consecutivi). In questo caso bisogna però fare uso anche di altri registri speciali, detti registri FENCE (= recinto, steccato) che servono a impedire la fuoriuscita degli indirizzi logici dalle aree assegnata al processo. Poiché occorre inibire l'invasione verso altre aree di memoria per ogni distinta sezione del processo, il numero dei registri fence deve aumentare con l'aumentare del numero dei registri di rilocazione.
Questa modifica fatta alla tecnica a partizioni variabili consente di introdurre il concetto di codice rientrante (ovvero di CODICE CONDIVISO) fra due processi. Ad esempio, consideriamo il caso di due utenti che lavorano su di un word processor scrivendo due lettere differenti. In pratica si tratta di due processi che lavorano sulla stessa area codice (il codice in LM del word processor) ma su aree stack e aree dati distinte (contenenti i testi delle due lettere). Ciò naturalmente è possibile solo se si hanno segmenti di memoria separati per istruzioni e dati.
GESTIONE DELLA MEMORIA: PAGINAZIONE
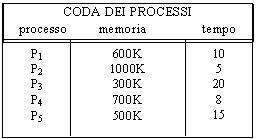
Questa tecnica consiste nel suddividere la memoria fisica in blocchi di dimensioni fisse, detti FRAME, e la memoria logica in blocchi di uguale dimensione chiamati appunto PAGINE. Quando un processo deve essere eseguito le sue pagine vengono caricate nei frame della memoria.
Ogni indirizzo generato dalla CPU è diviso in due parti: un numero di pagina (p), e un offset di pagina (d). Il primo serve da indice per la tabella delle pagine, che contiene l'indirizzo di ogni pagina nella memoria fisica. L'insieme di questo indirizzo e dell'offset di pagina permette di definire l'indirizzo dell'informazione desiderata nella memoria fisica, mediante il supporto hardware che viene schematizzato nella figura precedente. L'offset di pagina rappresenta lo spostamento rispetto alla prima locazione del frame che corrisponde a quella particolare pagina.
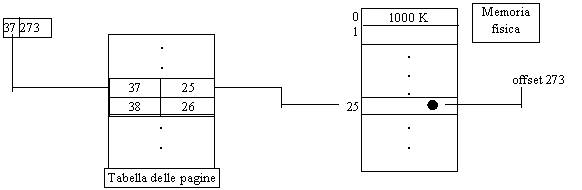
La dimensione di una pagina, uguale a quella di un frame, è definita dall'hardware (dato che essa coinvolge la memoria RAM) ed è in genere una potenza di 2. Il vantaggio di ciò è che in questo modo è immediato trarre a partire da un indirizzo logico l'insieme di un numero di pagina e di un offset. La parte di maggior peso dell'indirizzo logico rappresentano il numero di pagina, quella meno significativa rappresenta l'offset di pagina. Per facilitare le cose, facciamo un esempio con la base decimale: se l'indirizzo logico fosse 37273, e se ogni pagina logica fosse di 1000 K, allora l'indirizzo corrisponde alla pagina logica 37 e alla locazione di indice 273 (che è ad esempio una word) del corrispondente frame della memoria centrale (nel nostro esempio il frame di indirizzo 25).
Il fatto che K sia piccolo o grande comporta, in riferimento alla gestione e alla frammentazione delle pagine, vantaggi e svantaggi, come vedremo in seguito. Si noti come per la presenza della doppia coordinata frame - offset lo spazio fisico in questo modello sia bidimensionale, mentre lo spazio logico è lineare.
Dal punto di vista pratico, il mapping viene eseguito a tempo di esecuzione (dinamicamente) mediante un dispositivo hardware simile a quello sopra descritto che considera i bit di maggior peso dell'indirizzo logico, sfruttandoli come entry per la tabella delle pagine, e ricava la pagina fisica corrispondente. L'indirizzo cosi ricavato non va sommato all'offset, ma giustapposto a quest'ultimo; nel nostro caso, si effettua dapprima una semplice sostituzione fisica di bit tra 25 (indirizzo frame) e 37 (indirizzo pagina logica); il numero 25 costituisce la parte alta dell'indirizzo che viene mandato sul bus che va verso la memoria, la parte bassa di tale indirizzo è 273.
Non è quindi necessario scomodare l'ALU per ricavare gli indirizzi di memoria e si evitano le conseguenti perdite di tempo. Questo però vale solo nell'ipotesi, che abbiamo fatto implicitamente, che le pagine fisiche siano disgiunte; diverso è ciò che avviene ad esempio nel processore INTEL 8086 che contempla invece la possibilità di sovrapporre le pagine fisiche, e quindi ad esempio di accedere ad uno stesso indirizzo fisico da due diverse pagine. Questa peculiarità, che indubbiamente complica non poco il mapping della memoria, fu realizzata dalla INTEL in previsione dei microprocessori più completi e veloci che sarebbero stati costruiti negli anni avvenire (famiglia 80X86).
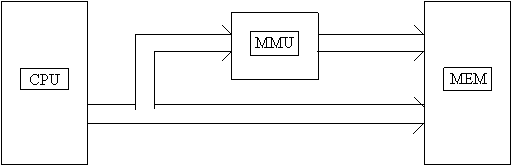
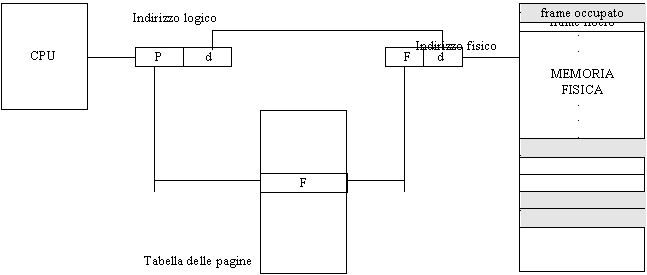
Il componente hardware incaricato di sostituire l'indice di pagina logica con l'indirizzo di pagina fisica può essere realizzato in vari modi. Nei sistemi meno recenti (anni '80) prendeva il nome di MMU ('Memory Management Unit'). Non è altro che una batteria di registri contenenti le corrispondenze fra pagine logiche e fisiche; naturalmente deve essere caricato con nuovi valori ad ogni context switch. I registri della batteria sono tanti quanto deve essere lunga la tabella delle pagine. Si osservi che L'MMU può essere collegato quale componente esterno a processori che non sono progettati internamente per gestire una memoria a pagine. Il discorso non è più fattibile se viene meno l'ipotesi di disgiunzione delle pagine fisiche: il problema va allora risolto all'interno della CPU e non esternamente ad essa.
Altra soluzione è quella in cui la tabella delle pagine è contenuta nella memoria stessa, e l'hardware è ridotto ad un solo registro speciale del processore (anziché un'intera batteria) che punta in memoria alla posizione di tale tabella. Per ottenere quindi l'indirizzo di un frame occorre sommare al contenuto di questo registro l'indirizzo della pagina richiesta (37 nell'esempio di cui sopra) e accedere in memoria all'indirizzo che ne consegue. Ogni processo possiede una propria tabella delle pagine, quindi al cambiare del processo running cambia dinamicamente il contenuto del registro, il quale punterà così ad un'altra tabella. Lo svantaggio evidente di questa alternativa sta nel suo richiedere degli accessi supplementari in memoria, la quale, come è noto, comporta tempi di accesso più lunghi rispetto ai registri hardware dedicati. D'altro canto si ha il vantaggio di eliminare ogni limite fisico per quanto riguarda il numero di pagine occupabili, eccetto ovviamente quello della dimensione fisica della memoria. Inoltre, i tempi di context switch diminuiscono sensibilmente.
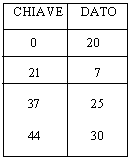
Una soluzione intermedia si ottiene con processori al cui interno non sono presenti né registri speciali né batterie di registri, ma che possiedono una MEMORIA ASSOCIATIVA: una memoria cioè nella quale l'accesso avviene per chiave e non per indirizzo.
Alla chiave 20 corrisponde la parola di
memoria 20
![]()
![]()
Quando ai registri associativi si presenta un elemento, esso viene confrontato contemporaneamente con tutte le chiavi. Evidentemente nella colonna 'chiave' figureranno le pagine logiche e nella colonna 'dato' quelle fisiche. La ricerca è estremamente veloce, ma il costo di realizzazione di un simile componente è elevato. Tuttavia la memoria associativa può essere utilizzata per contenere non l'intera tabella delle pagine, ma solo una sua porzione. Se si è 'fortunati' la chiave richiesta sarà presente in uno dei registri associativi e verrà immediatamente restituito l'indirizzo del corrispondente frame. In caso contrario non resta che rivolgersi alla tabella completa, che sarà registrata nella memoria centrale del sistema.
Il massimo della velocità media si ottiene costruendo un dispositivo hardware che prevede sia la memoria associativa sia il registro speciale che punta alla tabella completa delle pagine in memoria; l'accesso viene eseguito in parallelo: da un lato inviamo il numero 37 come chiave per la memoria associativa, dall'altro lato lo sommiamo all'indirizzo contenuto nel registro speciale per accedere alla giusta riga della tabella delle pagine residente in memoria. Si percorrono cioè entrambe le strade, quella veloce ma incerta della memoria associativa e quella sicura ma lenta della memoria RAM. Se la strada veloce ha successo, mandiamo un segnale di abort alla memoria RAM; in caso contrario lasciamo che l'operazione di accesso alla RAM prosegua, permettendoci di ottenere a tempo debito l'indirizzo della pagina fisica.
Posto t = tempo di accesso in memoria e = tempo di accesso alla memoria associativa (si può porre ad esempio t), con questo marchingegno otteniamo un tempo medio di accesso che è (t + nella migliore delle ipotesi (l'indice di pagina fisica si trova nella memoria associativa, per cui occorre poi un solo accesso alla memoria centrale) e 2t nella peggiore (l'indice presentato si trova nella sola tabella delle pagine; per cui occorrono in totale due accessi alla memoria, uno per ricavare l'indirizzo del frame, l'altro per accedere alla locazione desiderata). Il tempo di accesso medio risulta essere:
(t + p +2t * (1-p)
Dove p è la probabilità di avere successo con la memoria associativa. Dunque, il nocciolo della questione sta nel valore assunto da p. Se p è molto prossimo a 1 il tempo di accesso è dato da quello del caso migliore, t + . Nella realtà si verifica che per la quasi totalità dei programmi risulta essere p ~ 0,8 ÷ 0,9, per cui il tempo di accesso T normalizzato su t vale all'incirca:
T ~ (t + 0,1 * t) * 0,9 + 2t * 0,1= 1,19t T T / t ~ 1,19
Una probabilità p così alta di può realizzare nella maggior parte dei casi tenendo nella memoria associativa le pagine utilizzate più di recente. In tal caso il tempo di accesso medio risulta essere di poco superiore a t + e in particolare uguale all'incirca a t + 0,2 * t.
La protezione della memoria è garantita dalla stessa logica del metodo utilizzato. Non è possibile che si verifichi un'invasione verso altre pagine, poiché avendo imposto che le dimensioni di pagina logica e fisica siano uguali non c'è modo di raggiungere indebite locazioni di memoria con l'insieme degli indirizzi frame e offset. L'unico registro fence di protezione occorrente è quello che impedisce all'indice di pagina logica di essere tanto grande da fuoriuscire dalla tabella delle pagine residente in memoria.
In più, questa tecnica non presenta alcun problema di frammentazione esterna ma può denunciare una forte situazione di frammentazione interna, in quanto mediamente l'ultima pagina di ogni processo è occupata solo per metà spazio. Si rifletta allora sul ruolo che riveste la dimensione K di una singola pagina: se K è piccolo diminuisce il tasso di frammentazione interna, ma la gestione diviene più onerosa, poiché aumenta il totale delle pagine da gestire.
Nella ultima lezione abbiamo visto la tecnica della paginazione, un'evoluzione della tecnica di gestione a partizione variabili, che presenta come proprietà fondamentale la non consecutività della spazio fisico (ovvero degli indirizzi fisici), mentre lo spazio logico che su di esso viene mappato continua ad essere ad indirizzi logici consecutivi. Lo spazio fisico viene ad essere costituito da blocchi o frame non necessariamente contigui in memoria, ma che possono essere dislocati a macchia di leopardo. Il meccanismo di mapping della memoria dello spazio logico su quello fisico funziona particolarmente bene nell'ipotesi che la lunghezza delle pagine sia una potenza di 2, e nell'ipotesi che non vi sia sovrapposizione di pagine fisiche, poiché in tale caso per effettuare il mapping non occorre nessuna elaborazione, se non una semplice sostituzione di parte dell'indirizzo logico con i corrispondenti bit esprimenti la pagina fisica.
Elemento fondamentale della paginazione è la tabella delle pagine, che fissa la corrispondenza pagina logica - frame. Un modo di implementarla è quello di conservare nella memoria centrale una tabella delle pagine per ogni processo, e di farla puntare da un apposito indirizzo memorizzato in uno dei campi del suo descrittore. Quando un processo diviene running, ovvero al verificarsi di un cambio di contesto, si copia il valore di quel puntatore dal descrittore di processi in un registro speciale. Tale operazione può essere fatta all'interno della CPU. In alternativa si potrebbe disporre di una batteria di registri speciali (MMU) in cui memorizzare la tabella [3]. La gestione migliore si realizza con l'insieme di una memoria associativa che contiene parte di quella tabella, e in parallelo un registro speciale che punta alla tabella delle pagine qualora la memoria associativa dia esito negativo. Si è trovato che mediamente sono sufficienti 16 registri associativi per avere una probabilità dell'80% di trovare il riferimento cercato. Tenendo la tabella in memoria si elude la limitazione costituita dal massimo numero di pagine che è obbligatorio imporre affidandosi al sistema della batteria di registri. D'altra parte, usando contemporaneamente una memoria a struttura associativa si riesce ad ottenere un tempo di accesso relativo abbastanza buono.
A queste informazioni, che dovrebbero essere già conosciute, aggiungiamo che il SO deve poter utilizzare un'altra struttura dati, denominata tabella dei frame, dimensionata questa volta non sul numero di pagine logiche ma sul numero di frame, che indica per ogni frame se è libero o in caso negativo a quale processo (o a quali processi) è allocato.
Vediamo ora di riassumere i vantaggi della tecnica della paginazione.
1) Qualora il codice di un processo sia separato dai dati, esso può essere condiviso con altri processi. Ciò, lo ripetiamo, è possibile solo se non ci sono pagine che contengono in parte codice e in parte dati. Invero, la tendenza ad accodare i dati al codice (o viceversa) in uno stesso frame è normalmente favorita, perché ha come effetto positivo quello di minimizzare la frammentazione interna. Se infatti con la paginazione mediamente mezza pagina per ogni processo risulta non utilizzata, separando codice e dati si perdono in media due mezze pagine e quindi una pagina intera. Da notare inoltre che il codice fra due processi può essere condiviso solo se è non rientrante, cioè se nessuna istruzione è in grado di modificarne un'altra, che essa vede come se fosse un dato.
2) La paginazione permette un efficace meccanismo di protezione. Non ci riferiamo al controllo della validità degli indirizzi, perché quello viene realizzato tramite il registro FENCE che evita di esorbitare dalla tabella delle pagine o, se si adottano una batteria di registri o una memoria associativa, tramite i bit di validità [4] ad esse collegati. Piuttosto, è possibile definire il genere di accesso consentito sulle pagine; ad esempio una pagina che contiene codice si può accedere solo in esecuzione (durante la fase FETCH dell'algoritmo fondamentale del processore), ad una pagina dati si può accedere solo in lettura (stavolta nella fase EXECUTE) o in scrittura (sempre durante la fase EXECUTE).
Il primo vantaggio menzionato comunque è presente anche nella tecnica delle partizioni variabili. Non così il secondo, che costituisce una peculiarità della paginazione.
GESTIONE DELLA MEMORIA: SEGMENTAZIONE
Nella tecnica della paginazione la memoria fisica viene suddivisa in pagine di uguale lunghezza. Nella SEGMENTAZIONE, queste pagine, più propriamente SEGMENTI, hanno una lunghezza che varia a seconda delle esigenze. Analogamente allo spazio fisico, anche lo spazio logico viene visto come suddiviso in segmenti; inoltre esso, diversamente da quanto accade nel caso della paginazione, lo spazio logico assume come il suo corrispondente fisico una struttura bidimensionale: l'indirizzo logico è costituito dalla coppia indirizzo del segmento - offset all'interno del segmento.
La segmentazione è normalmente supportata da quei compilatori che mettono in segmenti logici diversi le variabili globali, l'area stack, i dati e così via. La fase di mapping, che si occupa di sostituire all'indirizzo di segmento logico quello di segmento fisico, richiede necessariamente un'operazione di addizione invece di una semplice sostituzione come nel caso precedente.
Nel caso della paginazione il compilatore genera gli indirizzi di uno spazio logico lineare, ed è ignaro della suddivisione in pagina logica (ovvero fisica) e offset di pagina che si ingenera subito dopo. Da questo punta di vista quanto avviene nella segmentazione è essenzialmente diverso. Si noti la figura che segue.
TRAP :
errore di indirizzamento
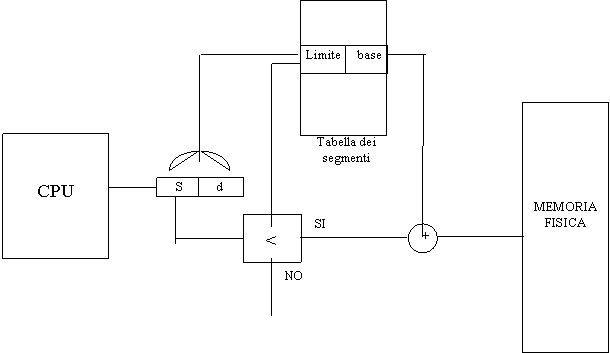
L'indirizzo logico è costituito esso stesso da una coppia: indice di segmento - displacement (anziché da un singolo indirizzo dal quale ricavare poi la coppia). La tabella che realizza la corrispondenza fra spazio fisico e logico prende qui il nome di TABELLA DEI SEGMENTI, ed è necessariamente più ampia della tabella delle pagine. Intanto, in tale tabella ad ogni segmento è associata una doppia informazione: l'indirizzo base del segmento nella memoria fisica e la lunghezza del segmento stesso. Durante la fase di EXECUTE viene rilevato un indirizzo logico (che può essere quello di un dato, ma anche di una istruzione: si pensi ad esempio alle istruzioni di salto), in cui l'indice di segmento serve ad accedere alla tabella dei segmenti dalla quale ricavare base e limite del corrispondente segmento fisico; il displacement viene confrontato con quest'ultimo allo scopo di impedire accessi illegali. Se il displacement è minore, viene sommato con la base per ottenere l'indirizzo fisico. L'hardware necessario per determinare l'indirizzo fisico include dunque un comparatore, un addizionatore ed un array di coppie (base, limite) ed è perciò più complicato di quello visto per la paginazione.
Nei fatti, si ricorre sempre al sistema di utilizzare l'insieme di una memoria associativa e di un registro speciale che punta alla tabella completa, residente in memoria. La memoria associativa contiene solo una parte di quella tabella. Se si tenta l'accesso ad un segmento il cui indice è assente all'interno della memoria associativa, di prosegue la ricerca in parallelo nella tabella dei segmenti. Ad ogni segmento inoltre si associa spesso una informazione supplementare: i diritti di accesso, che permettono di gestire i meccanismi di protezione relativi a quel processo. In questo modo un programma, anche di breve lunghezza, può essere disposto lungo più segmenti, ognuno dei quali con un proprio criterio di accesso: per esempio uno accessibile solo in lettura, uno anche in scrittura, eccetera. Si noti in proposito la figura seguente.

![]()
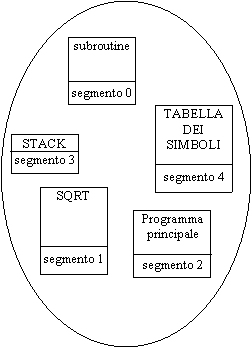
La tecnica della segmentazione permette uno sviluppo ulteriore del concetto di condivisione. Nell'ambito della paginazione è possibile dividere le pagine contenenti il codice da quelle contenenti i dati, e condividere l'intero codice tra due o più processi; con la tecnica dei segmenti invece è possibile condividere tra più processi soltanto parte del codice; poiché infatti i segmenti vengono definiti già a livello logico, si possono inserire opportunamente all'interno dei vari segmenti 'spezzoni' di codice, routine intere (come la SQRT dell'esempio) o gruppi di routine e condividere ciascun segmento fra quei processi che sono preposti ad utilizzarlo [5].
Affrontiamo ora il discorso della frammentazione. Con la tecnica della segmentazione sparisce la frammentazione interna, perché i segmenti possono essere definiti proprio della lunghezza necessaria. Permane invece il problema della frammentazione esterna. Dopo aver allocato i vari segmenti in memoria, potremmo ritrovarci con dei buchi di memoria così piccoli da non poter contenere alcun segmento. Questo problema però risulta meno grave di quanto lo fosse nel contesto delle partizioni variabili, perché è meno probabile che un buco di memoria sia di dimensioni così contenute da essere del tutto inutilizzabile, e quindi la necessità di ricompattare la memoria si presenta con una frequenza inferiore. Per eliminare del tutto la frammentazione esterna si usa una tecnica mista detta di SEGMENTAZIONE PAGINATA, nella quale ogni segmento è organizzato 'a pagine'.
GESTIONE DELLA MEMORIA: LA MEMORIA VIRTUALE
Questa tecnica può essere applicata sia nell'ambito di una memoria paginata, sia nell'ambito di una memoria segmentata. Noi esamineremo in particolare la tecnica della memoria virtuale applicata alla paginazione.
La memoria (segmentata o paginata che sia) non coincide più con la RAM ma risulta essere fisicamente allocata sulla memoria di massa; solo un sottoinsieme di questa memoria rimane nella RAM. Durante l'esecuzione di un processo, può accadere che lo stesso abbia bisogno di accedere ad una particolare pagina residente non nella RAM ma sul disco; in questo caso il SO deve prevedere un meccanismo automatico che effettui l'arresto del processo, l'ingresso della pagina mancante in memoria e la ripresa del processo, il tutto in maniera completamente trasparente rispetto all'utente.
Un'area più o meno vasta del disco viene dunque ad essere la vera e propria memoria del sistema. Tale zona è concettualmente del tutto distinta dal File System, sebbene alcuni moderni SO la includano al suo interno. In fase di caricamento di un generico processo, esso viene caricato in questa area del disco. Naturalmente però perché il programma possa essere eseguito è indispensabile che le sue istruzioni siano caricate sempre e comunque dalla memoria RAM (ci riferiamo alla fase FETCH); è questo il motivo fondamentale per cui un sottoinsieme della memoria deve trovarsi sempre in RAM. In teoria, sarebbe sufficiente che nella memoria RAM fosse presente la sola istruzione corrente (che cambia di volta in volta) e i dati su cui essa opera. Supponendo di usare la tecnica della paginazione, possiamo più ragionevolmente affermare che tutte le pagine risiedono sul disco, fuorché un sottoinsieme minimo che si trova in RAM; ogni volta che occorre, una intera pagina viene spostata dal disco alla memoria e viceversa.
Anche in questo caso avremo uno spazio logico di indirizzi, ed uno fisico. All'atto della generazione (mapping) dell'indirizzo fisico, può accadere che la pagina logica riferita dall'istruzione su cui stiamo lavorando sia inesistente. In questo caso il meccanismo di traduzione fallisce. Il processo viene allora sospeso e parte il meccanismo di sostituzione, che porta all'interno della memoria la pagina opportuna.
Al solito, l'indirizzo logico può essere quello di un dato oppure di una istruzione, come nell'esempio dell'istruzione di salto (ad un'altra istruzione) jump 1000. Consideriamo quest'ultimo caso. Si può pensare di effettuare il mapping soltanto all'atto dell'accesso in memoria (FETCH riferita all'istruzione memorizzata nell'indirizzo 1000). Nel PC viene ad essere caricato l'indirizzo logico 1000 (si carica dunque nel PC un indirizzo logico, anziché fisico). In questo caso la trap che segnala l'impossibilità di trovare la pagina richiesta viene innescata quindi in fase di FETCH. Se invece la corrispondenza indirizzo logico - fisico viene fatto prima di caricare il PC, l'eventuale trap sarà innescata preventivamente in fase di EXECUTE (EXECUTE riferita all'istruzione jump 1000).

500 jump 1000 1000: nop
TRAP : indirizzo inesistente
FETCH
FETCH
OPERAND ASSEMBLY OPERAND ASSEMBLY
TRAP : indirizzo inesistente
EXECUTE
EXECUTE
Notiamo che in questo caso la trap (detta di page fault) non provoca un abort del processo, bensì il travaso di una pagina dalla memoria di massa alla RAM o viceversa. Naturalmente è possibile che questo travaso, chiamiamolo (per pura comodità) Swap in, comporti preventivamente un trasferimento inverso, ovvero uno Swap out da RAM a disco, perché potrebbe non esserci memoria RAM a sufficienza per effettuare il solo Swap in. Il trasferimento che abbiamo denominato Swap out può essere fatto subito prima dello Swap in o in un altro precedente momento. Alcune macchina lavorano 'a pagine libere', altre 'a pagine piene'. Il secondo sistema prevede che una frame passi dalla RAM al disco ogni volta che le esigenze del programma richiedano che un'altra pagina effettui il trasferimento opposto. Si parla allora di lazy swapping (swapping 'pigro') o di paginazione su richiesta. Nel primo caso, invece, c'è sempre una altissima probabilità di trovare dello spazio libero, perché il sistema opera lo Swap out non all'atto dello Swap in ma periodicamente. Ad esempio, UNIX costruisce un 'serbatoio di pagine libere' mediante un'interruzione periodica.
Indipendentemente dal criterio adottato, saranno necessari degli opportuni algoritmi per selezionare le pagine da trasferire su disco. Da notare che lo swap out delle pagine fisiche può anche essere evitato: ci si può limitare in certi casi a sovrascrivere un frame giù occupato da un altro processo grazie al criterio dell'avvenuta modifica. Ad ogni frame si associa un bit di modifica che, inizializzato a zero, viene posto a 1 nel momento in cui si scrive nella pagina una sia pur minima informazione. Se il bit di modifica di un frame è zero, vuol dire che quella pagina non è stata mai modificata; essa è identica alla copia che risiede sul disco, e pertanto è inutile effettuare lo swap out.
Vediamo ora come avviene la traduzione degli indirizzi. Il procedimento è simile a quello della paginazione: occorre una tabella delle pagine. Di nuovo, una parte di quest'ultima si trova in memoria associativa. L'indirizzo di pagina fisica viene ricercato nella memoria associativa e parallelamente il registro speciale effettua la sua ricerca nella tabella completa residente in memoria, come indicato in precedenza. La tabella presenta però una struttura leggermente diversa. In particolare, un apposito bit di validità specifica se la corrispondente pagina logica è 'valida' o meno. Che una pagina logica sia considerata non valida significa che ad essa non corrisponde alcuna pagina fisica (cfr. fig. pagina seguente). Se il bit di validità non è 'okay' si genera una trap di page fault; interviene il kernel che effettua il demand paging, ovvero il travaso dalla memoria di massa della pagina richiesta [6]. Si potrebbe scegliere di memorizzare l'indirizzo della pagina su disco nella stessa tabella delle pagine.
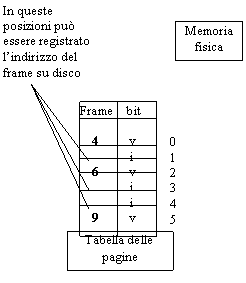
Ovviamente, può ancora presentarsi il caso che l'indirizzo logico sia del tutto illegale, nel senso che ad esso corrisponde una locazione di memoria che è al di fuori della tabella delle pagine. (In altre parole, a quell'indirizzo logico non corrisponde alcuna pagina fisica). Di questa situazione si occupa il solito registro di controllo fence, che fissa il limite della tabella delle pagine. Si può quindi generare una trap di indirizzo scorretto (anziché di page fault), con conseguente abort del processo, nel caso in cui si tenti di accedere ad una pagina di indirizzo logico maggiore del consentito.
Il supporto hardware di un sistema a memoria virtuale deve realizzare nel modo più semplice ed efficiente possibile tutte questi meccanismi.
Un'ultima osservazione, prima di chiudere la lezione. Abbiamo detto che il meccanismo di sostituzione di una pagina residente in memoria con una del disco parte per effetto del fallimento di un'operazione di traduzione indirizzi. Il programma deve essere temporaneamente sospeso, per ripartire (a sostituzione avvenuta) dall'istruzione che ha provocato quella sospensione. Si noti per inciso che se l'interruzione si è verificata in fase di OPERAND ASSEMBLY, in occasione della successiva ripartenza occorre ripetere anche il precedente prelievo dell'istruzione (FETCH). Questo genera dei comprensibili problemi per quelle particolari istruzioni che modificano molte variabili in memoria. Il Silberschatz-Galvin propone (pag. 288) l'esempio dell'istruzione macchina MVC che consente di spostare fino a 256 byte per volta da un punto all'altro della memoria. Potrebbe darsi che uno dei blocchi di origine o destinazione fuoriesca dal confine di una pagina, generando una page fault e costringendo a ricominciare daccapo il trasferimento. Inoltre, MVC consente anche di sovrapporre i due blocchi, e se effettivamente si verifica una sovrapposizione del blocco destinazione sul blocco origine evidentemente non ci si può limitare a riavviare l'istruzione. Problemi come questo devono essere prevenuti in fase di progetto del processore. Ad esempio, si possono utilizzare dei registri temporanei di memoria per conservare i valori delle locazioni sovrascritte. In caso di page fault e subito prima che si verifichi la corrispondente trap, tutti i vecchi valori vengono risistemati nel blocco origine.
continuo memoria virtuale
Abbiamo detto che per implementare la memoria virtuale c'è bisogno di un meccanismo di basso livello (hardware essenzialmente) che serve a controllare, nel momento in cui bisogna effettuare il mapping dell'indirizzo virtuale sull'indirizzo reale, se questo mapping è realizzabile o meno. Ovviamente il mapping sarà realizzabile se all'indirizzo logico specificato corrisponde un indirizzo della memoria fisica; siccome abbiamo detto che l'organizzazione sottostante è una organizzazione a pagine, ciò significa dire che la pagina fisica cercata, oltre a stare su memoria di massa (cioè su un blocco di disco), risulta essere stata anche travasata nella memoria centrale.
L'hardware di cui sopra funziona in questo modo:
Abbiamo una memoria associativa in cui viene registrata una parte della tabella delle pagine; un riferimento viene ricercato in questa memoria, se esso viene trovato, si controlla un bit di validità che ci dice se la pagina cercata è nella memoria centrale o meno. Qualora invece nella memoria associativa non fosse presente il riferimento cercato, esso viene ricercato nella tabella delle pagine. In quest'ultima tabella ci sarà sicuramente il rigo corrispondente al riferimento (in quanto essa contiene tutti i possibili riferimenti del processo), di tale rigo viene controllato il bit di validità che ci dice ancora una volta se la pagina cercata è presente o meno nella memoria fisica.
In entrambi i casi (memoria associativa o no) se il bit di validità ci dice che la pagina ricercata non è in memoria centrale si genera un page fault ; tale evento ci informa che è necessario caricare la pagina riferita. A questo punto se abbiamo una pagina libera nella memoria centrale, la nuova pagina potrà andare in questo punto, altrimenti bisognerà sostituire qualche altra pagina che era in memoria ; ciò è realizzato tramite un "algoritmo di sostituzione".
Tale algoritmo deve essere ovviamente ottimizzante e ciò significa dire che esso deve essere in grado di individuare nel modo più opportuno la pagina vittima.
Cominciamo con il dire che un algoritmo di sostituzione può essere :
locle (asl): la pagina vittima ,quella da sostituire, viene ricercata unicamente tra le pagine del processo che ha causato il page fault.
globale (asg) : ricerca la pagina vittima tra la totalità delle pagine.
Esistono inoltre due strategie in cui si decide di lavorare rispettivamente a:
pagine piene : si va avanti fino a quanto la memoria non è piena, ponendosi il problema della sostituzione di una pagina solo quando si è verificato un page fault e non c'è più alcun buco libero; in tal caso può essere utilizzato sia un ASL che un ASG.
pagine libere : tramite uno svuotamento periodico delle pagine faccio in modo che al momento in cui si verifica un page fault ci sia sempre qualche pagina disponibile. In tal caso si capisce che l'algoritmo di sostituzione entra in gioco al momento dello svuotamento periodico della memoria in cui non esiste il concetto dei località e quindi tale algoritmo non può essere che un ASG. (UNIX usa questa tecnica, cioè è presente un timer che periodicamente fa partire un DEMON che crea un pool di pagine libere che viene consumato fino al prossimo timer).
Esaminiamo adesso alcuni algoritmi di sostituzione.
algoritmo fifo
Abbiamo una informazione che ci dice da quanto tempo la pagina è stata portata in memoria centrale. Basandoci su tale informazione noi andremo a sostituire la pagina che è presente in memoria da più tempo.
Esempio :
Supponiamo che il processo abbia avuto (in qualche modo) a disposizione 3 pagine e che l'algoritmo di sostituzione sia un "algoritmo di sostituzione locale".
Viene considerata la seguente stringa dei riferimenti alle pagine (che dovrebbe rappresentare i riferimenti alle pagine logiche che vengono fuori eseguendo le istruzioni del processo) :
0 1 2 0 3 0 4 2 3 0 3 2 1 2 0 1 7 0 1
Alcune delle istanze della tabella delle pagine che si genereranno sono le seguenti :
7 0 1 2 0 3 0
![]()
![]()
![]()
![]()
![]()
![]()
Inizialmente si verificano tre page fault, che potremmo definire fisiologici (si parla in questo caso di paginazione pura) in corrispondenza dei primi tre riferimenti. Subito dopo viene riferita la pagina 2 che non essendo in memoria causa un page fault ; l'algoritmo FIFO sostituisce allora la pagina 7 che era stata la prima ad entrare in memoria. Successivamente c'è un riferimento a 0 che non causa page fault, e un riferimento a 3 che
causa la sostituzione della pagina 0 che è la più vecchia ecc.
Il risultato finale è che per questa stringa di riferimento, a prescindere dai 3 page fault iniziali (un'altra tecnica avrebbe potuto inizialmente prendere 3 pagine a caso e portarle dentro : caricamento a-priori), si sono verificati 12 page fault.
Il difetto di questo algoritmo che subito si nota è che esso non tiene conto del fatto che una pagina cariata da molto tempo potrebbe ancora servire; ad esempio sopra, al riferimento a 3 è stata sostituita la pagina 0 che sarebbe servita subito dopo.
L'algoritmo FIFO non è allora un algoritmo ottimale (e neanche molto efficiente).
algoritmo ottimale
Da quanto visto sopra si capisce che l'algoritmo di sostituzione ottimale, nel momento in cui si deve effettuare una sostituzione di una pagina, tende a buttare fuori la pagina che da quel momento in avanti non sarà referenziata per maggior tempo.
Che questo sia un algoritmo efficiente lo si può vedere riconsiderando la stringa dei riferimenti precedente, in tal caso infatti questo algoritmo causa appena 6 fault oltre ai 3 iniziali (cioè la metà dell'algoritmo FIFO).
(Vedi libro pag. 298)
Questo algoritmo è in realtà un algoritmo teorico in quanto è impossibile prevedere la stringa dei riferimenti di un processo (un po' come l'algoritmo SJF nello scheduling della CPU in cui dovevamo limitarci a fare una stima di ciò che poteva succedere) ; ci si limita quindi a cercare di approssimarlo tenendolo come riferimento : cioè un algoritmo sarà tanto migliore quanto più approssima l'algoritmo ottimale (è questa la sua importanza).
algoritmo lru (last recentely used)
Questo algoritmo fa lo stesso ragionamento dell'algoritmo ottimale, ma invece di guardare in avanti guarda all'indietro.
Viene sostituita non la pagina che è stata portata in memoria da più tempo (FIFO), bensì quella che non viene usata da più tempo. La filosofia è che se quella pagina mi è appena servita, probabilmente mi servirà ancora (località temporale).
Usando la stesa sequenza di riferimento (libro pagina 299) si vede che in questo caso vengono generati solo 9 fault oltre ai 3 iniziali ; quindi in questo esempio l'algoritmo risulta avere una efficienza che è intermedia tra quello ottimale e quello FIFO.
Tale algoritmo ha bisogno di un supporto hardware che permetta di associare a ciascuna pagina un informazione che consente di ordinare le pagine da quella non usata da più tempo a quella usata più recentemente.
Citiamo 4 possibili realizzazioni :
La CPU ha un counter che viene incrementato ad ogni accesso in memoria il cui valore viene copiato nella tabella delle pagine ; la pagina sostituita è quella con valore del counter + basso (questo algoritmo non piace al professore).
Il modo più semplice per realizzare un tale algoritmo (da un punto di vista logico e non reale) sarebbe quello di avere un campo nella tabella delle pagine in cui ogni volta che viene fatto un riferimento ad una determinata pagina viene scaricato il valore di un timer ; nel momento della sostituzione viene scelta come pagina vittima quella che ha il valore del timer più basso. Questo procedimento anche se lineare da un punto di vista logico risulterebbe abbastanza costoso da realizzare. Si possono fare, invece, dei ragionamenti che approssimano questo algoritmo e che rendono la sua realizzazione meno costosa.
C'è un hardware speciale che realizza una lista di delle pagine, ordinata in base all'accesso ; cioè ogni volta che faccio riferimento ad una pagina il riferimento a quella pagina viene messo in testa alla lista. Ne segue che la pagina vittima, è in ogni momento, quella in coda alla lista (anche questo sistema è molto costoso e in pratica quasi mai utilizzato).
Si può effettuare una discretizzazione del tempo in intervalli, registrando se in ognuno di questi intervalli io ho fatto almeno un accesso ; questa informazione mi deve essere fornita dall'hardware. Ad esempio un meccanismo attraverso il quale io posso realizzare ciò è il seguente. Nella tabella delle pagine io ho un ulteriore bit che è detto bit di riferimento, nel quale l'hardware segna un uno ogni volta che viene fatto un accesso (a prescindere da lettura o scrittura, non confondere con il bit di modifica che si setta solo in scrittura) alla corrispondente pagina. Inoltre ho un timer tarato ad un intervallo X che e l'intervallo di discretizzazione che ho scelto ed è quello di cui parlavamo sopra. Ho ancora una batteria di shift register, uno per ogni pagina della tabella delle pagine, il cui bit + significativo è proprio il bit di riferimento. Il numero di bit di cui questi shift register sono composti mi da il numero di periodi passati (ognuno di lunghezza X) di cui io voglio tenere conto. Il meccanismo funzione in questo modo : ogni volta che scatta il timer viene fatto lo shift di tutti gli shift register con bit entrante pari a 0. Nel momento in cui io devo sostituire una pagina vado a prendere quella che ha il numero binario + piccolo nel proprio shift register :
Direzione Shift Shift register Num. Intervalli
![]()

se ad esempio due pagine hanno questi numeri nei loro shift register :
viene sostituita la seconda perché avendo il numero binario più piccolo è stata referenziata
meno frequentemente di recente. Notiamo che questo modo di procedere non rispecchia in pieno l'algoritmo LRU perché nel nostro esempio avendo discretizzato il tempo le due pagine erano equivalenti ai fini di questo algoritmo (cioè non venivano usate dal medesimo tempo). Si fa qui cioè l'ipotesi aggiuntiva che la seconda pagina mi serva meno della prima perché è stata referenziata di meno negli ultimi periodi.
Si vede quindi che avendo a disposizione questo tipo di hardware, l'algoritmo non deve fare altro che trovare il minimo in una tabella.
Molti sistemi operativi utilizzano proprio questo sistema ma anziché considerare n intervalli di tempo, ne considerano solo 1. Questo vuol dire che l'hardware si riduce ai soli bit di riferimento. UNIX è fra questi ma applica un algoritmo un po' particolare, simile a questo, che viene detto "algoritmo della seconda chance".
algoritmo della seconda chance
Ribadiamo che affinché possa realizzare questo algoritmo, l'hardware mi deve mettere a disposizione i bit di riferimento delle pagine che vengono settati ogni volta che viene fatto un accesso in memoria e azzerati a ogni intervallo di tempo. Aggiungiamo che in questo caso specifico, i bit di riferimento sono organizzati come una coda circolare.
![]()
![]() Puntatore del daemon
Puntatore del daemon
![]()
Sottolineiamo inoltre che UNIX lavora secondo la strategia a pagine libere ; tale strategia è realizzata in questo modo : Le pagine libere sono viste da unix come un serbato che ha un livello massimo (prefissato) e un livello minimo al di sotto del quale non si deve scendere . Il serbatoio viene portato a massimo livello ; man mano che il sistema funziona il livello scende ; ad intervalli di tempo (scanditi da qualche clock) ben precisi interviene un demon che controlla se il serbatoio e sceso sotto il livello minimo e solo in questo caso lo riporta a livello massimo. Il livello minimo è ovviamente introdotto per ridurre il numero di volte in cui l'algoritmo entra in funzione, e quindi per evitare dei farlo funzionare per la liberazione di poche pagine (infatti in questo caso, il numero minimo di pagine da liberare è pari a max-min. Ricordiamo che l'I/O su disco è tanto più efficiente quanto più è consistente).
(Osserviamo che in realtà esistono due versioni di UNIX, una che fa come detto sopra e una che assegna al serbatoio delle pagine libere solo un livello massimo. In questa versione al clock, il demon comunque ripristina il livello massimo. Chiaramente, in questo caso non è assolutamente prevedibile il numero di pagine che il demon dovrà liberare, dipende da che cosa è successo in quell'ultimo intervallo di tempo, e quindi questo modo di fare meno efficiente del precedente).
Abbiamo detto questo per dire che l'algoritmo di cui dobbiamo parlare è quello realizzato dal demon, ed è, come abbiamo detto sopra quando abbiamo parlato di strategie di sostituzione e algoritmi di sostituzione, necessariamente un ASG.
Il demon ha un stato rappresentato dalla posizione del puntatore ai bit di riferimento. La posizione del puntatore, il quale ovviamente è manovrato unicamente dal demon, mi dice quale è la pagina candidata come prossima vittima. Quando il demon entra in funzione se trova un 1 nel bit di riferimento puntato significa che quella pagina è stata utilizzata nell'ultimo periodo ; allora da una "seconda possibilità" a quella pagina azzerando il suo bit di riferimento e avanzando il puntatore al bit di riferimento successivo. Ciò va avanti finché non viene trovato qualche bit di riferimento a zero ; in questo caso significa che dall'ultima volta che il demon è passato per quel bit mettendolo a zero la pagina non è stata utilizzata ; essa allora viene sostituita. Questo procedimento va avanti finché il livello delle pagine minime non è stato portato al massimo prestabilito.
Il nome dell'algoritmo deriva dal fatto che quando il demon trova un uno nel bit di riferimento di una determinata pagina esso lo azzera e non sostituisce la pagina dandogli una seconda possibilità di essere utilizzata. La durata di questa seconda possibilità non è determinabile, dipende dal tempo che il puntatore del demon impiega a ritornare su quel bit. Ciò dipende essenzialmente : dal intervallo di tempo scelto per il timer, dal numero di zeri che esso trova nei bit di riferimento e dal numero delle pagine che deve sostituire. (ricordiamo che tale numero di pagine in una versione di UNIX è pari minimo a MAX- MIN mentre nell'altra può essere qualsiasi). Un caso limite potrebbe essere quello in cui le pagine da sostituire sono numerose così come il numero di 1 per cui il puntatore fa un giro completo dell'array ritornando ad una pagina a cui aveva dato una seconda possibilità sostituendola; in questo caso la seconda possibilità di quella pagina sarebbe durata 0 unità di tempo.
algoritmo lfu (last frequentely used)
Questo algoritmo invece di sostituire la pagina che non viene utilizzata da maggior tempo, sostituisce quella che tiene la più bassa frequenza di uso. Per realizzare ciò basta avere un contatore che si incrementa ogni volta che si fa accesso ad una pagina (cioè si conta il numero degli accesi alla pagina). Il problema a cui si può andare incontro in questo modo e che le pagine che stanno dentro da più tempo hanno molto probabilmente un valore elevato del contatore rispetto alle pagine che sono state portate dentro da poco tempo. Per risolvere questo problema, si potrebbe pensare ad esempio di dimezzare il contatore periodicamente in modo da abbattere il valore delle pagine che stanno da molto tempo e che in passato hanno avuto grande uso e poi recentemente vengono utilizzate di meno. Tuttavia in questo caso no sarebbe più un LFU ma sarebbe una via di mezzo che tiene conto da quanto tempo non faccio acceso alla pagina.
Una volta individuate quali sono le pagine candidate per la sostituzione attraverso uno degli algoritmi sopra visti, un problema che si presenta è la scelta tra due pagine che secondo questi algoritmi sono entrambe candidate per essere sostituite.
Ma anche a prescindere da questo problema e da questi algoritmi, si potrebbe pensare di sostituire quelle pagine che nel periodo o nei periodi di osservazione non sono state utilizzate(sarebbero quelle pagine che tengono tutti 0 nei loro uno o più bit di riferimento) e, da quando sono state portate in memoria centrale, non sono mai state modificate. Chiaramente se una pagina è in memoria significa che almeno una volta è servita e quindi noi richiediamo che essa non sia stata mai modificata. Si capisce che per tenere nota della modifica delle pagine c'è bisogno di avere un bit di modifica che viene settato se la pagina viene modificata almeno una volta dal suo arrivo in memoria centrale. Chiaramente l'utilità di questo criterio sta nel fatto che se una pagina non è stata modificata, non c'è bisogno di aggiornarla sulla memoria di massa nel momento in cui essa deve uscire dalla memoria centrale. Terminate le pagine che non sono state ne modificate ne utilizzate si va a sostituire quelle che non sono state utilizzate ma modificate, poi quelle che sono state utilizzate ma non modificate e, se ancora non bastano, quelle utilizzate e modificate.
Chiaramente all'interno di ciascuna delle quattro classi ci si può limitare ad applicare un algoritmo FIFO.
Ci sono poi altri accorgimenti che si possono accompagnare a questi algoritmi per renderli più efficienti. Ad esempio UNIX tiene memoria dell'identità delle pagine (per identità si intende : chi sono , e ciò è normale ; ed inoltre che cosa contengono, e ciò è fatto per l'ottimizzazione) che stanno nel pool libero (cioè nell'insieme delle pagine che il demon ha buttato logicamente fuori dalla memoria), in modo tale che, se si verifica un fault perché c'è bisogno di una pagina che appartiene al pool libero, essa viene "resuscitata" senza essere caricata dalla memoria di massa.
![]()
Nel momento in cui un processo viene creato, e quindi viene caricato in memoria, ovviamente deve ricevere un certo numero di pagine. Un problema è il numero di pagine da assegnare ad un processo. Le possibili soluzioni sono le seguenti :
Si assegna al processo un numero minimo di pagine e poi ci si affida ai fault. Il numero minimo di pagine dipende in questo caso dal numero minimo di pagine che sono necessarie per eseguire un'istruzione in linguaggio macchina (ciò dipendente principalmente dal numero massimo di operandi che un'istruzione può avere).
Si da un numero di pagine costante uguale per tutti i processi.
Si assegna ad ogni processo un numero di pagine proporzionale alla sua dimensione.
Si assegna ad ogni processo un numero di pagine proporzionale alla sua priorità.
Si assegna ad ogni processo un numero di pagine proporzionale alla sua dimensione e alla sua priorità.
trashing
Un problema importante è quello del trashing.
Quando in un sistema ci sono molti page fault significa che il sistema sta lavorando male in quanto molte risorse del sistema sono spese per la sostituzione delle pagine.
Il fenomeno del trashing è appunto quel fenomeno che si verifica quando un processo o un insieme di processi richiedono più risorse per fare lo swap-in e swap-out delle pagine che per effettuare la normale computazione. Chiaramente un processo genera un gran numero di fault quando ha un numero di pagine assegnato che non è sufficiente alle sue esigenze. Ovviamente questo fenomeno può essere sia relativo :
ad un singolo processo del sistema
ad un insieme di processi del sistema
all'intero sistema.
Ad esempio, supponiamo di avere una strategia di gestione a "pagine piene", ed un algoritmo di sostituzione locale. In queste condizioni, sia dato un processo che sviluppa molti fault in quanto non ha a disposizione un numero sufficiente di pagine per portare avanti l'elaborazione. Siccome la sostituzione avviene nell'ambito delle stesse pagine del processo esso non uscirà ma da questa situazione ; ci troviamo in presenza di un fenomeno di trashing locale.
Se invece io ho un algoritmo di sostituzione globale, non è possibile avere un trashing locale in quanto nel momento in cui si verifica un page fault la pagina viene recuperata dal pool libero ( strategia a pagine libere) oppure è probabile che sia presa dalle pagine di qualche altro processo (strategia a pagine piene )mettendo così in difficoltà la paginazione di quest'ultimo che probabilmente "ruberà" le pagine di qualche altro. Si cadrà così in un circolo vizioso che porta ad un trashing del sistema di portata più ampia.
Un esempio in cui si può avere un trashing globale è in quelle macchine in cui il livello di multiprogrammazione è regolato in modo automatico in base alla percentuale di utilizzo della CPU : Supponiamo che il sistema stia portando avanti un certo numero di processi e ad un certo punto si accorga che la percentuale di utilizzo della CPU è bassa. Attribuendo questo fatto alla mal composizione dei processi (sproporzione tra CPU_BOUND
e I/O_BOUND), per risolvere il problema viene aumenta in modo automatico il grado di multiprogrammazione (ciò significa portare altri processi in memoria togliendo pagine a quelli già presenti). Se il poco utilizzo della CPU non era dovuto alla mal composizione dei processi ma ad un fenomeno di trashing l'aumento del grado di multiprogrammazione porterà molto probabilmente ad un trashing totale del sistema.
La cosa ideale da fare quando ci si accorge che un sistema è in trashing è prendere un certo numero di processi che sono attivi in memoria e farne uno swap-out complete, cioè eliminarli completamente dalla memoria centrale.
Per evitare il trashing la cosa ideale è quella di far si che ogni processo abbia a disposizione un numero adeguato di pagine. Tale numero di pagine varia per uno dato processo a secondo del punto del proprio flusso di controllo in cui si trova (ad esempi in un certo punto ci potrebbero essere molti salti a pagine differenti o un ciclo molto ampio, mentre, in un altro punto, ci potrebbe essere un ciclo molto stretto). Quindi per evitare il trashing si dovrebbe implementare una tecnica che assegni ad ogni processi un numero di pagine variabili durante la sua evoluzione ; ciò significa applicare il concetto del working-set. Il working-set di un processo è definito come l'insieme delle pagine che vengono utilizzate almeno una volta in un certo numero di riferimenti più recenti. Quindi abbiamo un certo numero di riferimenti fissato che mi determina quali pagine devono fare parte del working-set. Ciò vuol dire che se un processo, nella sua evoluzione comincia a lavorare su pagine differenti da quelle in cui lavorava precedentemente, accadrà sicuramente che qualcuna delle pagine del working-set ( qualche vecchia pagina) non venga mai referenziata e quindi la posso togliere ; viceversa se io mi accorgo che il processo, negli ultimi n riferimenti, ha referenziato tutte le pagine del suo working-set e la frequenza di paginazione è alta, significa che il processo ha bisogno di molte pagine e quindi gli devo ingrandire il working-set.
Ciò può essere realizzato avendo a disposizione sempre i bit di riferimento e un timer che fa partire una routine la quale periodicamente (cioè quando parte) prende il bit di riferimento lo mette nello shift register e lo azzera..la stessa cosa dell'algoritmo di sostituzione.
Una stima meno costosa del working-set ma più grossolana può essere fatta basandosi direttamente sul page fault : Conto il numero di page fault avuti nell'ultimo intervallo di tempo e se mi accorgo che sono in aumento e hanno superato un certo livello significa che le pagine che tiene il processo sono inadeguate e che quindi il suo working-set è insufficiente e quindi nei prossimi page fault devo sostituire le pagine prendendole da altri e non da lui. Viceversa se la sua frequenza di page fault si mantiene costante vuol dire che le sue pagine gli sono sufficienti . se la sua frequenza di paginazione tende ad abbassarsi vorrà dire che quando la frequenza di paginazione di altri si alza le sue pagine sono candidate ad essere sostituite. Ciò permette di ridistribuire le pagine tra i vari processi scegliendo sempre il bit di riferimento come discriminante del fatto che una pagina debba essere sostituita o meno.
interlock di i/o
Se, in un ASG io tolgo pagine ad un processo che in quel momento è bloccato (potrebbe essere un criterio) debbo stare attento se il processo bloccato sta facendo un operazione di I/O riguardante la pagina che io voglio sostituire ; in al caso infatti la pagina non può essere sostituita. Un modo è quello dimettere un bit di interlock di I/O alle pagine(così fa UNIX. UNIX ha anche un bit di interlock (che serve per l'algoritmo di seconda chance) quando un processo ha fatto un fault perché gli serviva una pagina ma non ha potuto ancora utilizzare quella pagina in quanto non ha ottenuto ancora la CPU ; in tal caso la pagina viene bloccata da questo bit).
prepaging
Se un processo viene portato totalmente fuori perché servivano le pagine da lui occupate, nel momento in cui viene riportato dentro dobbiamo dargli perlomeno il numero di pagine che teneva quando lo abbiamo buttato fuori in modo da ridargli il suo set di lavoro che aveva. Quindi anche questa è un informazione di cui va tenuto conto nel momento in cui viene gestito lo swap-in e lo swap-out.
problema della dimensione delle pagine
in questo problema non c'è niente di nuovo rispetto a quando visto per la memoria centrale : una pagina piccola significa minore frammentazione e riesco a soddisfare meglio la località del programma (in quanto tasselli più piccoli riescono a coprire meglio il flusso di controllo del programma, cioè posso sfruttare una definizione maggiore della memoria). D'altro canto un numero maggiore di pagine piccole sono più difficili da gestire e sono più costose nelle operazioni di I/O (in quanto, di solito le dimensioni dei blocchi di disco coincidono con quelle delle pagine e quindi piccoli blocchi mi costringono a perdere molto tempo per i seek e le latenze). Tutti questi difetti sono ovviamente i vantaggi delle pagine grandi a cui si aggiunge il fatto che con pagine grandi diminuisce la probabilità di page fault.
Le primitive per la gestione dei processi che ci rimangono da vedere sono quelle :
Per lo scambio di messaggi. Infatti, un altro mezzo che UNIX fornisce per la comunicazione tra processi è una struttura dati organizzata a coda di messaggi attraverso la quale i vari processi comunicano inserendo e prelevando i messaggi secondo la strategia tipica della coda.
Per la gestione dei semafori utili per la sincronizzazione dei processi.
Per la gestione delle PIPE (condotto) tra i processi, dove per PIPE si intende un canale attraverso cui i processi producono degli output per altri processi o prendono degli input provenienti da altri processi.
Cominciamo a occuparci delle primitive per la gestione dei semafori. Prima di iniziare ricordiamo che la volta scorsa abbiamo dette che per le quattro strategie che UNIX mette a disposizione per la IPC (inter process comunication), ci sono delle regole comuni.
La prima regola riguardava l'assegnazione di una risorsa, e diceva che la system call che richiedeva l'assegnazione della risorsa doveva sempre specificare una chiave. La chiave è un intero che il sistema utilizza per identificare in modo univoco una risorsa.
Vedemmo che c'erano sostanzialmente due modi per specificare una chiave, di cui il primo è praticamente il modo che viene utilizzato dai processi che hanno intenzione di mettere a disposizione la risorsa con tutti i propri figli :
chiave=ipc_private
Quando si parla invece di processi indipendenti, cioè che non appartengono allo stesso gruppo, un processo che vuole utilizzare una risorsa deve fornire la chiave della risorsa che gli interessa (tale chiave sarà stata definita dal creatore di quella risorsa) cioè deve specificare il numero intero corrispondente alla risorsa.

Siccome abbiamo parlato di gruppi di processi, puntualizziamone qualche aspetto.
UNIX permette di organizzare anche i processi in gruppi (così come fa con gli utenti). Ogni gruppo è identificato da un intero che per default è quello della shell che ad esso corrisponde ; cioè tutti i processi che sono stati creati a partire da una determinata shell fanno parte tutti del gruppo di quella shell.
Se io faccio un'operazione opportuna ho la possibilità di modificare il gruppo di appartenenza di un processo. L'utilità di cambiare il gruppo di appartenenza di un processo sta nel fatto che ogni volta che si chiude una shell cioè alla fine di ogni sessione di lavoro tutti i processi appartenenti a quella shell verrebbero automaticamente terminati ; se invece io voglio che un gruppo di processi continui a vivere anche dopo la chiusura della sessione di lavoro, basta che io gli cambi il gruppo di appartenenza scegliendone uno diverso da quello della shell attiva.
La seconda regola, riguardava la modalità di assegnamento di una risorsa. Questa modalità serve per far capire innanzitutto se la risorsa viene creata al momento e quindi siamo noi i creatori della risorsa dobbiamo specificare i permessi, oppure se non siamo i creatori cioè c'è stato qualcuno che in precedenza ha chiesto il rilascio della risorsa dobbiamo semplicemente specificare che la vogliamo utilizzare anche noi e quindi specifichiamo una modalità ipc_alloc. Quindi i permessi li specifica sempre il creatore dando la modalità ipc_creat /permessi chi invece utilizza quella risorsa deve specificare semplicemente ipc_alloc.
Le system call per la gestione dei semafori sono 3 :
semget : per la richiesta di un gruppo di semafori
semctl : per il controllo dei semafori (ad esempio rilascio, definizione del valore del semaforo, acquisizione dello stato del semaforo ecc.)
semop : permette di modificare lo stato del semaforo e quindi permette di risolvere i problemi di sincronizzazione realizzando le primitive di alto livello wait e signal.
La richiesta di un gruppo di semafori si ha con :
semget
Ricordiamo che UNIX gestisce i semafori in gruppi e quindi ogni volta devo specificare ne gruppo che sto richiedendo, quanti semafori ci sono (es. 1). Questo fatto porta come conseguenza che le operazioni che andiamo a fare su un semaforo devono poter essere eseguite contemporaneamente su ognuno dei semafori perché se questo non fosse possibile si avrebbe il blocco dell'operazione.
Nella semget vanno specificati :
chiave
numero semafori
modalita' di assegnamento
ipc_creat /permessi (per chi crea la risorsa)
ipc_alloc (senza permessi ; per chi la usa)
La semget restituirà :
un identificativo (>0) di tipo predefinito che identificherà il gruppo di semafori (tale identificativo servirà per referenziare il gruppo di semafori).
-1 in caso di errore :la risorsa non è stata rilasciata.
All'atto dell'allocazione di un gruppo di semafori, a ciascun semaforo del gruppo corrispondono alcune variabili :
semval (contiene il valore del semaforo : 0 o intero positivo ; ovviamente mi serve per conoscere il valore del semaforo)
semzcnt e semncnt (riportano qual è il numero di processi che è in attesa sulla coda del semaforo in attesa che semval diventi =0 o <> 0 rispettivamente per le due variabili)
La sintassi della semget è :
#include <sys/types.h>
#include <sys/ipc.h>
#include <sys/sem.h>
![]()
int semget (chiave, num_sem, modo)
Esempio di uso di semget :
key_t chiave ;
int id_sem ;
chiave = ftok ("/usr/des",'a') ;
id_sem = semget (chiave,2,ipc_creat
if (id_sem == -1)
I figli di questo processo erediteranno questa risorsa e la potranno quindi referenziare automaticamente.
Per modificare il "colore" di uno o più semafori di un gruppo si usa la:
semop
Nella semop vanno specificati :
identificativo del gruppo di semafori (esso è l'id_sem restituito dalla getsem)
indirizzo di uno o più semafori (cioè, devo indicare quale o quali semafori voglio modificare all'interno del gruppo indicando l'indirizzo di una o più strutture sembuf, dove sembuf è una struttura dati che viene associata ad ogni semaforo)
il numero di semafori sui quali si deve operare (quindi il numero di operazioni da eseguire).
La struttura associata ad un semaforo è il seguente record contenente i seguenti 3 campi :
short sem_num /*numero del semaforo nel gruppo. Cioè dobbiamo immaginare
la struttura dati "gruppo di semafori" come un array di record a 3 campi */
short sem_op /*valore da sommare al valore di partenza del semaforo per
modificarne il colore */
short sem_flag /* play di controllo che serve a stabilire il comportamento che il
sistema deve avere nei riguardi del semaforo in caso di anomalie. Ad esempio se esso vale sem_undo succede che se un processo ha messo un semaforo a rosso e termina senza prima di rimetterlo a verde, il sistema evita il blocco critico di eventuali altri processi (che erano in attesa sulla coda di quel semaforo), mettendo automaticamente il semaforo a verde. Più in generale il processo ripristina lo stato del semaforo alterato dal processo terminato.
In effetti non abbiamo le primitive di alto livello wait e signal, ma abbiamo il semaforo inizializzato ad un certo valore attraverso una opportuna primitiva. A tale semaforo è associata la struttura dati sopra vista per permetterci di specificare gli opportuni parametri che permettono la giusta modifica del semaforo giusto. Usando questa struttura noi possiamo realizzare tutte le primitive di sincronizzazione basate sull'utilizzo di semafori.
Ad esempio un wait su un semaforo viene fatta semplicemente :
T indicando in sem_num su quale semaforo del gruppo la si vuole fare
T indicando -1 in sem_op ; che decrementa di 1 il semaforo
T specificando opportunamente il flag
T eseguendo infine la primitiva semop
Quindi la struttura dati di cui sopra deve essere inizializzata prima di eseguire la semop a secondo della operazione che vogliamo eseguire sul semaforo.
La sintassi della semop è :
#include <sys/types.h>
#include <sys/ipc.h>
#include <sys/sem.h>
int semop (id_sem,vsops,ntops)
int id_sem vsops nsops ;
shrid sembuf *vsops[]; /*sembuf è un tipo predefinito che è un puntatore a un
array che si chiama vsops*/
Quindi la variabile vsops rappresenta l'indirizzo del vettore delle strutture dati associate ai semafori del gruppo. La variabile ntops rappresenta invece il numero di operazioni che si vuole eseguire.
La semop è un'operazione atomica, cioè non può essere interrotta e quindi tutte le operazioni indicate vengono eseguite senza possibilità di interruzione. Ciò comporta che se una delle operazioni che abbiamo indicato è illecita (ad esempio è stato specificato un semaforo che non c'è nel gruppo) ci sarà un errore e nessuna delle operazioni, anche se lecita, verrà portata a termine e il processo si sospenderà.
Una volta compilata la struttura sembuf si potrà eseguire l'operazione semop. Vediamo adesso i vari casi che si possono avere in funzione del valore specificato nella semop e il valore del semaforo semval :
T se sem_op=-1 e semval=1 semval=0 (equivale ad una wait : il processo in questione
avendo trovato il semaforo ad 1 passa mentre i
seguenti lo trovano a 0 e si bloccano)
T se sem_op=-1 ma semval=0 la system call è sospesa finché il semaforo è alzato da
qualche altro processo
T se sem_op=1 e semval=0 semval=1 (equivale ad una signal)
Esempio di uso di semop :
struct sembuf vsop[3] ;
id_sem = semget (chiave,3,ipc_creat 0666) ; /*chiede il rilascio di un gruppo di 3
semafori dando a tutti il diritto di leggere e scrivere sui semafori */
semctl (id_sem,0,0,setall,array) ; /*inizializza tutti i semafori del gruppo al valore
nullo (dopo analizzeremo meglio nel dettaglio la primitiva semctl)*/
/*decrementiamo il secondo semaforo del gruppo (con indice=1)*/
/*riempiamo la struttura d'appoggio */
vsops[1].sem_num=1 ;
vsops[1].sem_op=-1 ;
vsops[1].sem_flag=sem_undo ;
/*se avessi voluto operare su tutti e 3 semafori avrei dovuto fare le operazioni di
settaggio anche su vsops[0] evsops[2]*/
semop (id_sem,&vsops[1],1) ;
/*notiamo che siccome il semaforo era stato inizializzato a 0 la semop con -1 qui
sopra non viene eseguita fino a quando qualcuno non porta il semaforo ad 1*/
/*a questo punto, se voglio effettuare un incremento del semaforo basta risettare
il valore si sem_op e rieseguire senop*/
vsops[1].sem_op=1 ;
semop(id_sem,&vsops[1],1) ;
N.B . Le variabili chiave, id_sem ecc. si intendono definite altrove.
Il controllo di un gruppo di semafori si ha con :
semctl
La sintassi della semctl è :
semctl (id_sem,sem_num,end,arg)
Per eseguire l'azione di controllo :
T ipc_stat per leggere i dati del gruppo di semafori
T ipc_set per variare alcune caratteristiche (es. permessi)
T ipc_rmid per rilasciare la risorsa
T getval restituisce il valore di semval del semaforo specificato
T setval setta ad un intero il semval di un semaforo
T getall legge i valori attuali di tutto il gruppo
T setall setta il valore di tutto il gruppo
Esercizio : Nel modello a memoria comune realizzare la competizione di due processi per l'uso di una risorsa comune :
P1,P2 = processo lettore e processo scrittore
A1 = lettura
A2 = scrittura
Notiamo che non vogliamo risolvere il problema lettore scrittore ma semplicemente il problema della mutua esclusione tra due processi ; cioè dobbiamo unicamente fare in modo che l'accesso all'area di memoria condivisa avvenga in modo esclusivo tra lettore e scrittore.
In UNIX bisogna :
creare i 2 processi
chiedere il rilascio dell'area di memoria condivisa
chiedere il rilascio di un semaforo per la mutua esclusione
gestire il semaforo
Vediamo ora come risolvere l'esercizio proposto nella scorsa lezione :
#include <stdio.h>
#include <sys/types.h>
#include <sys/wait.h>
#define DIM 16
#define NVOLTE 16
main ( )
exit (0);
else
exit (0);
}
else
}
}
Commentiamo tale programma :
Troviamo una parte dichiarativa di tutte le variabili che ci servono per implementare il problema; notiamo che le due chiavi che sono state dichiarate una per l'area di memoria condivisa e l'altra per il semaforo sono IPC_PRIVATE perché se ne chiede il rilascio da parte del processo padre il quale metterà poi a disposizione la risorsa ai processi figli ; con questa dichiarazione i figli hanno automaticamente visibilità della risorsa.
Ci sono poi id_shared e id_sem che fanno da identificativi della risorsa e puntano all'area di memoria condivise ed al semaforo e poi c'è una struttura di appoggio di tipo sem_buf per realizzare le operazioni sul semaforo. Facciamo l'ipotesi di avere un buffer di dimensioni 16 byte e di scrivere su questa area di memoria condivisa per cicli di scrittura consecutivi un carattere diverso di volta in volta, partendo da 'a' . Poi si richiede il segmento di memoria condiviso tramite le opportune procedure. A questo punto basta settare il semaforo a 1 ( si poteva fare anche con SEM_CTRL). Poi si generano i figli: prima lo scrittore con il suo codice che stampa un messaggio e poi fa partire i cicli di scrittura; ogni scrittura viene fatta in mutua esclusione ed si trova in una regione critica; alla fine si incrementa val e si sospende il processo per 5 secondi per rallentare il ciclo di scrittura. Successivamente c'è il codice del lettore che è del tutto analogo a quello dello scrittore; abbiamo sono introdotto un certo ritardo all'inizio per dare allo scrittore il tempo di cominciare a scrivere. Nell'ipotesi che il processo scrittore sia stato schedulato prima del processo padre il quale poi crea il figlio, non ci sono problemi perché c'è almeno un carattere nel buffer. Viceversa se ammettiamo che il processo padre crei il figlio e poi abbia di nuovo assegnata la CPU, una volta creato direttamente il lettore, questo potrebbe leggere prima che ci sia un carattere depositato dallo scrittore. Per impedire un caso del genere bisogna aggiungere dei controlli non previsti in questo semplice programma.
Infine c'è l'else che si riferisce al corpo del padre che aspetta semplicemente la terminazione dei figli e rilascia le risorse. Senza le ultime due istruzioni l'area di memoria rimarrebbe allocata inutilmente.
In UNIX c'è il comando IPCS che permette di conoscere lo stato delle risorse. IPCRM serve invece ad eliminare la risorsa.
Diamo alcuni cenni su come operare con UNIX :
Per aprire una sessione di lavoro in UNIX si specifica il nome dell'utente al login e poi la password; a questo punto si ha un messaggio che dice l'ultima volta che ci si è allogati e si ha il prompt.
Per chiudere la sessione si usa CTRL-D oppure LOGOUT.
L'interfaccia utente è a linea di comando con il seguente formato :
comando flag [argomento.]
es: ls -l -F file1 file2 file3
parametri argomenti
con le convenzioni [ ]= opzionale .=ripetizione dell'ultimo argomento
-Vediamo ora i comandi base di UNIX :
WHO [AM I ] permette di verificare gli utenti allogati o da informazioni sul proprio login
MAN permette di richiamare il manuale in linea diviso in sezioni che possono essere specificate o meno con -s.
PASSWD permette di cambiare la password immettendo la vecchia e la nuova due volte per evitare errori
LAST user permette di conoscere l'ultimo login fatto e da quale macchina.
Vediamo ora alcuni cenni sul FILE SYSTEM di UNIX e cioè come sono organizzati i dati e quali sono i principali comandi per gestire i File.
Il File system è quella parte del sistema operativo che provvede all'organizzazione dei dati degli utenti e quindi alla creazione delle directory che permettono di organizzare logicamente questi dati.
Il File system di UNIX è gerarchico e assomiglia molto a quello DOS; vediamone le caratteristiche :
- è organizzato ad albero a partire dalla Root ( / )
- UNIX vede i file come sequenza di caratteri (byte); ogni strutturazione logica è vista a livello più alto
- ogni file è identificato dal suo I-NODE che è l'accesso ad una tabella ( I-STRUCTURE )che contiene le informazioni sui file del sistema; essa è organizzata a Record che contengono l'I-NODE (numero intero associato al file),il suo nome logico, il creatore del file, la data dell'ultimo accesso ecc.
- UNIX vede anche i device come file speciali permettendo di realizzare la DEVICE INDEPENDENCE
UNIX permette di gestire tre tipi di file, gli ordinari, le directory e i file speciali che come abbiamo già detto corrispondono a device. Ogni file ha il suo identificativo l'I-NUMBER che è un numero intero che permette di trovare il file all'interno del file system.
Al di sotto della Root si trovano le directory di sistema e di utenti ( USR ).
A livello più basso una directory è costituita da una serie di directory entryes ed ha una rappresentazione di questo tipo :
entry entry
|.| [ ] | | [ ] | | |.|
^ ^
| ____________ I-NUMBER 2 bytes in SV
FILENAME 14 bytes in SV
Vediamo un esempio:
| a La directory è organizzata in questo modo :
(107)
| b [. | 202 ] [.. | 107 ] [ c | 253 ] [ d | 289 ] [ EOF ]
c / d . - > Directory stessa
(253) (289) .. - > Directory padre
UNIX permette anche di creare dei link cioè di referenziare un unico file fisico con nomi simbolici diversi (filename sinonimi). Supponiamo di avere (vedi fig. sotto) una directory 89 e un file al di sotto con I-node 107; questo ultimo si può referenziare con nomi logici diversi (b e c) nell'ambito di quella directory e ancora
con un altro link ( e ) nell'ambito dell'altra directory 210. Ci saranno più directory con I-node 107 avente però nomi logici diversi.
| e 89 ..[ b | 107 ] [ c | 107 ] [ d | 210 ]
(89) 210 [ e | 107 ] [ f | 402 ]
b /c d 107 [ ]
(107) --- (210)
e f 402 [ ]
(402)
89 contiene due entry col nodo 107 ( b, c) ; 210 ha 107 col nome e ed f con I-node 402; il 107 è quindi puntato da tre entry con diversi nomi.
Parliamo ora del Path name. A partire dalla Root ( / ) troviamo le varie directory tutte separate da '/ ';
ad esempio potremmo avere / USR / MARIO /PROG per arrivare a PROG (niente di nuovo rispetto a DOS). Tipiche directory di sistema sono : /BIN, /DEV, /ETC, /LIB, /LOST + FOUND, /TMP, /USR.
Ogni utente ha una sua HOME DIRECTORY che gli viene assegnata e che di solito si trova sotto USR.
Per cambiare la directory di lavoro si usa il comando CD.
E' possibile identificare i vari file con Pathname relativi a partire dalla home directory, dalla root ecc.
Ad esempio se mi trovo nella mia home directory (diciamo che sia Roberto ) posso fare:
/USR / ROBERTO / PROG /A per riferirmi ad A nel modo assoluto a partire dalla Root oppure
/PROG /A o anche . /PROG / A tenendo presente che ' . ' identifica la directory corrente.
Viceversa se da ROBERTO voglio accedere ad altri file che si trovano ad esempio sotto MARIO posso fare:
/ USR / MARIO / PROG dalla Root se voglio accedere a PROG oppure con
.. / MARIO / PROG e vi accedo tramite il padre di ROBERTO indicato con ' .. ' o anche con
. / .. / MARIO / PROG sempre partendo da ROBERTO.
Esistono anche i caratteri Jolly che sono come in DOS * e ? (con lo stesso significato).
Parliamo ora dei FILE SPECIALI.
Ogni operazione di accesso ad una periferica avviene facendo riferimento al nome del file col suo percorso.
Richieste di lettura/scrittura su file speciali causano quindi operazioni di I/O sul device corrispondente.
Si ha il vantaggio di avere programmi che fanno riferimento a device che possono essere facilmente modificate all'insaputa del programma stesso. Si ha uno schema di questo tipo :
COMANDI UNIX ---> | UNIX <- DISCHI
| FILE <- STAMPANTI ECC.
PROG. UTENTI ---> | SYSTEM
|
INTERFACCIA
Accenniamo ora all'implementazione dei file (la rivedremo poi meglio). L'I- number del file è la entry in una tabella del file system che contiene le informazioni relative ai file fisici caratterizzati dal loro I- node.
In questa tabella ci sono varie informazioni tra cui il puntatore al file fisico. Esempio :
[ PIPPO | 102 ] 101 |..|
102 |..| ---> Blocchi dati file
Gli attributi del file possono essere :
- Tipo (ordinario, speciale, directory)
- Posizione (Pathname)
- Dimensione
- Numero di Link (quanti nomi ha il file )*
- Permessi
- Data di creazione
- Ultimo accesso
- Modifica
* Questa informazione è importante perché quando cancello il file devo cancellare anche tutti i Link
Vediamo ora qualche comando di base per gestire le directory:
PWD Visualizza la directory corrente col suo Pathname
CD Cambia directory; se non ci sono argomenti torna alla Home directory
LS Lista il contenuto di una directory (è analoga alla DIR del DOS); ha le seguenti opzioni:
-l lista ogni file su una linea
-s visualizza il size dei file
-t ordina i file in modo che il primo sia l'ultimo che è stato modificato
-f dice se il file è eseguibile (*) o è una directory (/)
-r visualizza ricorsivamente tutte le directory interne
-i dà l'I-number
-a visualizza tutti i file (ALL) anche quelli nascosti che cominciano con '.' (Dot-files)
DU Verifica lo spazio che un file occupa
MKDIR Crea una directory nella directory corrente o nel Pathname specificato
RMDIR Cancella una directory solo però se essa è vuota, altrimenti bisogna cancellare tutti i file.
LN nome1 nome2 Crea un Link assegnando a nome1 il nome logico nome2 ( solo per i file )
Trattiamo poi i comandi di gestione dei file :
MV Sposta un file da una directory ad un'altra; ha la seguente sintassi:
MV [OPTIONS] name. target
Muove name sotto target se target è una directory, altrimenti lo sovrappone se target è esso
stesso un file; non si possono spostare più file su un target file.
CP Copia un file; ha la stessa sintassi di MV
RM Rimuove un file; non si può cancellare una directory a meno che non si usa l'opzione -r :
RM [ -r ] name. cancella in maniera ricorsiva tutte le directory
Si possono usare ? per indicare un carattere qualsiasi e * per indicare una sequenza di caratteri
Inoltre ad esempio :
RM file [123] cancella tutti i file che si chiamano file1,file2 o file3
RM file [a-z] cancella tutti i file che si chiamano filea, fileb fino a filez
TOUCH Modifica data e ora dell'ultimo accesso al file
FIND Permette di cercare un file
Tratteremo l'aspetto del sistema operativo che è maggiormente a conoscenza dell'utente.
L'utente sostanzialmente sa come lanciare un programma, come si entra nel sistema e come si lavora con la memoria di massa e quindi come si lavora con i driver (cioè con dischi) facendo operazioni di tipo particolare come p.e. la formattazione e fondamentali tipo l'operazione salva e l'operazione crea directory.
Avendo quindi una conoscenza abbastanza buona di una macchina DOS ed una conoscenza anche superficiale di macchine UNIX, non entreremo nel dettaglio nella descrizione di certi concetti ma vedremo fondamentalmente gli aspetti interni del S.O., per quanto riguarda appunto il File System, per poi vedere l'organizzazione dei file e delle directory fisicamente nelle memorie di massa.
File System
Sappiamo che un file system gestisce essenzialmente una locazione di file sulla memoria di massa e tutte le informazione relative ai file e permette di effettuare operazioni.
Quindi abbiamo due aspetti :
1)Problema di operazione ed allocazione sui file;
2)Problema di gestione delle informazioni che sono connesse ai file;
Un file system è organizzato in directory e file, le directory sono degli oggetti che contengono informazioni riguardanti i file e i file sono oggetti che contengono i dati.
In realtà dal punto di vista astratto un file system vede sia le directory che i file come un insieme di file, infatti se le directory sono degli oggetti che sono presenti in memoria di massa e debbono contenere delle informazioni non possono che essere essi stessi dei file.
I File
Normalmente ogni S.O. ha delle sue regole per la nominazione dei file. A prescindere dal nome, abbiamo che alcuni S.O. permettono di classificare i file secondo una certa tipologia, altri S.O. in realtà non lo consentono.
I S.O. che consentono di classificare i file secondo una certa tipologia, normalmente permettono di esprimere anche la tipologia nel nome stesso del file, facciamo un
Esempio
I S.O. permettono di distinguere i file in eseguibili e non eseguibili. P.e. nel DOS i file eseguibili, vengono distinti dal sistema dai file non eseguibili dal nome stesso del file (in realtà dalla sua estensione), in particolare sono file eseguibili quelli con estensione EXE, COM (ed anche BAT il quale è un command file cioè una serie di comandi interpretabili in batch file).
Abbiamo S.O. che permettono di gestire altri tipi di file oltre a quelli eseguibili e non, (p.e. per lo stesso DOS sono i file batch detti prima).
Esistono S.O. che riconoscono se un file è un file testo (p.e. il DOS non riesce a riconoscerlo, ma da comunque un file ASCII o binario).
Abbiamo altri S.O. che riconoscono i file codici sorgente, questo permette di far ripartire automaticamente, nel momento in cui un file codice sorgente viene scritto in un Editor, i programmi che fanno la rincompilazione di tutti gli oggetti del file sorgente per evitare che una volta effettuata una modifica al livello sorgente dimentichi di riportarlo sull'oggetto stesso.
Riassumendo : sostanzialmente tutti i S.O. distinguono tra file eseguibili e non, altri S.O. permettono di riconoscere qualche altro tipo di file.
Alcuni S.O. permettono di indicare la struttura a record del file, cioè possiamo individuare in un file i record logici costituiti da un certo numero di byte, questi S.O. permettono di effettuare un accesso diretto al record logico, viceversa altri S.O. non permettono all'utente di eseguire il record logico in quanto hanno un loro interno un record fisico standard.
P.e. in UNIX tutti i file vengono visti come una sequenza di byte e quindi a livello di S.O. non possiamo organizzare i vari byte in record logici divisi in certi campi di lunghezza prefissata.
Altri S.O., viceversa, permettono di fare questo ma non tanto di individuare i singoli campi del record ma permettono di definire la lunghezza in byte complessiva del record, questo significa che al livello di applicativo possiamo fare una chiamata al file system e leggere un qualsiasi record, questo fa un certo algoritmo che individua il particolare record desiderato che sarà reso disponibile in un buffer, poi sarà cura dell'operatore di individuare i vari campi e prelevare le informazioni che interessano, quindi l'accesso al S.O. lo facciamo direttamente al livello di record logico.
In UNIX, invece, è permesso di fare il singolo accesso "diretto" però dobbiamo specificare a quale byte dobbiamo effettuare l'accesso, poi è a livello applicativo che dobbiamo vedere ogni record dell'applicazione di quanti byte è fatto e portarci al punto desiderato.
Oss. Quando parliamo di livello applicativo non intendiamo che debba farlo l'utente ma è un compito del compilatore quando genera il codice. Infatti il problema viene risolto a livello di compilazione non al livello di S.O.
UNIX non ha quindi il comandi read e write ad accesso diretto, ma ha solo un accesso sequenziale, però ha due comandi di cui uno permette di posizionare il puntatore ed un altro permette di leggere, dove si deve posizionare il puntatore è un calcolo che dobbiamo fare a parte.
Quindi, come abbiamo detto, elementi fondamentali del file system sono le :
Directory
Tutti i S.O. gestiscono un oggetto particolare che è detto directory.
Questo è un file che contiene un array di record in cui ogni record è un descrittore di file.
Quindi una directory è un qualcosa che viene implementato da un file che contiene un array, dove gli elementi di questo array è un record e questo è un descrittore di file.
Questo record contiene tutte le informazioni che permettono di gestire un particolare file presente nella directory del sistema.
Tipicamente la struttura dei campi di un descrittore di file cambiano dal tipo di S.O.
Supponiamo di avere un array (vedi fig.) ogni elemento dell'array è un record , un elemento di questo
|
Campo |
|
|
|
|
|
|
|
||
|
|
|
|
|
|
Record |
|
|
||
|
|
|
|
Array |
|
|
|
|
|
nome |
|
|
|
|
|
|
|
||
|
|
Had unit |
|
|
|
|
|
|
||
|
|
|
|
Array |
|
|
|
|
record è un descrittore di file ed i campi dipendono dal tipo di S.O. ed esistono alcune informazioni standard.
Oss. Quando parliamo di descrittore di file lo intendiamo nel suo complesso, quindi nulla vieta che nel file (visto come elemento di questo array) non ci siano tutte le informazioni del descrittore di file, ma ci siano solo alcune informazioni e poi esista un puntatore che ci mandi su di un altro array, nel quale ci sono delle informazioni che completano il descrittore di file (infatti UNIX funziona in questo modo), e quest'ultimo array è unico per tutte le directory i-node.
Vediamo ora quali sono le informazioni memorizzate in un campo nel descrittore di file:
1)Nome del file (nome simbolico del file);
2)Tipo di file (solo in S.O. che gestiscono il tipo, cioè essenzialmente file eseguibili e non);
3)Locazione (dispositivo e allocazione sul dispositivo);
4)Posizione corrente (puntatore alla posizione corrente di lettura/scrittura del blocco)
5)Protezione (informazioni per il controllo dell'accesso);
6)Contatore di utilizzo (# di utenti che allo stato condividono il file, poiché se p.e. vogliamo eliminare il file dobbiamo vedere se tutti gli utenti sono d'accordo);
7)Ora e data (ora, data e identificatore di processo);
8)Identificatore di processo (relativamente ad operazioni quali: creazione, ultima modifica e ultimo utilizzo del file)
Oss. Per quanto riguarda la locazione, sappiamo che nel S.O. DOS non abbiamo un solo file system ma ne vediamo tanti( è una foresta ),viceversa nella macchina UNIX il file system è unico, questo indipendentemente se il file lo abbiamo sull'Hard-Disk o su floppy disk.
Quindi dato che su UNIX il file system è unico, indipendentemente dai supporti fisici (cioè da i vari file), per poter lavorare con unità esterne dobbiamo fare in modo di collegare questo all'intero File system per poterli rendere visibili (questo perché il file system non è una foresta di alberi, ma è un unico albero).
Oss. Per quanto riguarda la posizione corrente, questa la utilizziamo quando facciamo una lettura e scrittura di un file, e sappiamo che prima di poter scrivere su di un file dobbiamo fare l'operazione di aperture a di un file (peraltro questo non è previsto da tutti i S.O.) e questa operazione consiste nel prendere il descrittore del file e portarlo in una cache in memoria RAM.
Quindi nella RAM il S.O. gestisce una tabella (vedi fig.)
|
Tabella dei file aperti |
|
|
|
|
|
Descrittore di file compl. |
|
|
|
|
|
|
che è la Tabelle Dei File Aperti in cui ciascun rigo di questa tabella contiene un descrittore di file completo e solo da questo momento possiamo scrivere e leggere e dopo questa operazione la posizione del puntatore non ha alcuna importanza.
Tra questi campi il più importante è il campo locazione, la cui articolazione può essere più o meno articolata dipendentemente dalle varie tecniche di allocazione che il S.O. gestisce sui file.
Oss: Vedremo nelle prossime lezioni quali sono queste particolari tecniche di allocazione e per ogni tecnica ci saranno delle particolari informazioni che dovranno essere gestite e che sono presenti nel campo che abbiamo chiamato locazione( il quale nei fatti è anch'esso un record quindi ha anch'esso una strutturazione interna).
Soltanto nei S.O. elementari il file directory coincide con il file della directory che è presente sul disco fisico (cioè se abbiamo un supporto fisico, un dischetto p.e. probabilmente su questo, nei primi blocchi, è presente un file in sono contenute tutte le informazioni relative ai file del dischetto stesso).
Gestione di un file directory
Le tre operazioni fondamentali che vengono fatte a livello di directory sono la creazione e la cancellazione di un file oppure l'apertura o la chiusura o visualizzazione dei dati relative ad un file.
Creare o aggiornare un file significa aggiungere un descrittore di file all'interno di un file directory, ovviamente cancellare un file significa eliminarlo, visualizzare significa accedere o ricercare dei dati.
Queste operazioni presuppongono ovviamente una visita dei descrittori di file, ed in particolare la creazione deve fare una operazione di visita totale, mentre la visualizzazione e la cancellazione presuppongono una visita parziale. Infatti dal momento in cui vogliamo creare un file dobbiamo essere certi che non esiste un file con lo stesso nome, per la cancellazione e per la visualizzazione ci fermiamo appena lo troviamo.
Dal momento di creazione del file dobbiamo trovare lo spazio per allocare in un descrittore di file, poiché di solito quando viene fatta la cancellazione di un file lo spazio non viene ricompattato, allora lo spazio disponibile sarà quello occupato da un precedente file e, se la tecnica lo consente, si può allargare questo spazio se ciò e indispensabile per la sua allocazione.
Oss. Questo fa capire che la cancellazione è un fatto logico e non un fatto fisico, poiché il descrittore ha un puntatore fisso in memoria.
Esistono un insieme di organizzazioni che variano a seconda del S.O. i quali cercano di velocizzare al massimo le operazioni di creazione , cancellazione dei file e di visualizzazione ossia di ricerca di un descrittore.
Ovviamente nel momento in cui vogliamo lavorare su di un file, le operazioni fondamentali sono :
1)Apertura di un file;
2)Chiusura di un file;
3)Creazione di un file(scrittura);
4)Lettura di un file;
5)Reset di un file;
Queste operazioni equivalgono a fare l'operazione di trasferimento tra la memoria di massa e la RAM (e viceversa) di un descrittore di file.
L'apertura di un file è una operazione in cui trasferiamo un descrittore del file dalla directory alla tabella e quindi anche questa operazione è onerosa, poiché presuppone la ricerca in un file directory il descrittore del file che dobbiamo aprire. Peraltro, come abbiamo detto, l'operazione di apertura è fondamentale poiché trasferiamo tutto il descrittore nella Tabella dei File Aperti (vedi fig.) e quindi per una successiva operazione non abbiamo più bisogno di accedere a memoria di massa.
Quindi aprire un file significa assegnare una nuova entry nella Tabella dei File Aperti e questo significa anche dire che da questo momento in poi non abbiamo più bisogno di inizializzare il file con il nome simbolico ma viene referenziato a livello sistema dall'entry della tabella dei file aperti.
Esempio
Una volta che abbiamo aperto il file PIPPO l'operazione successiva di scrittura e lettura su PIPPO non viene fatto dal nome simbolico PIPPO ma vengono fatti in riferimento ad un numero (3,4,.) che è la entry del descrittore di PIPPO nella Tabella dei File Aperti.
La Tabella dei File Aperti non è detto che sia unica, infatti possiamo avere più Tabelle dei File Aperti e questo dipende come è organizzato il sistema ( in UNIX abbiamo più Tabelle dei file Aperti ed ogni processo ha una propria tabella).
Alcuni S.O. richiedono la definizione del numero massimo di tabelle aperte contemporaneamente (sono quelli che lavorano a tabella fissa ) e quindi bisogna conoscere qual è lo spazio totale disponibile.
La chiusura del file è l'operazione opposta dell'apertura e comporta la registrazione del contenuto dell'entry in memoria RAM della directory e l'annullamento dell'entry in RAM.
Oss. A livello di linguaggio, l'apertura e la chiusura di un file non è detto che siano presenti, cioè esistono dei linguaggi che hanno degli stantement appositi per aprire e chiudere i file ed altri invece in cui non sono previsti. Questo significa dire che il S.O. automaticamente apre nel momento in cui fa la prima lettura (o scrittura) sul file e chiude nel momento in cui termina il programma e naturalmente la chiamata al S.O. per aprire e chiudere è fatta dal compilatore.
Oltre all'operazione di apertura e chiusura di un file, altre operazioni che possiamo fare sono quella di scrittura e lettura di un file.
Se abbiamo la Tabella dei File Aperti, nel momento in cui scriviamo non andiamo più ad accedere al file directory ma dobbiamo accedere direttamente alla Tabella dei File Aperti dove troveremo direttamente il puntatore. Se invece non c'è l'apertura dobbiamo fare un accesso al file directory e dobbiamo eventualmente individuare il puntatore.
Oss. Stiamo parlando di scrittura e lettura in termini sequenziali di un file.
La stessa cosa vale per la lettura di un file ma con l'operazione inversa a quella di scrittura.
Abbiamo sistemi in cui il puntatore di lettura e scrittura sono distinti ed altri sistemi in cui è unico (e questo dipende dal particolare S.O.) e in quest'ultimo caso è associato il comando di posizionamento del puntatore che permette appunto di poter ridefinire la posizione del puntatore e quindi non c'è bisogno che si abbia esplicitamente la lettura e scrittura diretta del file, poiché possiamo sempre avere una coppia di comandi del S.O. nel quale il primo posiziona il puntatore ed il secondo legge o scrive. Peraltro esistono S.O. che hanno anche le supervisor-call con le quali facciamo direttamente una lettura e scrittura diretta e questo è particolarmente importante per i S.O. che hanno una struttura a record di un file, infatti definiamo prima qual è la struttura a record di un file e puntiamo direttamente al record e quindi in questo caso non utilizziamo i puntatori(questo tipo di accesso non è previsto da UNIX ).
Vediamo ora quali sono i metodi di accesso supportati dal S.O. ai file :
1)Accesso sequenziale (questo è offerto da tutti i S.O.);
2)Accesso diretto (questo è offerto da alcuni S.O.);
3)Accesso mediante un indice (Index Sequention Access Metod, cioè possiamo accedere ad un file mediante un file indice (chiave) e questo è un tipo di accesso molto sofisticato usato da ISAM);
Vediamo alcuni esempi di comandi del S.O. per l'accesso sequenziale e diretto:
1)Read next (comando di una lettura sequenziale per un S.O. che prevede una struttura a record, "leggi il prossimo record logico");
2)Write next (comando di scrittura come sopra);
3)Read n (comando di lettura ad accesso sequenziale o diretto, è sequenziale se è inteso come " leggi i prossimi n byte",( e questo è un comando esistente in UNIX ) e potrebbe anche essere visto come un comando di accesso diretto in cui diciamo "leggi il record n" e quindi dipende dalla semantica che diamo a questo comando);
4)Write n (comando di scrittura ad accesso sequenziale o diretto come sopra);
5)Position to n (comando che posiziona il contatore);
Oss. Questi sono comandi che evidenziano solo la semantica, poi ognuno di questi sarà espresso in modo opportuno, p.e. in UNIX esiste una supervisor-call che è chiamata tramite una routine C.
Un'altra osservazione da fare, relativa ai file condivisi, è che dal momento in cui abbiamo la possibilità di condividere dei file dobbiamo sapere se due utenti possiedono lo stesso file, vogliono aprire lo stesso file e operare sullo stesso file oppure vogliono operare sullo stesso file senza avere la necessità di aprirlo a livello di directory
Esempio
Abbiamo un utente che vuole accedere al descrittore di un file per modificare le regole di accesso e un altro utente per gli stessi motivi vuole accedere allo stesso descrittore di file.
Quindi abbiamo bisogno di avere dei S.O. che devono gestire dei LOCK
LOCK dei file condivisi
I Lock impediscono i conflitti che possono aversi per file condivisi. Possiamo avere dei Lock a vari livelli, poiché la condivisione può avvenire a livello di descrittore di file qualora ognuno abbia il proprio descrittore e viene rimandato ad un unico punto e quindi dobbiamo gestire la lettura e la scrittura dell'accesso a questa parte del descrittore che è condivisa. Un altro tipo di Lock può essere quello che potrebbe capitare in UNIX in cui due utenti aprono un file condiviso, cioè l'utente A ha un descrittore della Tabella dei File Aperti visto dal processo A e il processo B vede anch'esso la sua Tabella dei File Aperti e quindi avrà un entry che è relativa allo stesso file. UNIX permette questo tipo di gestione dal momento in cui ha memoria di massa sufficiente e quindi ha una tabella degli i-node dei file aperti (in RAM) Quando apriamo un file, il descrittore lo mette nella tabella in cui convergono la coppia di puntatori e decide se le informazioni possono essere condivise o non (vedi fig.).
|
A |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
B |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Tabella |
|
|
|
|
|
|
|
Tabella i-node |
Oss P.e. le tabelle A e B sono rispettivamente padre e figlio e sono quindi diverse ma hanno la tabella di mezzo comune in modo tale che questi possano cooperare. Se abbiamo invece abbiamo che A e B condividono il file ma non cooperano, cioè sono due programmi differenti che generano processi differenti che però lavorano sullo stesso file allora ognuno di questi avrà il suo puntatore.
Se abbiamo condivisione di file abbiamo la possibilità che due processi accedano allo stesso blocco di disco, quindi abbiamo bisogno di un altro Lock che però è gestito dal segmento del S.O. che gestisce sequenziali zeri accessi sul disco. Quindi, in altre parole, non si può mai verificare che due processi accedano fisicamente allo stesso blocco di disco, cioè comunque accederanno in sequenza e tramite una gestione di ordinamento degli accessi ( p.e. applicando la routine dell'ascensore per ottimizzare il tempo medio di attesa della coda).
Un altro tipo di conflittualità può nascere in una rete di computer, infatti da un PC arriva un file condiviso da un altro PC e dal momento in cui lo apriamo può accadere che quel file venga trasferito localmente e possiamo lavorarci Ovviamente quel file deve essere lockato per impedire ad altri utenti la condivisione.
Possibilità di caricare un file in memoria virtuale
Se abbiamo un sistema a memoria virtuale possiamo aprire un file e trasferirlo in memoria (cache). Naturalmente il file non andrà in memoria RAM, ma se abbiamo una memoria centrale che è gestita con il principio della memoria virtuale vuol dire che questo file viene trasferito dalla parte del disco che è gestito dal file system viene copiato dalla parte del disco che gestisce il meccanismo della memoria virtuale e da quel momento in poi a livello applicativo leggiamo e scriviamo come se avessimo tutto il file in memoria. Nei fatti questa area di memoria non esiste e il travaso tra memoria di massa alla memoria centrale o viceversa viene gestita dal meccanismo che gestisce la memoria virtuale, e questo ha il vantaggio di velocizzare gli accessi poiché la memoria virtuale funge da cache.
Altre operazioni che il S.O. può fare sui file sono:
1)Modifica di un blocco di file (cioè invece di avere i comandi di read e write abbiamo il comando di modifica, cioè di rilettura e riscrittura)
2)Aggiunta di blocchi in coda (Append);
3)Copia di un file su disco o su altro (p.e. da un lato un disco e dall'altro un video ed una stampante);
4)Dispositivi di I/O
Oss. I comandi di UNIX sui file sono:
CREAT per creare;
OPEN per aprire;
READ per leggere;
WRITE per scrivere;
LSINK per posizionare il puntatore;
CLOSE per chiudere;
TRUNC non cancella il file però lo azzera, cioè mantiene il nome, il descrittore e riduce a
zero la lunghezza fisica del file esistente;
RENAME nuovo nome;
CVOID per cambiare i diritti di accesso al file;
CARM per cambiare i diritti del proprietario;
START per avere informazioni del file nella directory;
La lezione scorsa abbiamo detto che le directory erano dei file particolari i cui record erano i descrittori dei files in esse contenuti.
In particolare, qualcuno di questi record potrebbe essere il descrittore non di un file dati ma di un file-directory; questo significa, nei fatti che è possibile creare una struttura ad albero delle directory.
Generalizzando questo discorso potremmo avere un file system a n livelli. Fino alla fine degli anni settanta i file system erano piatti, cioè ad un solo livello. Successivamente nacquero i file system a due livelli (nei grossi mainframe): al livello uno c'era una directory base che non conteneva files ma solo sottodirectory ed era accessibile unicamente al Supervisore; al livello due vi erano le directory degli utenti, una per ogni utente, e tali directory erano piatte perché non potevano avere sottodirectory.
I sistemi operativi odierni (a cominciare da UNIX e poi dal DOS) hanno una struttura multilivello. In generale tale struttura è una struttura a grafo. Quando il sistema non permette la condivisione di file o directory, il grafo è un albero; quando è ammessa la condivisione, il grafo è un grafo aciclico o addirittura un grafo generale(cioè contenente anche cicli). Ad esempio guardiamo la figura uno:
Nella figura 1 Abbiamo un grafo che non è un albero, infatti già se guardiamo unicamente i files ci sono alcuni files che pur essendo comunque delle foglie, sono appesi a più rami; del resto ci sono delle sottodirectory condivise. Se poi, qualche sottodirectory condivide directory di livello superiore, come nel caso dell'arco uno il grafo si trasforma da aciclico in ciclico.
Bisogna evitare che con la leicità della condivisione di directory, andando a condividere qualche directory, si venga a creare una struttura ciclica. Il problema che si potrebbe avere con un ciclo è che, venendo a mancare un link, si può avere un'intera parte del file system che non è più raggiungibile in quanto manca il collegamento, ma che non essendo stata cancellata occupa ancora dello spazio sul disco. Per recuperare tale spazio è poi necessario far girare degli algoritmi che vanno a percorrere il file system non da un punto di vista logico ma vanno a fare un analisi a tappeto dei dischi andando a vedere se ogni blocco del disco è referenziabile dalla parte della file system che è ancora raggiungibile e mettendo nella lista del disponibile tutti quei blocchi del disco che non sono più raggiungibili (in sostanza questi programmi percorrono il file system segnando tutti i blocchi del disco che man mano vengono raggiunti dal file system e mettendo poi nella lista del disponibile tutti quelli che non sono stati segnati).
In ogni caso le informazioni presenti nelle directory rimaste isolate vengono perdute.
Implementazione della condivisione
La tecnica più naturale che si può pensare per realizzare la condivisione di file (o directory ma ragioniamo in termini di files) è quella di duplicare il descrittore del file; Ad esempio, nella figura 1 avremmo un descrittore nella directory Pippo e uno nella directory Winny.
Tuttavia questa tecnica ha dei notevoli inconvenienti. L'inconveniente principale di questa tecnica è che avendo più descrittori che si riferiscono allo stesso file si deve poi stare attenti a mantenere la coerenza di tali descrittori cioè a gestire il loro allineamento. Del resto, implementando la condivisione attraverso la duplicazione dei descrittori non risolviamo il problema critico della condivisione che è quello della cancellazione dei files; infatti volendo cancellare un file condiviso da una determinata directory si deve stare attenti a cancellare il descrittore ma non il file altrimenti rimarrebbero appesi gli altri descrittori che facevano riferimento a quel file e che quindi andrebbero a puntare un qualcosa che non è più il loro file.
Un terzo problema è che, avendo più descrittori di uno stesso file magari anche con nome differente, si può rischiare di referenziare il file più volte. Ad esempio in un operazione di backup io arrivo ad un file da due directory differenti nelle quali magari il file ha un nome differente e quindi salvo due volte lo stesso file.
Il modo più diffuso per implementare la condivisione, usato anche da UNIX, è quello dei link.
Un link è un elemento di una directory di tipo speciale che punta ad un elemento di un'altra directory e quindi ad un file o ad una sottodirectory condivisa. In alcuni sistemi operativi il link può essere simbolico (soft) e quindi costituito da un pathname assoluto (cioè che parte dalla radice) o relativo (che parte da una sottodirectory).
I link non simbolici vengono detti hard link.
Il link simbolico funziona in questo modo:
Quando viene effettuato un riferimento ad un file viene effettuata una ricerca nella directory che contiene il link, parte una routine il cui compito è quello di risolvere un pathname (tale routine è tipica di tutti i sistemi operativi che hanno un file system organizzato a più livelli) fino ad accedere al file reale.
Il vantaggio enorme che si ha con i link simbolici è che non c'è la possibilità che il sistema fallisca a seguito di un accesso errato. Ad esempio se abbiamo un file condiviso da due directory e il possessore del file lo cancella, un programma applicativo che cercasse di accedere a tale file dall'altra directory farebbe partire la routine che risolve il pathname che non trovando il descrittore originale del file darebbe un messaggio di errore comportando il fallimento dell'applicativo ma non il crollo del sistema. Cioè la routine che risolvere il pathname prevede un uscita di errore qualora non sia stato possibile risolvere il percorso ma non causa l'arresto del sistema. Ovviamente, a maggior ragione, cancellare un link simbolico non comporta alcun tipo di problema.
Quindi, si capisce che con i link simbolici il problema della cancellazione dei files è almeno in parte risolto in quanto un accesso ad un file inesistente viene trattato come qualsiasi accesso errato e quindi non essendoci la possibilità (come invece c'era nel caso precedente) di accendere tramite un collegamento sbagliato, ad un file che magari appartiene a qualche altro utente si può riallocare immediatamente l'area del disco occupata dal file cancellato.
Anche il problema (che anche apparteneva alla tecnica precedente) del disallineamento dei descrittori ora non esiste più. Infatti con questo meccanismo noi abbiamo un solo descrittore in una directory e una serie di puntatori nelle altre directory che condividono il file, quindi non essendoci più descrittori dello stesso file non abbiamo il problema del disallineamento.
Anche i link simbolici hanno il problema che un file può avere più pathname assoluti. Questo è un problema che riguarda specialmente i programmi applicativi perché vedendo lo stesso file magari con nomi diversi possono accedere ad esso più volte.
Riguardo alla cancellazione di un file condiviso, un altro modo di procedere sarebbe quello in cui il proprietario del file nel momento in cui lo vuole cancellare controllo prima se non ci sono più puntatori a quel file altrimenti lo cancella solo da un punto di vista logico lasciando il descrittore fino a quando tutti gli altri utenti che condividevano il file non lo cancellano; solo a questo punto lo spazio occupato dal file potrà essere recuperato. Questo procedimento è facoltativo nel caso dei link simbolici (in quanto non ci sono problemi di accessi errati) è invece necessaria nel caso degli hard link.
Infatti con gli hard link non si riesce ad evitare il problema (come accadeva con la stato duplicazione dei descrittori) che da un link appeso possa andare ad intervenire su aree di disco che nel frattempo possono essere state allocate ad altri files magari di terzi.
Per realizzare una tale strategia di cancellazione si deve necessariamente disporre o di una lista dei riferimenti oppure, perlomeno, di un contatore ai riferimenti; cioè devo sapere quanti sono i link che insistono su un certo file in modo tale da impedire la cancellazione del file finché questo contatore sia maggiore di uno.
In realtà questo è abbastanza semplice da realizzare. Infatti basta che nel descrittore reale (cioè non in quello di tipo link) vi sia un campo contatore di condivisione. Ciò significa dire che soltanto quando tale campo è uno nel momento in cui si chiede la cancellazione del file, il descrittore vero del file, così come il file stesso vengono rimossi.
Precisamente, la cosa funziona in questo modo: una cancellazione da una directory che contiene un link si traduce nella eliminazione del link in questione e nel decremento del contatore di condivisione. Una cancellazione da parte della directory proprietario del file e che quindi possiede il descrittore reale, si traduce in una reale cancellazione solo nel caso in cui il contatore di condivisione abbia valore 1. Se il contatore di condivisione ha valore maggiore di uno, il descrittore della file viene cancellato solo logicamente cioè viene reso inaccessibile dalla directory proprietaria ma accessibile attraverso i link rimanenti. Il descrittori ed il file stesso verranno rimossi quando il contatore assumerà il valore 1.
In UNIX, questo problema è risolto in modo molto semplice; infatti in UNIX la situazione è un po' differente dal caso generale (vedi figura 2).
CASO UNIX
Abbiamo due directory che condividono un file. Nel caso generale il descrittore dello file è contenuto nella directory A mentre nella directory B c'è un hard link che punta a tale descrittore che a sua mostra punta al file.
Nel caso di UNIX il descrittore è contenuto nell'i-node e nelle directory A e B ci sono solo i puntatori al descrittore. Il contatore di condivisione è contenuto nel descrittore. Quindi la cancellazione del file da parte di una delle due directory comporta semplicemente la eliminazione del suo puntatore all'i-node e il decremento del contatore di condivisione presente in quest'ultimo; lo spazio occupato da tale puntatore può essere immediatamente riallocato a qualche altro puntatore a file. Il descrittore e nell'i-ndole e verrà eliminato quando il contatore di condivisione assumerà il valore 0.
Negli appunti presi in classe al posto della parola 'base' compare qui e nel seguito 'costante di spiazzamento', il che è chiaramente e notevolmente errato (ad esempio: che senso avrebbe un processore con un solo registro base e più registri di spiazzamento?!?).
Totalmente sballati apparivano i calcoli sugli appunti presi in classe: T t + 0,1 * t * 0,9 + 2t * 0,1 = 1,29 t (??) da cui T/t 1,29, e per di più c'era scritto che questo tempo di accesso medio poteva essere espresso come t + 3 t (ossia 4t che è ben maggiore di 2t, per cui questo 'marchingegno' dovrebbe essere certamente scartato!).
Sembra di capire che nel primo caso ad ogni processo è associata una differente tabella delle pagine, contenente gli indirizzi dei vari frame di cui dispone; mentre nel secondo esiste un'unica tabella della pagine valida per l'intero spazio di memoria logica.
Segue misteriosa osservazione di De Carlini, presente tra l'altro anche sul Silberschatz-Galvin (pag.268): "Ad esempio, in un segmento possiamo inserire un array perché così mi rendo conto subito tramite una Trap se sono uscito dall'array e quindi dal segmento (meccanismo automaticamente gestito)".
Nel Silberschatz-Galvin (pag.283 sgg) si afferma che il bit di validità segnala anche la condizione di 'indirizzo illecito' (non corrispondente ad una pagina fisica accessibile al processo). Pertanto, tale bit può essere 'non okay' per due diversi motivi: indirizzo illecito, pagina residente su disco (sarà poi il SO a discriminare fra i due casi). De Carlini non ha menzionato questo aspetto durante la lezione. La figura di pagina 179 è stata modificata (rispetto a quella del libro, che sta a pag.285) in base alla spiegazione di De Carlini.
|
| Appunti su: https:wwwappuntimaniacominformaticacomputerla-gestione-della-memoria54php, |
|