|
| Appunti informatica |
|
|
| Appunti informatica |
|
| Visite: 1999 | Gradito: |
Leggi anche appunti:Il computerIL COMPUTER ll personal computer (in italiano elaboratore personale), Funzione 'sislin'Funzione 'sislin' SCOPO: Calcolare la soluzione di L'htmlL'HTML (Comprenderlo e realizzare una pagina in HTML) HTML HyperText Markup |
 |
 |
Università degli Studi di Napoli "Federico II"

Facoltà di Ingegneria
Corso di Laurea Specialistica
in Ingegneria Informatica
Elaborato di
Intelligenza Artificiale
ABSTRACT
OBIETTIVO
FETURES SELECTION
DIMENSIONAMENTO RETE
VALUTAZIONE DEL COSTO DI CLASSIFICAZIONE
SPUNTI DI RIFLESSIONE
|
Capitolo |
ABSTRACT
Il contest consiste nella costruzione e nell'addestramento di un classificatore che riesca a discriminare campioni che appartengono alle seguenti classi:
Ciascun campione è caratterizzato da un insieme di tipi di features:
Obiettivo
Ogni vettore di features rappresenta una cellula alla quale deve essere assegnata una classe di appartenenza. L'obiettivo è minimizzare il costo del sistema di classificazione tenendo conto di una particolare matrice dei costi fornitaci.
Questa documentazione può essere vista come divisa in due parti: la prima parte consiste nella esposizione di tutte le operazioni effettuate durante il processo di feature selection, mentre la seconda parte descrive le scelte effettuate nella configurazione del classificatore.
Non ci soffermeremo a fondo sugli aspetti di configurazione banali dei blocchi del software Knime per dare più spazio all'esposizione delle scelte progettuali che abbiamo preso durante il dimensionamento della rete.
|
Capitolo |
FEATURES SELECTION
La features selection è il processo che consiste nella scelta, a partire da un insieme di features più o meno vasto, di un sottoinsieme del gruppo di features iniziali che però conservi un potere discriminante tra i vari campioni soddisfacente.
Allo scopo di poter estrapolare diversi gruppi di features per un successivo confronto, abbiamo utilizzato il blocco AttributeSelectedClassifier che ci permette di far variare sia le strategie di ricerca con cui ci si muove all'interno dello spazio di ricerca per la composizione dei gruppi, sia gli evaluators per la valutazione del potere discriminante dei gruppi di features.
Nella seguente tabella sono riportate le combinazioni "evaluator , search" utilizzate da noi all'interno del blocco suddetto e i gruppi di features risultanti.
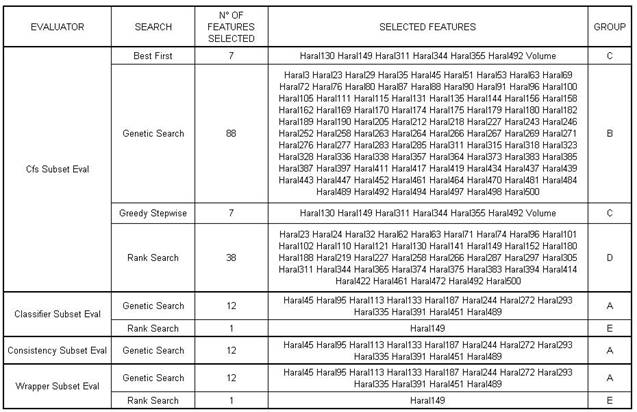
Figura
Si riporta una spiegazione degli Evaluators:
Cfs Subset Eval: valuta la capacità di discriminazione di un sottoinsieme di attributi considerando l'abilità predittiva di ogni attributo unitamente al loro grado di ridondanza (ad esempio consente di capire se l'aggiunta di un altro attributo non aggiunge informazione). I sottoinsiemi di attributi aventi un'elevata correlazione con la classe di appartenenza e una bassa intercorrelazione sono quelli che saranno selezionati.
Wrapper Subset Eval: effettua la selezione delle features utilizzando dei wrapper, ossia si valuta un particolare sottoinsieme di features tenendo conto di uno specifico modello di apprendimento e delle sue performance in termini di errore.
Classifier Subset Eval: simile al precedente, solo che utilizza una differente funzione di errore.
Consistency Subset Eval: si cercano combinazioni di attributi i cui valori dividono i dati in sottoinsiemi che contengono una forte maggioranza di una classe. La ricerca è a favore dei sottoinsiemi piccoli ad alta consistenza; la consistenza può essere calcolata con diverse metriche suggerite da vari autori.
Si riporta una descrizione degli algoritmi di ricerca:
Greedy Stepwise: utilizza essenzialmente un algoritmo hill-climbing.
GeneticSearch: utilizza semplici algoritmi genetici.
Bestfirst: utilizza la beam search, una particolare tipologia di algoritmi di ricerca basato sui cammini.
RankSearch: a partire da una lista di attributi a cui sono stati dati dei voti tramite un evaluator e che è stata ordinata in ordine decrescente di voto, il RankSearch valuta l'efficacia di gruppi crescenti di features prendendo dall'inizio della lista a seguire.
Sono risultati 5 gruppi distinti di features con
cardinalità che va da
La fase successiva è stata quella di effettuare una prima scrematura dell'insieme di gruppi features, eliminando quelli che possiamo affermare che daranno dei risultati peggiori.
Per fare ciò abbiamo effettuato una cross-validation per ogni gruppo di features a parità di rete per vedere quale dava i risultati migliori.
Lo schema di riferimento per la cross-validation e i risultati ottenuti sono riportati nelle immagini seguenti:
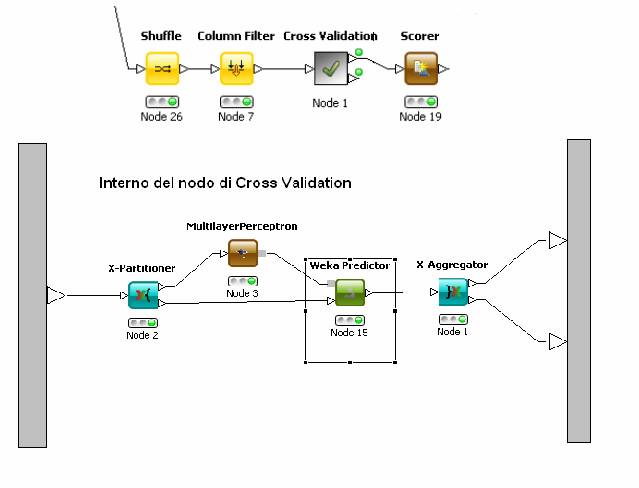
Figura
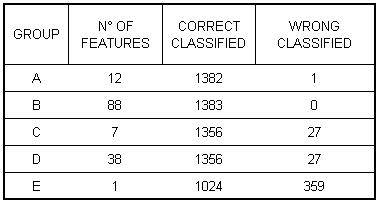
Figura
I risultati ottenuti ci lasciano pensare che i gruppi di features C, D ed E sono quelli che possono essere già scartati, mentre il gruppo A e il gruppo B possono passare alla fase successiva e la scelta di quale gruppo utilizzare sarà effettuata su delle considerazioni a granularità più fine.
(Nota: per rendere ripetibili i vari esperimenti abbiamo usato all'interno dello shuffle un seed pari a 2314254160389116688).
Per completezza si riporta anche una figura in cui si evidenza come effettivamente le features estratte dal processo riescano a due a due ad effettuare una buona "discrimazione" tra i campioni.
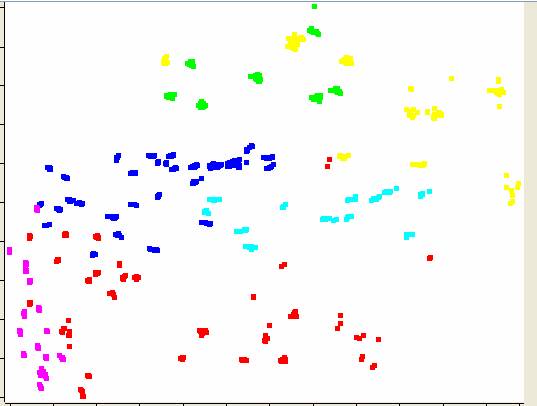
Figura
|
Capitolo |
DIMENSIONAMENTO RETE
In questa fase andremo effettivamente a scegliere il gruppo di features finale tra i due su cui eravamo ancora indecisi (gruppo A o B) e andremo a dimensionare la rete.
La rete che è stata utilizzata è una rete neurale percettrone multilivello, per cui dimensionarla significa settare il numero di strati hidden, il numero di neuroni, il learning rate e decidere il numero di epoche di addestramento. Lo schema di riferimento per questa fase è il seguente:
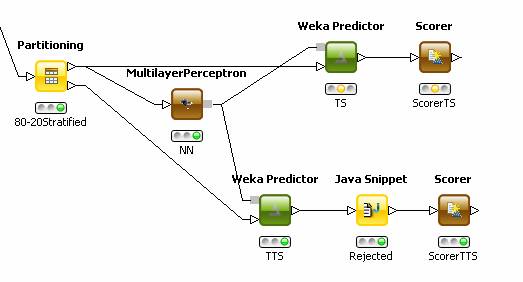
Figura
(Nota: per rendere ripetibili i vari esperimenti abbiamo usato all'interno del partitioning un seed pari a 1552). Abbiamo deciso di settare inizialmente il learning rate a 0.5 che è un valore tipico e abbiamo deciso di inserire un unico strato hidden per limitare il problema dei minimi locali.
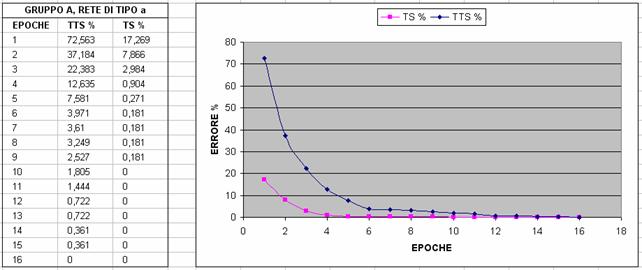
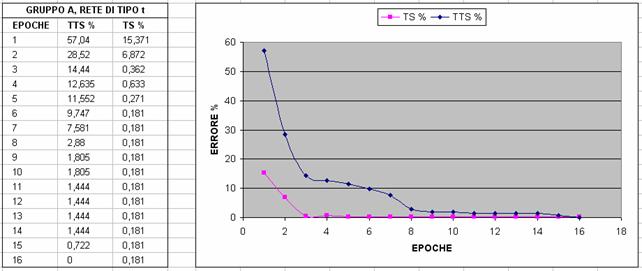
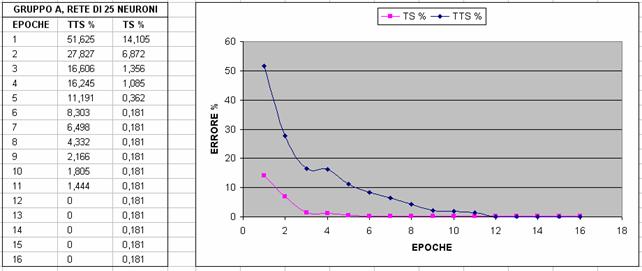
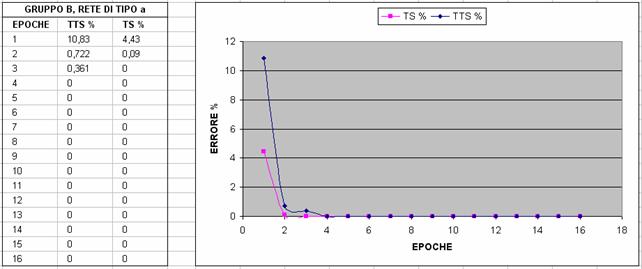
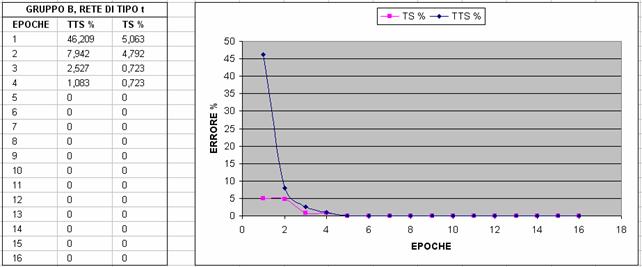
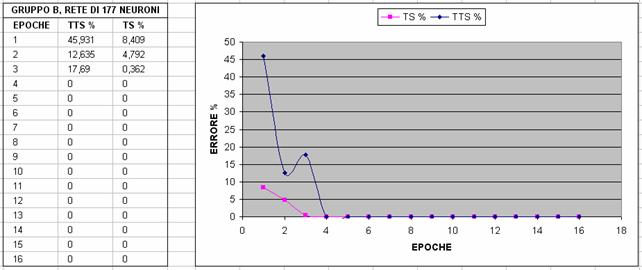
Nelle immagini che seguono si riporta un confronto fra diverse configurazioni al variare del gruppo di features utilizzato (gruppo A o B) e al variare del numero di neuroni; in particolare si valuta l'errore percentuale sul TTS e sul TS con un Partitioner settato in maniera tale da dividere l'80% del dataset in Test Set (TS) e il restante 20% in Training Test Set (TTS)
Figura
Figura
Figura
Figura
Figura
Figura
A partire da questi grafici, abbiamo deciso di scegliere la terza configurazione, ossia il gruppo A con 25 neuroni, per i seguenti motivi: abbiamo preferito la terza configurazione alla prima e alla seconda perché converge prima verso il minimo (che in questo caso è il minimo globale,vedi NOTA2) e poi l'abbiamo preferita alla quarta, alla quinta e alla sesta perché, sebbene la rete addestrata con più features converga in meno epoche, il numero di epoche di addestramento che si risparmiano non giustifica il tempo di addestramento di gran lunga maggiore che si impiega e il numero significativamente maggiore di neuroni necessario (rischio di overfitting); tuttavia ancor non abbiamo deciso il numero di epoche di addestramento poiché le curve tendono tutte al valore asintotico nullo e quindi abbiamo ritenuto opportuno effettuare questa scelta tenendo conto di risultati statistici più precisi.
NOTA1: Il fatto che in ogni caso l'errore vada a zero e ci si stabilizzi supponiamo sia dato dal fatto che TTS e TS siano molto simili come distribuzione. Infatti, anche andando a variare di molto il numero di epoche (anche di vari ordini di grandezze) non si verifica overtraining cioè l'errore commesso sul TTS è sempre di 0%.
NOTA2: facendo riferimento alla figura 8 (cioè rete di 12 features con 25 neruoni), il fatto che l'errore su TS sia ancora a 0.181 alla dodicesima epoca (mentre, ad esempio, nella prima è già 0) è poco rilevante perché dipende dal seed del partitioning. Infatti cambiando il seed si può arrivare a 0: ciò che interessa a noi non è tanto confrontare chi arriva per prima a zero, ma chi ci si accosta in maniera più veloce sul TTS.
NOTA3: In figura 5, sul ramo inferiore, abbiamo inserito lo JavaSnippet tra lo Scorer e il Predictor per valutare l'accuratezza tenendo già conto degli errori di classificazione dovuti al rigetto, come da semantica del problema; se togliessimo lo JavaSnippet le percentuali di errore sarebbero, ovviamente, leggermente più basse.
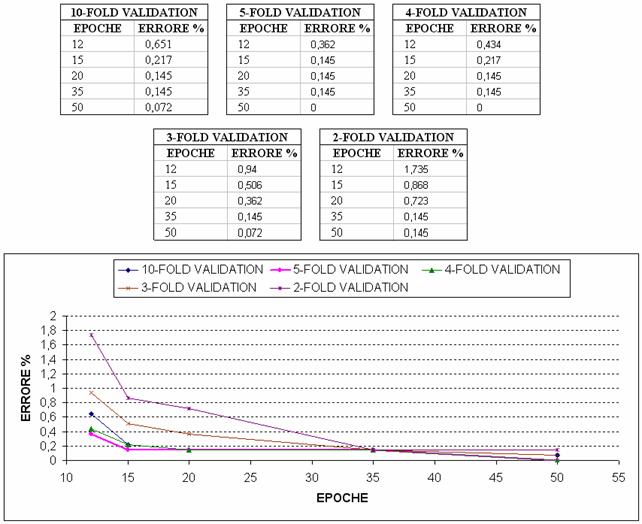
Adesso non ci resta che settare il numero di epoche: abbiamo deciso di scegliere questo parametro effettuando diverse cross-validation al variare del numero di epoche per avere dei risultati statisticamente più significativi. I risultati sono riassunti tabellarmente nella figura sottostante:
Figura
Dai risultati in tabella, abbiamo deciso di addestrare la rete con un numero di epoche pari a 15 che da un lato ci da' un errore risultante dalla cross-validation pari a 0.145 (quindi più che accettabile) e dall'altro riteniamo che ci copra dal rischio di overtraining; infatti guardando la figura 8 si può vedere che a 15 epoche il TTS ha da poco raggiunto un errore percentuale pari a 0% e il fatto che ci si stabilizzi supponiamo sia dato dal fatto che TTS e TS sono molto simili tra loro e che per questo l'effetto dell'overtraining non sia visibile con un numero limitato di epoche.
Andando a visualizzare graficamente la rete neurale con tali parametri definitivi si è anche visto che l'errore commesso per epoca è di circa 0,05%, una soglia accettabile per non rischiare un'eccessiva specializzazione.
Si noti che anche la suddivisione scelta in 80% per il TS e 20% per il TTS è la migliore tra quelle provate: questo perché andando a diminuire la percentuale di campioni per il TS è necessario un numero maggiore di epoche per un addestramento migliore.
|
Capitolo |
VALUTAZIONE DEL COSTO DI CLASSIFICAZIONE
La valutazione del costo di classificazione viene effettuata con la tecnica MRC spiegataci in classe e in particolare questa è stata implementata tramite il nodo Cost.
Per ricavare la stima del costo di classificazione abbiamo effettuato diverse esecuzioni senza specificare i seed dello shuffle e del partitioner sul ramo TTS della rete finale, quindi resettando ogni volta i nodi dallo shuffle in poi. I risultati ottenuti sono i seguenti:
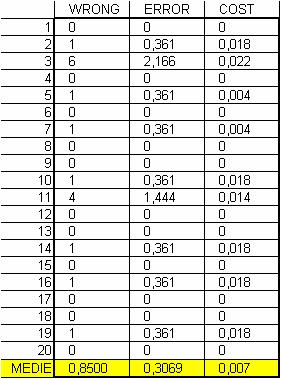
Come costo di classificazione da fornire pensiamo sia ragionevole fornire una media dei costi ottenuti nella tabella di sopra e quindi il COSTO STIMATO = 0.007
|
Appendice A |
SPUNTI DI RIFLESSIONE
Dopo aver eseguito i test per la valutazione dei costi si è verificato un caso 'strano': l'errore di classificazione più frequente, eccetto i casi di rigetto, è una misprediction di un campione WT per YQA, in particolare dei campioni con RowID pari a 190 o 191 (trovati tramite un doppio filtraggio sull'attributo Class con il valore WT e sull'attributo Winner con il valore YQA).
Per risolvere questa misprediction, lasciando invariate le caratteristiche principali della rete finale, abbiamo provato a trovare un insieme di features che discriminasse meglio le due classi. Per fare ciò abbiamo costruito una rete che filtri dapprima i campioni delle due classi e successivamente su tale set abbiamo effettuato una selezione delle features discriminanti.
Applicando un Evaluator di tipo Wrapper Subset Eval e un algoritmo di ricerca di tipo Rank Search è stata individuata la feature Haral7. Prima di etichettarla come definitiva si è visto graficamente come tale features fosse mutuamente indipendente dalle singole features già selezionate (ma ciò non vuol dire che non possa essere indipendente da una qualsiasi loro combinazione). Ad esempio il grafico corrispondente alle features Haral7 e Haral244 è il seguente:
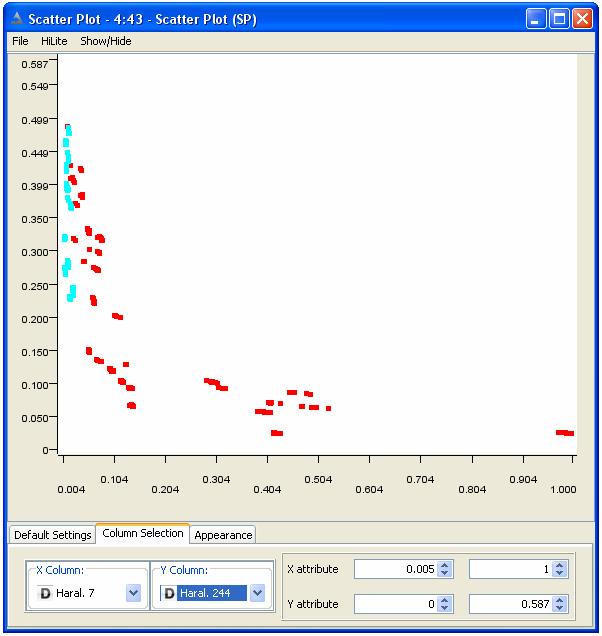
con solo le due classi WT e YQA
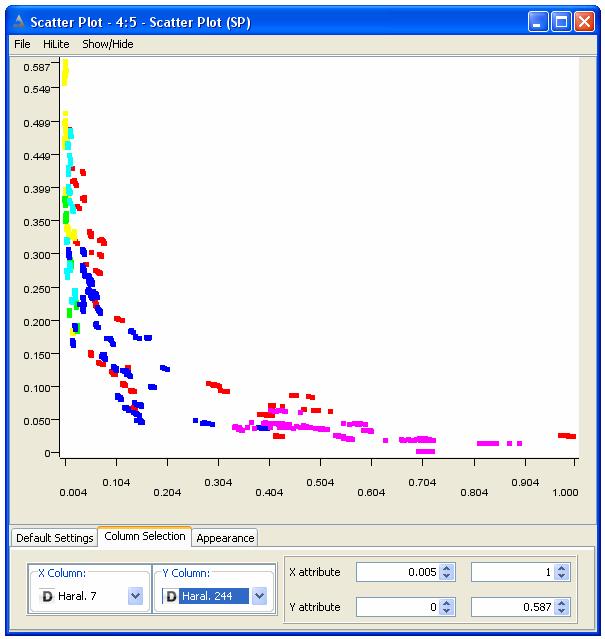
con tutte le classi
mentre, ad esempio, il grafico corrispondente alle features Haral7 e Haral163, che invece sono altamente correlate, è il seguente
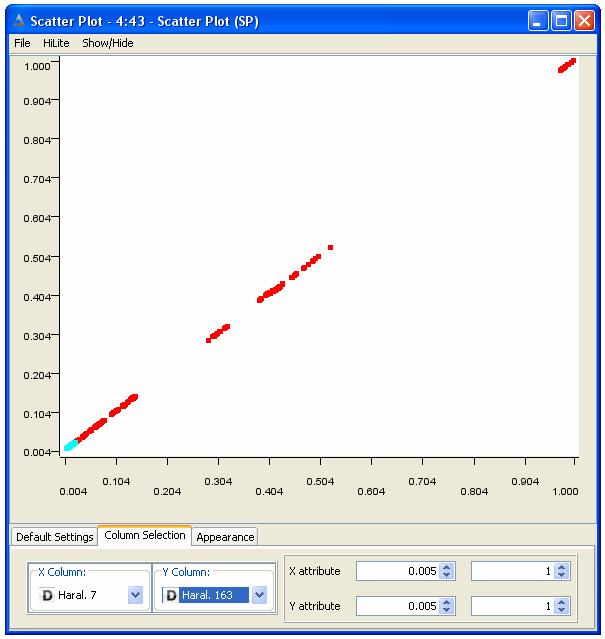
con solo le due classi WT e YQA
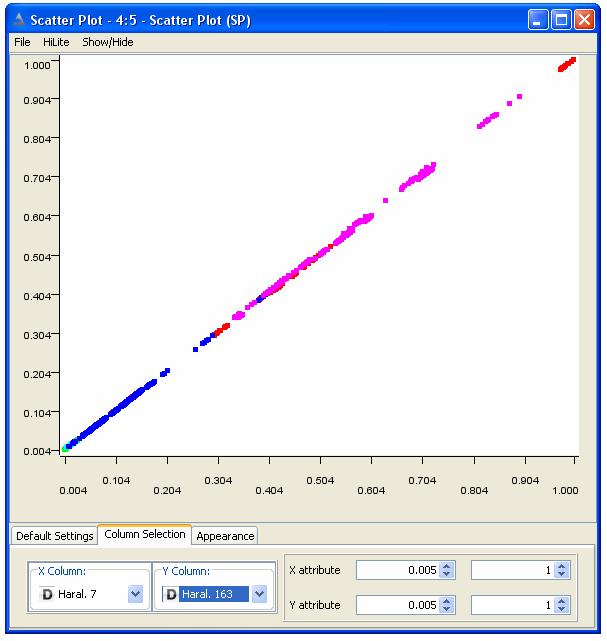
con tutte le classi
Avendo appurato che la feature Haral7 potrebbe essere discriminante abbiamo testato la rete sul nuovo insieme di features ottenuto aggiungendo la nuova feature alle 12 precedenti. I risultati ottenuti sono i seguenti:
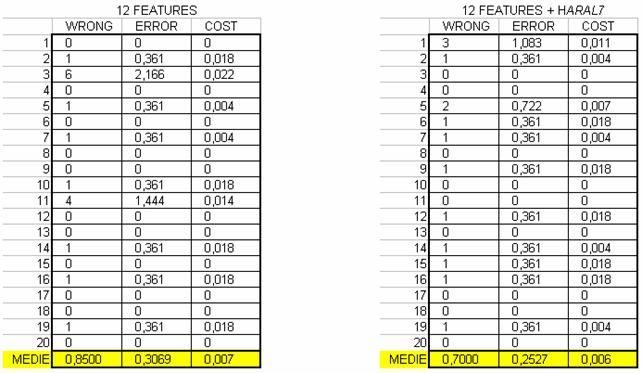
Come si può notare dai risultati la scelta di aggiungere questa nuova feature al set precedente sembra aver migliorato il caso di errore di misprediction anche se sembra non esserci stato un miglioramento notevole infatti su 20 test si è verificato meno frequentemente il caso di corretta classificazione di tutti i campioni (errore sul TTS di 0%). Per avere risultati di maggior precisione si dovrebbe testare meglio la rete, ad esempio facendo variare il numero di neuroni e il numero di epoche.
In definitiva si è scelto di lasciare inalterata la rete precedentemente costituita.
|
| Appunti su: |
|